
تواجه كثير من الشركات في وقتنا الحاضر معالجة حالات متشابهة ضمن نشاطها. وقليلٌ منها يستفيد من العمل السابق والقديم، بينما تعيد الغالبية الكبرى منها كل شيء من جديد.
في هذا المقال، سنكتشف كيف يمكن الاستفادة من خوارزميات الـ AI لبناء matching engine قادر على استخدام متغيرات نصية وفئوية ورقمية على حدّ سواء.
من باب التبسيط، سنفترض أنّ الحالة تُوصف بالبيانات التالية:
- Num: متغيّر رقمي
- Categ: متغيّر فئوي (كلمة واحدة)
- Sent: متغيّر نصي (جملة واحدة - يتطلّب embedding)
- Parag: متغيّر نصي (فقرة - تتطلّب embedding)
إذا كانت قاعدة بياناتك لا تتّبع البنية ذاتها، فيمكنك تطبيق preprocessing pipeline للوصول إلى السيناريو نفسه.
الملخّص كالتالي:
- Embeddings
- التشابهات
- Matching engine
Embeddings
Word embedding
إنّ الـ word embedding هو فنّ تمثيل كلمة في فضاء شعاعي بحجم N حيث تكون الكلمات المتشابهة دلالياً، رياضياً، قريبة من بعضها البعض.
وهي خطوة مهمّة عند التعامل مع البيانات النصية بما أنّ خوارزميات الـ ML تعمل في معظمها بالقيم العددية.
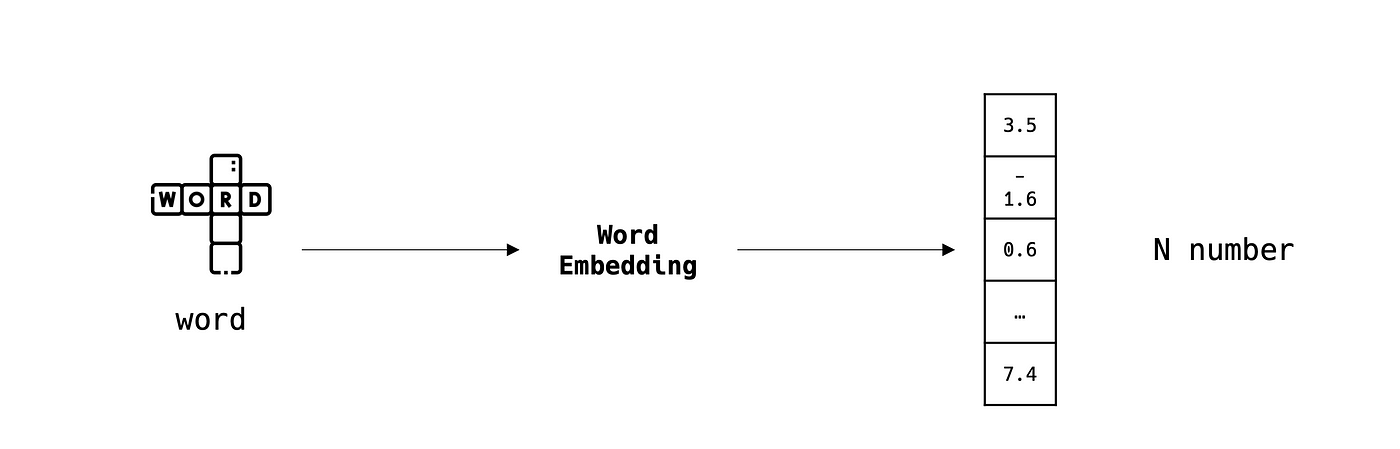
توجد العديد من خوارزميات الـ word embedding مثل Word2Vec وFastText وBERT، …، ولها العديد من التكييفات في لغات مختلفة.
Sentence Embedding
الجملة هي تسلسل من الكلمات. وبناءً على ذلك، يمكننا تجميع embeddings الكلمات لتوليد embedding الجملة وفق الخطوات أدناه:
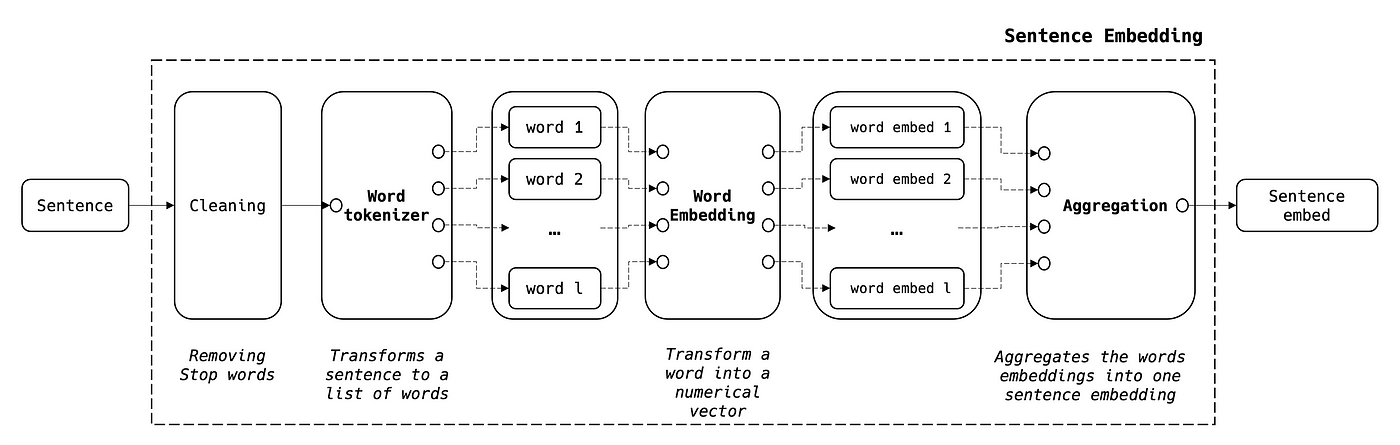
حيث:
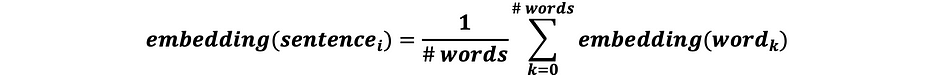
- NB1: في مرحلة التنظيف، يمكننا الاحتفاظ فقط بالكلمات المفتاحية ليتمّ embedding لها
- NB2: الصيغة المُجمَّعة تسمح بتحقيق التوازن بين الجمل الطويلة والقصيرة
- NB3: حجم embedding الجملة هو نفسه حجم embedding الكلمة N
Paragraph Embedding
يمكننا اتباع المقاربة ذاتها أعلاه باعتبار أنّ الفقرة هي تسلسل من الجمل:
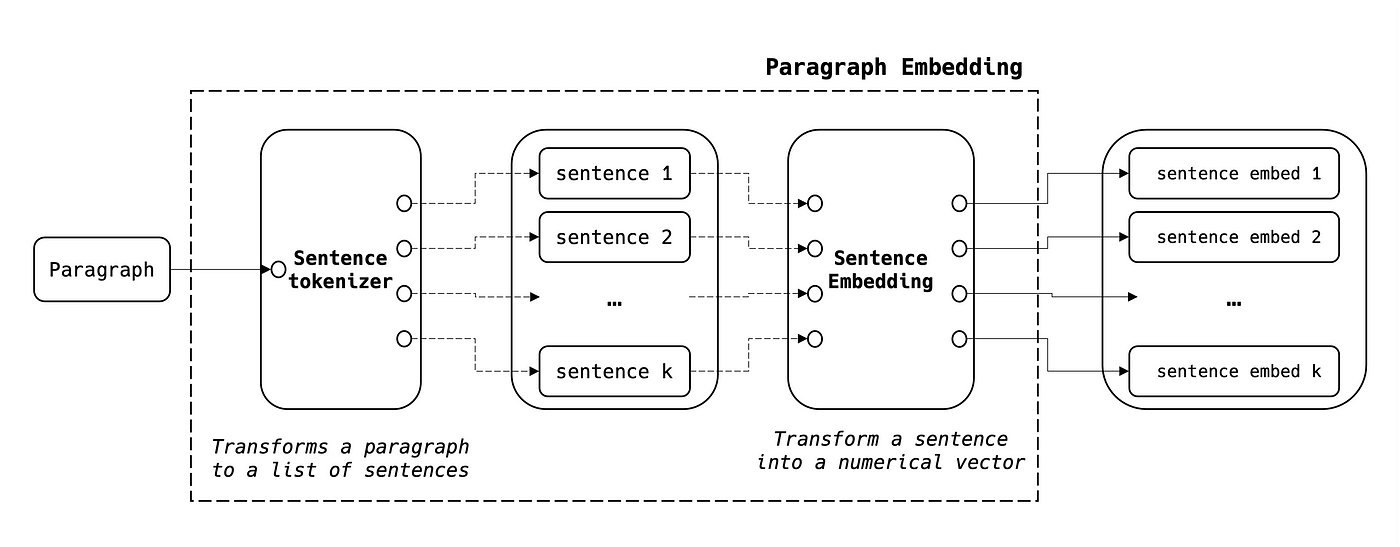
- NB1: في الاستخدام الشائع، تُفصل الجمل غالباً باستخدام السلسلة " . "، ولكن قد يلزم تخصيص ذلك في بعض الحالات.
- NB2: حجم embedding الفقرة هو (N، k) حيث N هو حجم embedding الجملة وk هو عدد الجمل داخل الفقرة.
التشابه
التشابهات الرقمية
لنعتبر قيمتين رقميتين x و y، ويُعرَّف NumSim، أي المسافة بينهما، كما يلي:
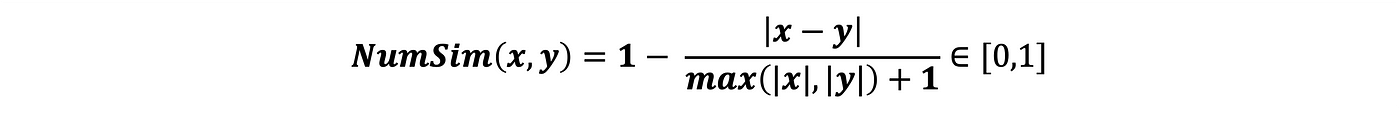
إذا:
- x=y => NumSim(x,y)=1
- x>>y => NumSim(x,y)≈1/(|x|+1)≈0
تشابهات الكلمات
توجد عدّة طرق لحساب التشابه بين كلمتين، ونذكر أدناه اثنتين من أشهر المقاربات:
- Approximate string matching (مبنيّ على الحروف): Levenshtein’s distance، …
- Semantic string matching (مبنيّ على الـ Embedding): Cosine similarity، Euclidian distance، …
في هذا المقال، سنركّز بشكل رئيسي على الـ cosine similarity وهي ليست سوى جيب تمام الزاوية بين شعاعَي الـ embedding للكلمتين المُقارَنتين:
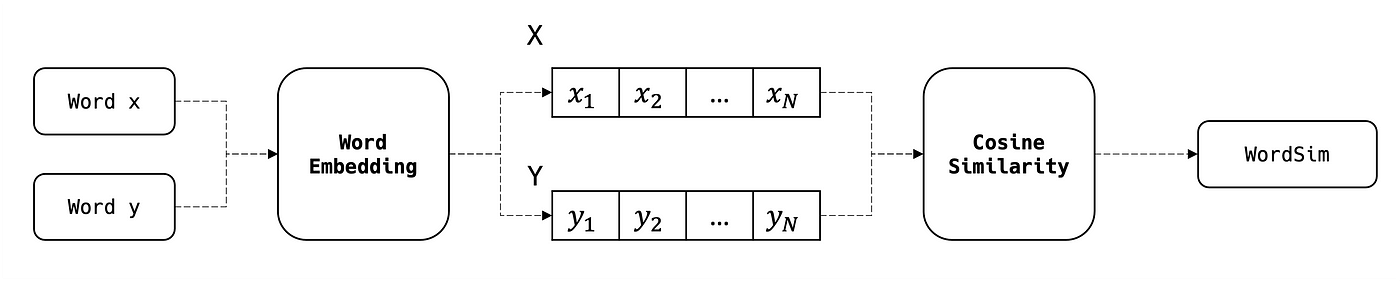
حيث:
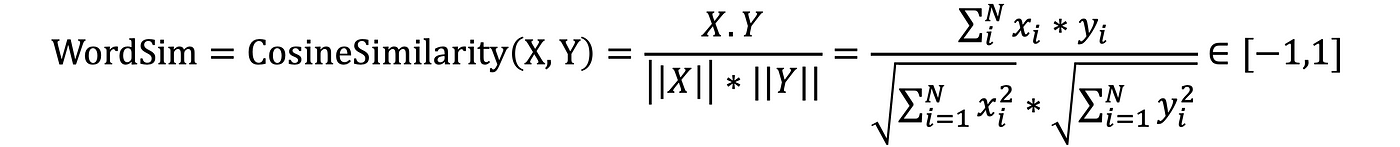
تشابهات الجمل
نتّبع المقاربة ذاتها مستخدمين هذه المرة خوارزمية sentence embedding المعرَّفة أعلاه:

حيث:

تشابهات الفقرات
تشابهات الفقرات أكثر تعقيداً نوعاً ما لأنّ embeddings الخاصة بها تُعتبر مصفوفات ثنائية الأبعاد بدلاً من أشعّة. لمقارنة فقرتين، نحسب SentSim لكلّ زوج من الجمل ونولّد مصفوفة تشابه ثنائية الأبعاد تُجمَّع بعد ذلك في درجة واحدة:
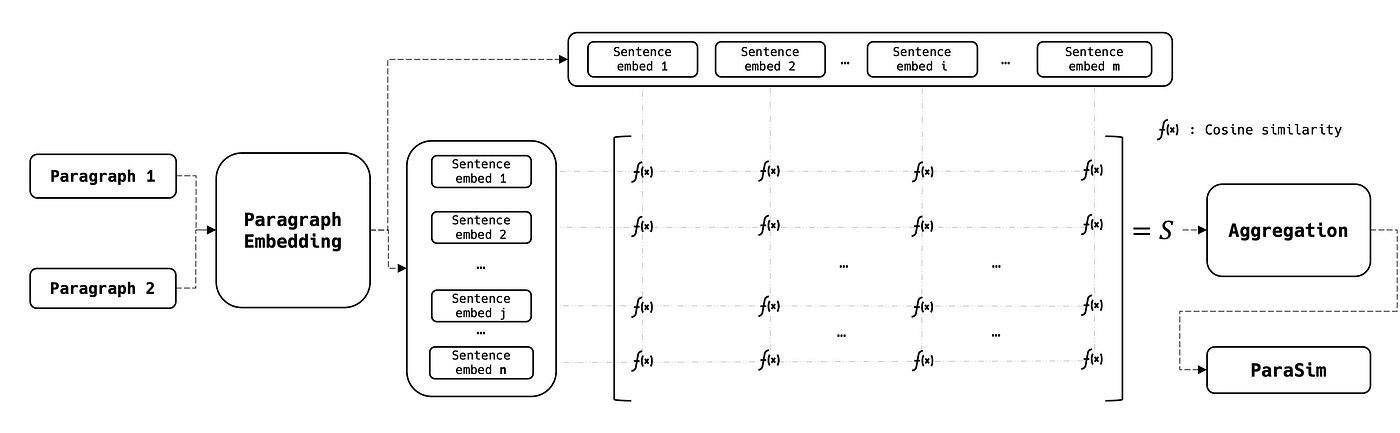
حيث:

Matching Engine
كما ذُكر سابقاً، لنفترض حالة عمل علينا فيها التعامل مع معالجة حالات كثيرة. تُوصف كلّ حالة بأربعة متغيرات: Num وCateg وSent وParag (انظر المقدمة).
يمكننا الاستفادة من البيانات التاريخية لمقارنة كل حالة جديدة مع قاعدة البيانات بأكملها واختيار الحالات الأكثر تشابهاً باستخدام المخطّط التالي:
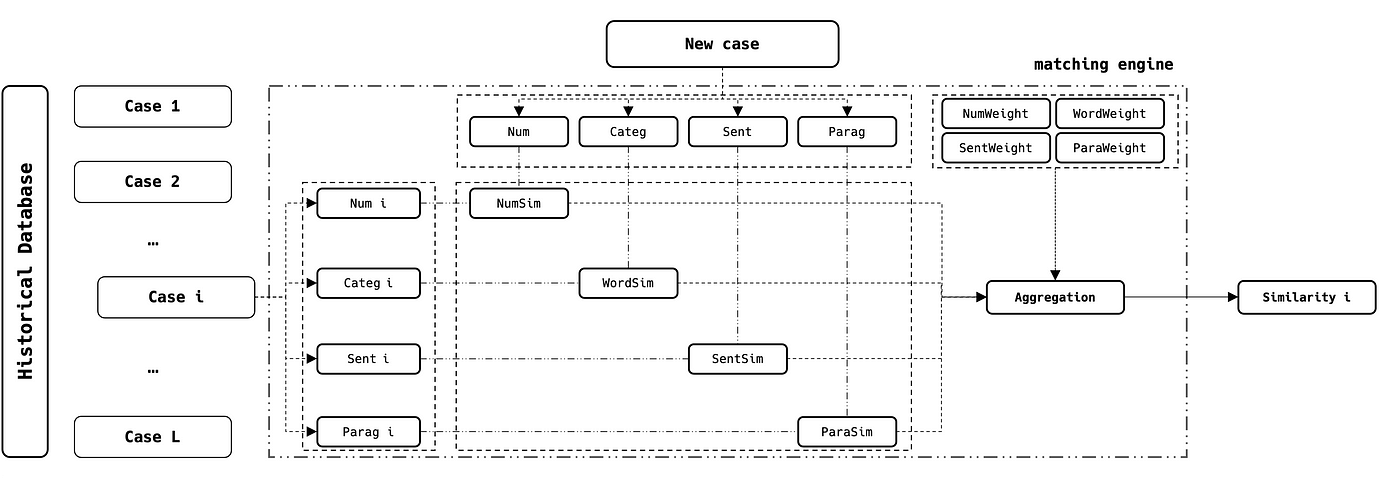
حيث:
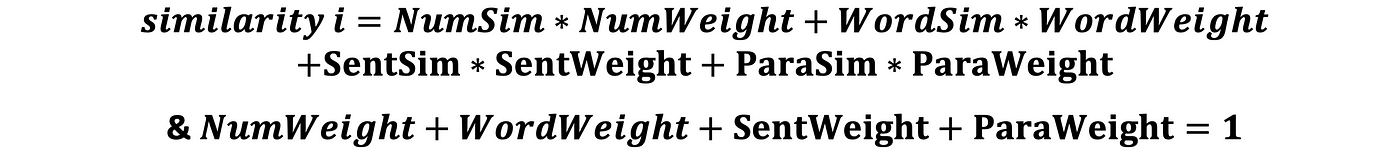
نُجري هذه العمليات على كل الحالات من 1 إلى L (وهو حجم قاعدة البيانات) ونُخرج أعلى درجات المطابقة.
- NB1: إذا كان للمتغيّر Categ طرائق فريدة وثابتة، يمكننا استبدال المطابقة بـ filtering بسيط
- NB2: إذا كان لديك أكثر من متغيّر واحد لكل نوع، فيمكنك تكديسها في المحرّك ذاته باستخدام مقاربة التشابه الصحيحة
- NB3: يُختار وزن كلّ متغيّر بناءً على أولوّيته وأهمّيته العملية
الخاتمة
تحظى الـ matching engines بشعبية واسعة وتُستخدم بكثرة في عالم التقنية. فهي تتيح للشركات أدوات معالجة أسرع تساعد في تحقيق مكاسب زمنية ومالية.
في هذا المقال، ركّزنا على نوع معيّن من المدخلات (الرقمية والنصية)، ولكن يمكنك أيضاً تخيّل امتلاك صورة كوصف إضافي لحالتنا. وهذا يستدعي استخدام تقنيات CNN مثل Siamese networks التي تولّد embedding للصورة يُستخدم مع cosine similarity لتوليد درجة مطابقة إضافية.