
computer vision مجال فرعي من deep learning يتعامل مع الصور على جميع المستويات. وهو يسمح للحاسوب بمعالجة وفهم محتوى عدد كبير من الصور عبر عملية تلقائية.
المعمارية الرئيسية وراء Computer vision هي الشبكة العصبية الالتفافية وهي مشتقّ من شبكات feedforward العصبية. تطبيقاتها متنوّعة جدًّا مثل تصنيف الصور، الكشف عن الأشياء، نقل النمط العصبي، التعرّف على الوجوه،… إن لم تكن لديك خلفية عن deep learning بشكل عامّ، أنصحك بقراءة مقالي السابق عن شبكات feedforward العصبية.
ملاحظة: بما أنّ Medium لا يدعم LaTeX، تمّ إدراج التعبيرات الرياضية كصور. لذا أنصحك بإيقاف الوضع الداكن للحصول على تجربة قراءة أفضل.
الملخّص كالتالي:
- معالجة الفلاتر
- التعاريف
- الأسس
- تدريب CNN
- المعماريات الشائعة
معالجة الفلاتر
اعتمدت المعالجة الأولى للصور على فلاتر تسمح، على سبيل المثال، بالحصول على حواف كائن في صورة باستخدام مزيج من فلاتر vertical-edge وhorizontal-edge.
من الناحية الرياضية، يُعرَّف فلتر vertical edge، VEF، على النحو التالي:
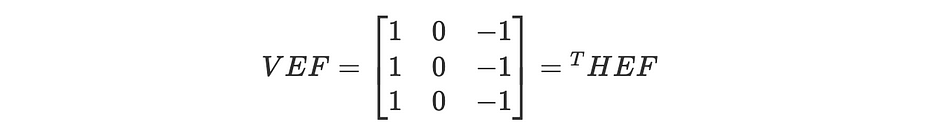
حيث يُشير HEF إلى فلتر horizontal edge.
للتبسيط، ننظر في صورة A مدرّجة الرمادي بحجم 6x6، وهي مصفوفة ثنائية الأبعاد حيث تُمثّل قيمة كلّ عنصر كمّية الضوء في البكسل المقابل.
لاستخراج الحواف العمودية من هذه الصورة، نُجري convolutional product (⋆) الذي هو في الأساس مجموع حاصل الضرب عنصرًا بعنصر في كلّ كتلة:
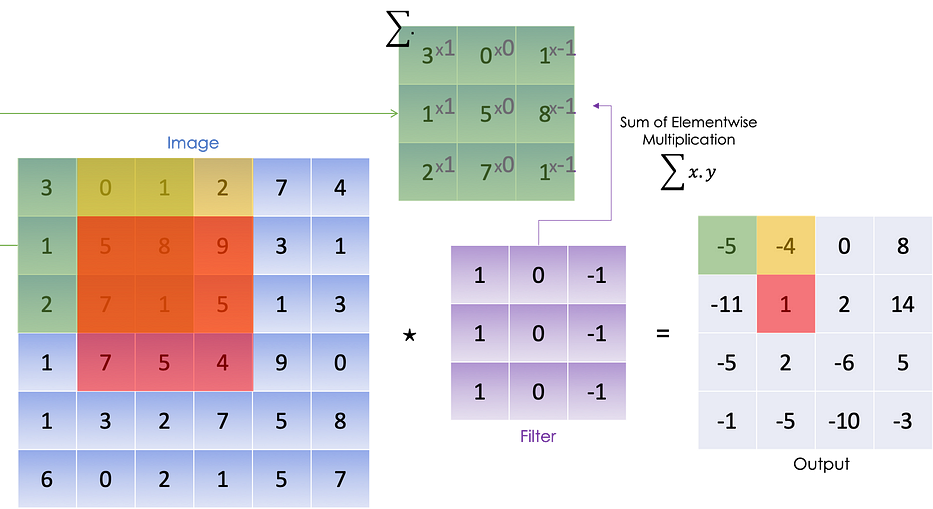
نُجري الضرب عنصرًا بعنصر على أوّل كتلة 3x3 من الصورة، ثمّ نأخذ في الاعتبار الكتلة التالية على اليمين ونفعل الشيء نفسه إلى أن نُغطّي جميع الكتل المحتملة.
يمكننا تلخيص العملية التالية في:

بالنظر إلى هذا المثال، يمكننا التفكير في استخدام العملية نفسها لأيّ any objective حيث يتمّ filter is learned بواسطة neural network على النحو التالي:
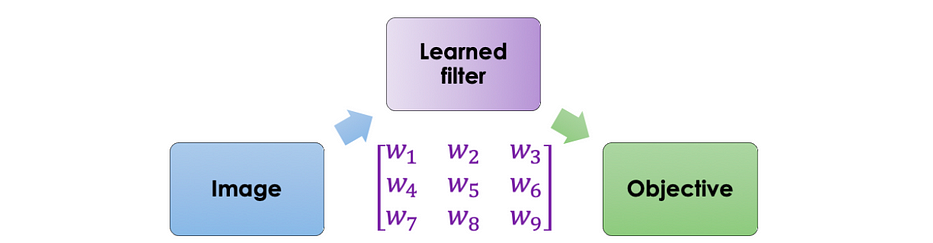
الحدس الرئيسي هو إعداد شبكة عصبية تأخذ الصورة كإدخال وتُخرج هدفًا محدّدًا. تُتعلَّم البارامترات باستخدام backpropagation.
التعريف
الشبكة العصبية الالتفافية هي سلسلة من طبقات الالتفاف وطبقات pooling تسمح باستخراج السمات الرئيسية من الصور التي تستجيب بشكل أفضل للهدف النهائي.
في القسم التالي، سنُفصّل كلّ مكوّن إلى جانب معادلاته الرياضية.
Convolution product
قبل أن نُعرّف convolution product بشكل صريح، سنبدأ أوّلًا بتعريف بعض العمليات الأساسية مثل padding وstride.
Padding
كما رأينا في convolutional product باستخدام فلتر vertical-edge، تُستخدم البكسلات على زاوية الصورة (مصفوفة 2D) أقلّ من البكسلات في وسط الصورة، ممّا يعني أنّ المعلومات من الحواف يتمّ التخلّص منها.
لحلّ هذه المشكلة، نُضيف غالبًا padding حول الصورة لأخذ البكسلات على الحواف بعين الاعتبار. اصطلاحًا، نُضيف padde بـ zeros ونُرمز إلى بارامتر padding بـ p، وهو يُمثّل عدد العناصر المضافة على كلّ من الجوانب الأربعة للصورة.
الصورة التالية توضّح padding لصورة مدرّجة الرمادي (مصفوفة 2D) حيث p=1:
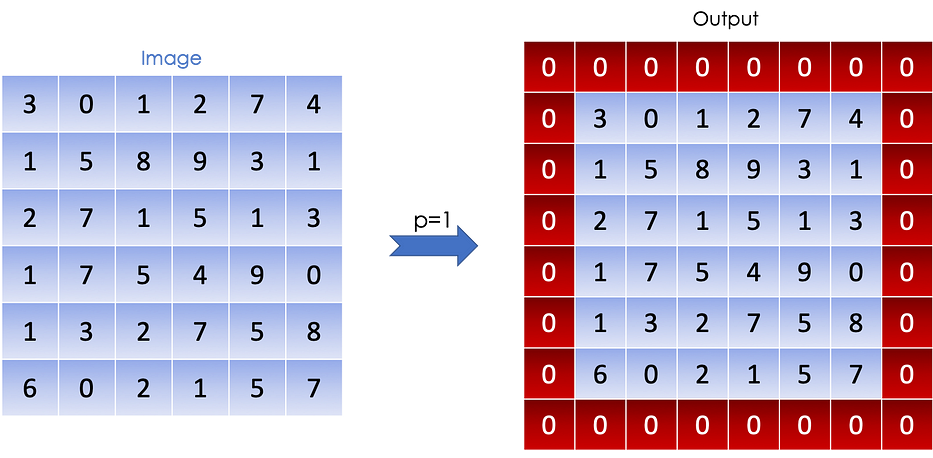
Stride
stride هو الخطوة المُتّخذة في convolutional product. يسمح stride كبير بتقليص حجم الإخراج والعكس صحيح. نُرمز إلى بارامتر stride بـ s.
الصورة التالية توضّح convolutional product (مجموع العناصر عنصرًا بعنصر لكلّ كتلة) بـ s=1:
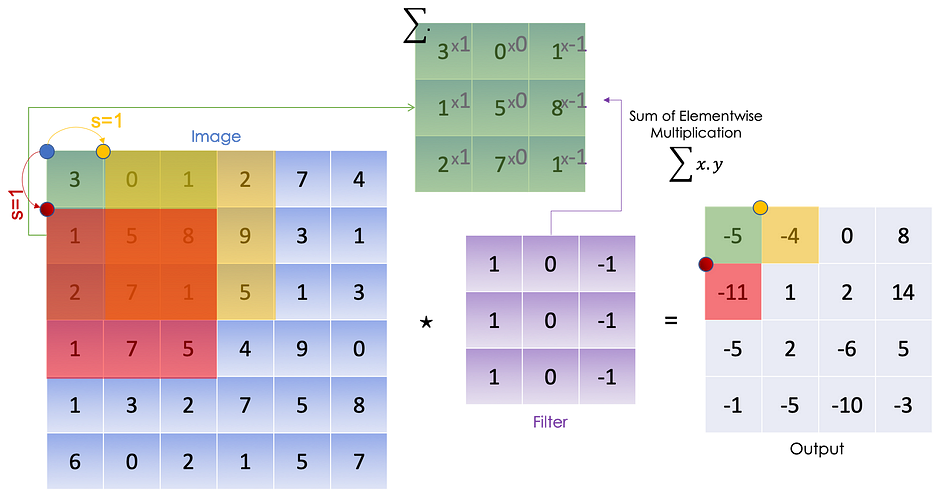
Convolution
بمجرّد تعريف stride وpadding يمكننا تعريف convolution product بين tensor وفلتر.
بعد تعريف convolution product سابقًا على مصفوفة 2D وهو مجموع element-wise product، يمكننا الآن تعريف convolution product على volume بشكل رسمي.
يمكن تمثيل صورة، بشكل عامّ، رياضيًا كـ tensor بالأبعاد التالية:
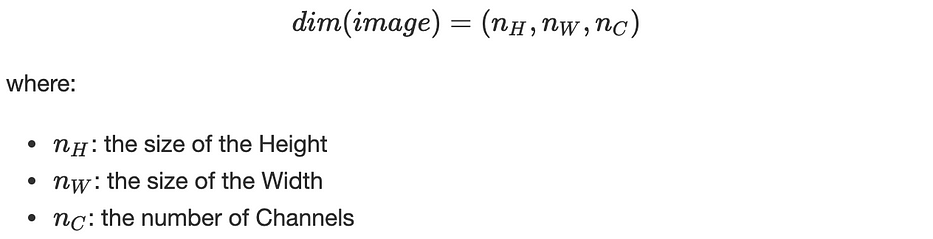
في حالة صورة RGB، مثلًا، n_C=3، لدينا، الأحمر والأخضر والأزرق. اصطلاحًا، نعتبر الفلتر K squared وله odd dimension يُرمز إليه بـ f، ممّا يسمح لكلّ بكسل بأن يكون مركزًا في الفلتر وبالتالي أخذ جميع العناصر حوله بعين الاعتبار.
عند تشغيل convolutional product، يجب أن يكون للفلتر/kernel K same number of channels مثل الصورة، بهذه الطريقة نُطبّق فلترًا مختلفًا على كلّ قناة. وبالتالي يكون بُعد الفلتر كالتالي:
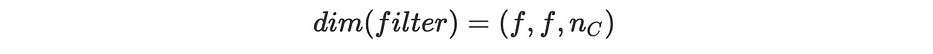
إنّ convolutional product بين الصورة والفلتر هو 2D matrix حيث يكون كلّ عنصر هو مجموع الضرب عنصرًا بعنصر للمكعّب (الفلتر) والمكعّب الفرعي للصورة المُعطاة كما هو موضّح أدناه:
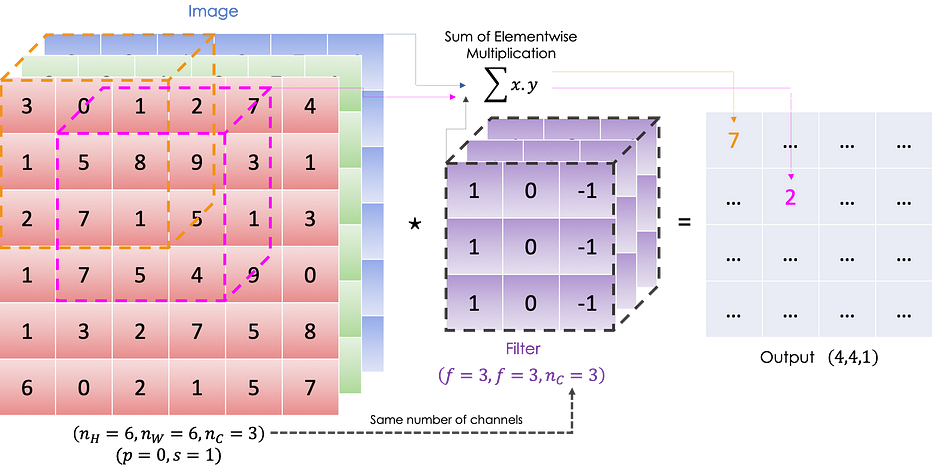
رياضيًا، لصورة وفلتر مُعطَيَين لدينا:
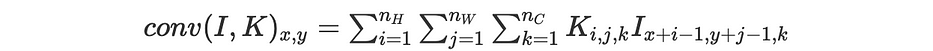
مع الحفاظ على الرموز نفسها كما من قبل، لدينا:

Pooling
هي خطوة downsampling لسمات الصورة بتلخيص المعلومات. تُجرى العملية عبر كلّ قناة وبالتالي تؤثّر فقط على الأبعاد (n_H, n_W) وتُبقي n_C كما هو.
بمعطى صورة، نُمرّر فلترًا، no parameters للتعلّم، باتّباع stride معيّن، ونُطبّق دالّة على العناصر المُختارة. لدينا:
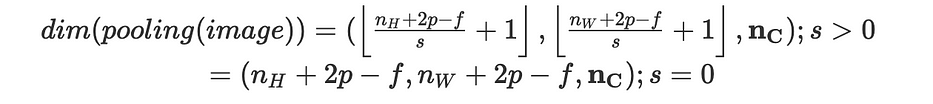
اصطلاحًا، نعتبر فلترًا مربّعًا بحجم f وعادةً ما نضع f=2 ونعتبر s=2.
نُطبّق غالبًا:
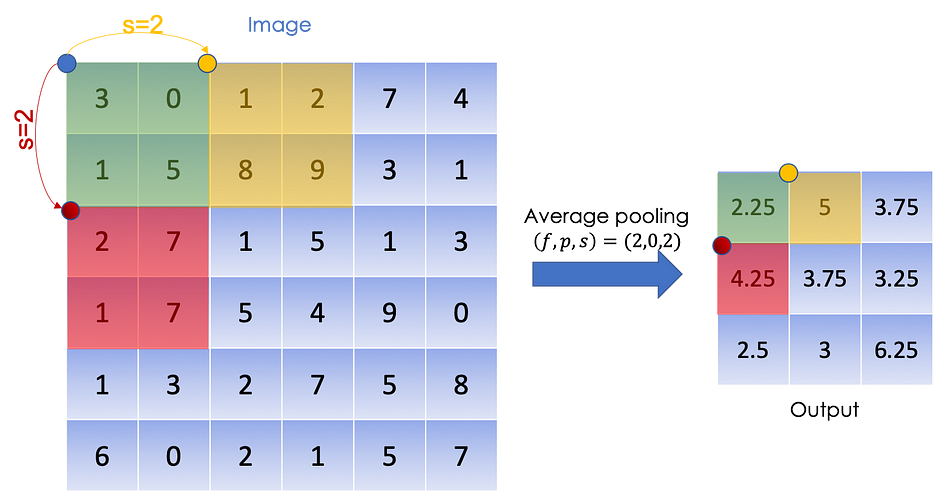
Average pooling: نحسب متوسّط العناصر الموجودة على الفلترMax pooling: بمعطى جميع العناصر في الفلتر، نُعيد القيمة القصوى
أدناه، توضيح لـ average pooling:
الأسس
في هذا القسم، سنُجمّع كلّ العمليات المُعرَّفة أعلاه لبناء شبكة عصبية التفافية، طبقةً تلو الأخرى.
طبقة واحدة من CNN
يمكن أن تكون كلّ طبقة من الشبكة العصبية الالتفافية إمّا:
Convolutional layer -CONV-متبوعة بـactivation functionPooling layer -POOL-كما هو مفصّل أعلاهFully connected layer -FC-طبقة مشابهة في الأساس لطبقة من شبكة عصبية feedforward،
يمكنك الاطلاع على مزيد من التفاصيل حول دوال التنشيط والطبقة fully connected في منشوري السابق.
• Convolutional layer
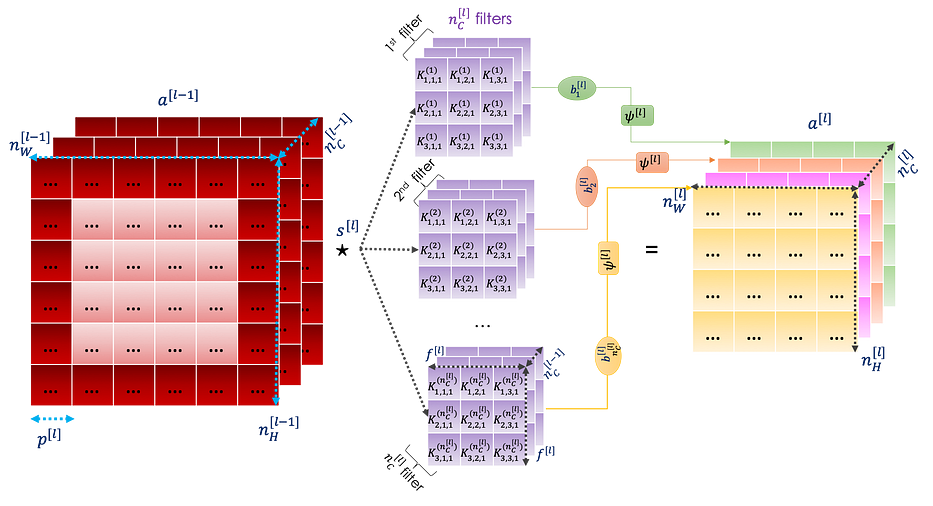
كما رأينا من قبل، في الطبقة convolutional، نُطبّق convolutional products، باستخدام عدّة فلاتر هذه المرّة، على الإدخال متبوعًا بدالّة تنشيط ψ.

يمكننا تلخيص طبقة convolutional في الرسم البياني التالي:
• Pooling layer
كما ذُكر سابقًا، تهدف طبقة pooling إلى downsampling سمات الإدخال دون التأثير على عدد القنوات.
نعتبر التدوين التالي:
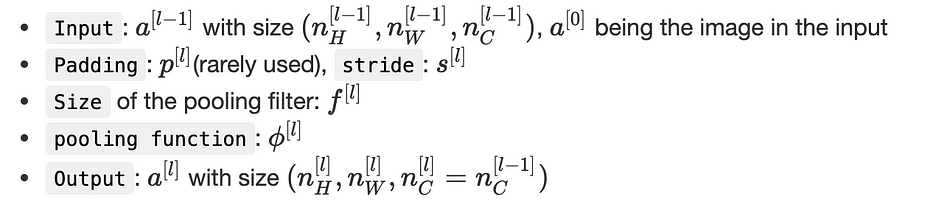
يمكننا التأكيد بأنّ:
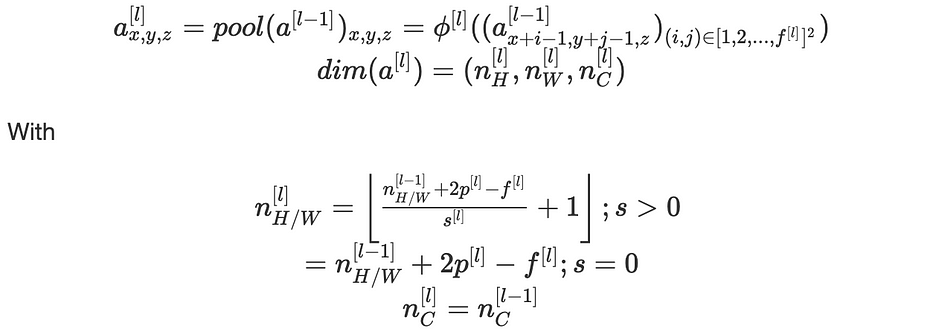
طبقة pooling ليس لديها no parameters للتعلّم.
نُلخّص العمليات السابقة في التوضيح التالي:
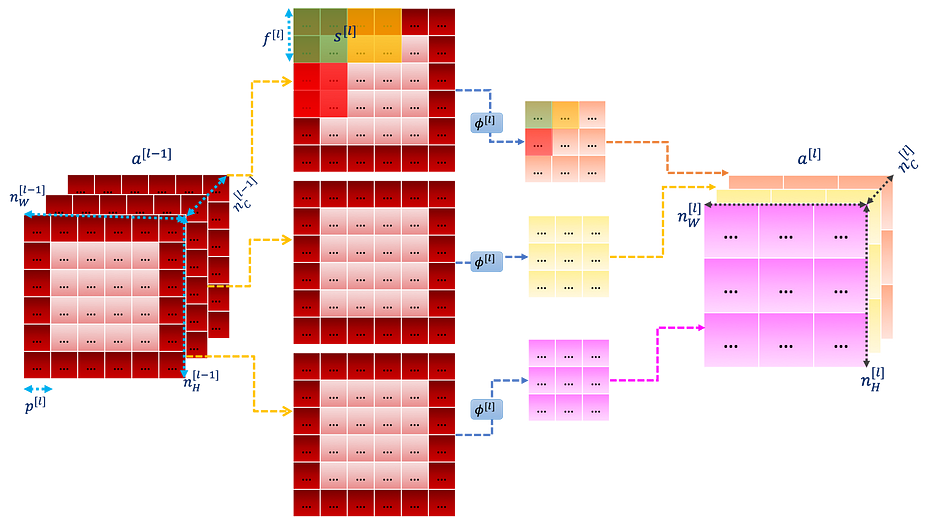
• Fully connected layer
طبقة fully connected هي عدد محدود من الخلايا العصبية التي تأخذ كإدخال متّجهًا وتُعيد آخر.

نُلخّص طبقة fully connected في التوضيح التالي:
لمزيد من التفاصيل، يمكنك زيارة مقالي السابق عن شبكات feedforward العصبية.
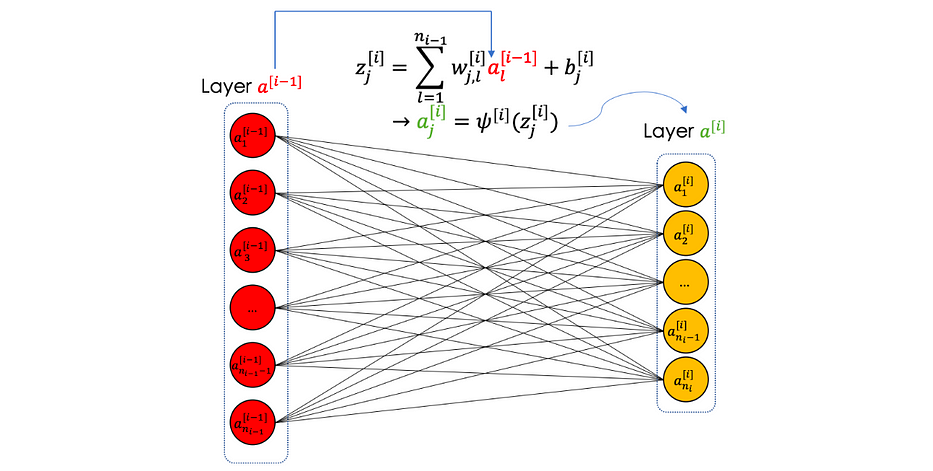
CNN بشكل عامّ
بشكل عامّ، الشبكة العصبية الالتفافية هي سلسلة من جميع العمليات الموصوفة أعلاه على النحو التالي:
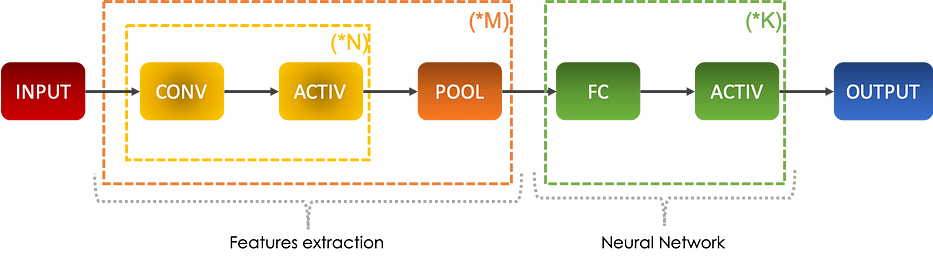
بعد تكرار سلسلة من convolutions متبوعة بدوال التنشيط، نُطبّق pooling ونُكرّر هذه العملية عددًا معيّنًا من المرّات. تسمح هذه العمليات بـ extract features من الصورة التي ستُمرَّر fed إلى neural network موصوف بطبقات fully connected متبوعة بانتظام بدوال التنشيط أيضًا.
الفكرة الرئيسية هي decrease n_H وn_W وincrease n_C عند التعمّق في الشبكة.
في 3D، الشبكة العصبية الالتفافية لها الشكل التالي:
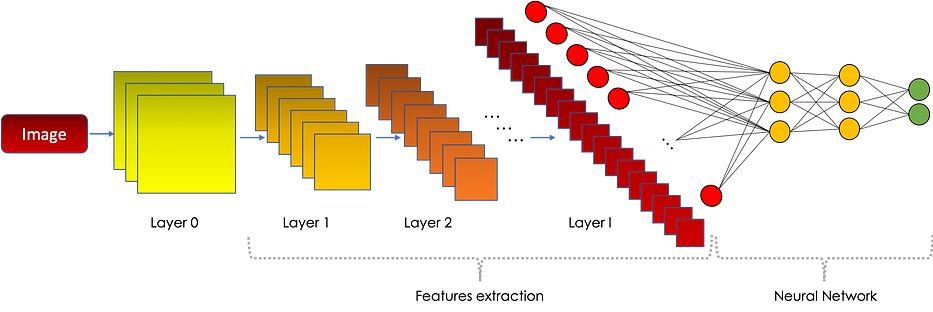
لماذا تعمل CNN بكفاءة؟
تُمكّن الشبكات العصبية الالتفافية من تحقيق أحدث النتائج في معالجة الصور لسببَين رئيسيَّين:
- Parameter sharing: مكشاف سمات في طبقة convolutional مفيد في جزء من الصورة، قد يكون مفيدًا في أجزاء أخرى
- Sparsity of connections: في كلّ طبقة، تعتمد كلّ قيمة إخراج فقط على عدد صغير من المدخلات
تدريب CNN
تُدرَّب الشبكات العصبية الالتفافية على مجموعة من الصور الموسومة. انطلاقًا من صورة مُعطاة، نُمرّرها عبر الطبقات المختلفة لـ CNN ونُعيد الإخراج المطلوب.
في هذا الفصل، سنتطرّق إلى خوارزمية التعلّم إلى جانب التقنيات المختلفة المستخدمة في data augmentation.
المعالجة المسبقة للبيانات
Data augmentation هي خطوة زيادة عدد الصور في dataset مُعطى. هناك العديد من التقنيات المُستخدمة في data augmentation مثل:
CroopingRotationFlippingNoise injectionColor space transformation
تُتيح better learning بفضل الحجم الأكبر لمجموعة التدريب وتسمح للخوارزمية بالتعلّم من conditions مختلفة للكائن المعني.
بمجرّد أن يصبح dataset جاهزًا، نُقسّمه إلى ثلاثة أجزاء كأيّ مشروع machine learning:
- Train set: تُستخدم لتدريب الخوارزمية وبناء batches
- Dev set: تُستخدم لضبط الخوارزمية وتقييم الانحياز والتباين
- Test set: تُستخدم لتعميم الخطأ/الدقة للخوارزمية النهائية
خوارزمية التعلّم
الشبكات العصبية الالتفافية نوع خاصّ من الشبكات العصبية المتخصّصة في الصور. التعلّم في الشبكات العصبية، بشكل عامّ، هو خطوة حساب أوزان البارامترات المُعرَّفة أعلاه في عدّة طبقات.
وبعبارة أخرى، نهدف إلى إيجاد أفضل البارامترات التي تُعطي أفضل تنبّؤ/تقريب، انطلاقًا من صورة الإدخال، للقيمة الحقيقية.
لذلك، نُعرّف دالّة هدف تُسمّى loss function ويُرمز إليها بـ J تُكمّم المسافة بين القيم الحقيقية والمتنبّأ بها على مجموعة التدريب الكاملة.
نُصغّر J باتّباع خطوتَين رئيسيتَين:
Forward Propagation: نُمرّر البيانات عبر الشبكة إمّا كاملةً أو على دفعات، ونحسب loss function على هذه الدفعة وهي ليست إلّا مجموع الأخطاء المرتكبة عند الإخراج المتنبّأ به للصفوف المختلفة.Backpropagation: تتمثّل في حساب gradients لدالّة التكلفة بالنسبة للبارامترات المختلفة، ثمّ تطبيق خوارزمية انحدار لتحديثها.
نُكرّر العملية نفسها عددًا من المرّات يُسمّى epoch number. بعد تعريف المعمارية، تُكتب خوارزمية التعلّم على النحو التالي:

(*) تُقيّم دالّة التكلفة المسافات بين القيمة الحقيقية والمتنبّأ بها عند نقطة واحدة.
لمزيد من التفاصيل، يمكنك زيارة مقالي السابق عن شبكات feedforward العصبية.
المعماريات الشائعة
Resnet
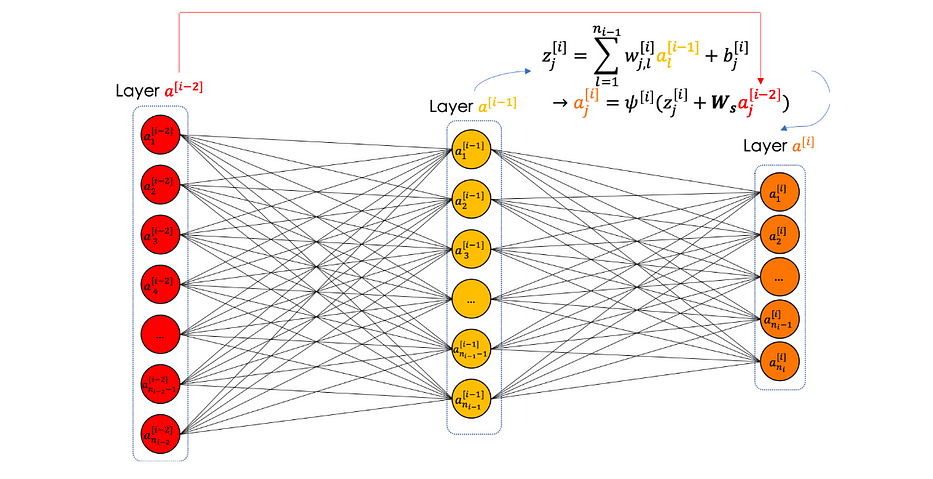
Resnet أو short cut أو skip connection هو طبقة التفافية تأخذ في الاعتبار الطبقة n-2 عند الطبقة n. يأتي الحدس من حقيقة أنّه عندما تصبح الشبكات العصبية عميقة جدًّا، تصبح الدقّة عند الإخراج مستقرّة جدًّا ولا تزداد. يساعد حقن residuals من الطبقة السابقة على حلّ هذه المشكلة.
لننظر في كتلة residual، عندما يكون skip connection off، لدينا المعادلات التالية:

يمكننا تلخيص كتلة residual في التوضيح التالي:
Inception Networks
عند تصميم شبكة عصبية التفافية، علينا غالبًا اختيار نوع الطبقة: CONV، POOL أو FC. تقوم طبقة inception بها جميعها. ثمّ تُربط نتيجة جميع العمليات concatenated في كتلة واحدة ستكون إدخال الطبقة التالية على النحو التالي:
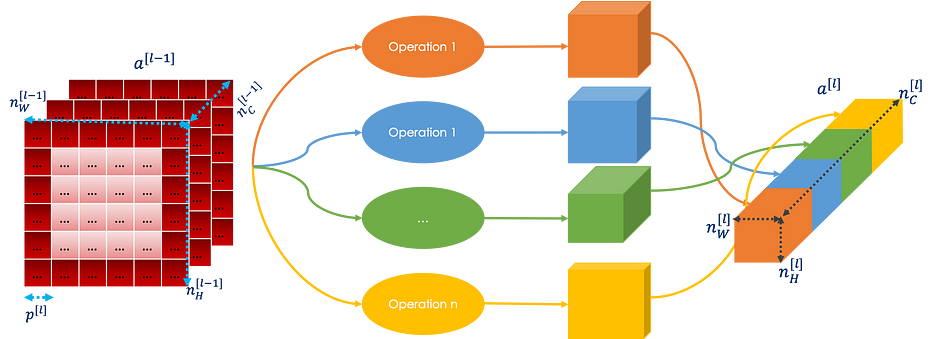
من المهمّ ملاحظة أنّ طبقة inception تُثير مشكلة computational cost. للمعلومية، الاسم inception مأخوذ من الفيلم!
الخاتمة
في الجزء الأوّل من هذا المقال، رأينا أساسيات CNN من convolutional products، طبقات pooling/fully connected إلى خوارزمية التدريب.
في الجزء الثاني، سنناقش بعض أشهر المعماريات المستخدمة في معالجة الصور.
لا تتردّد في الاطلاع على مقالاتي السابقة التي تناقش:
المراجع
- Deep Learning Specialization, Coursera, Andrew Ng
- Machine Learning, Loria, Christophe Cerisara