
تُعدّ خطوط أنابيب RAG، أي Retrieval Augmented Generation، من أشهر تطبيقات الـ LLMs وأكثرها رواجاً في الوقت الراهن، والفكرة الأساسية هي الإجابة عن سؤال انطلاقاً من مصدر واحد أو عدة مصادر للمعلومات (PDF، Excel، Drive، SharePoint، …) عبر الاستفادة من قدرات الاستدلال لدى الـ large language model الذي تكون معرفته محدودة بتاريخ معيّن.
يمكن أن يكون السؤال:
- موضوعياً: صحيح-خطأ، اختيار من متعدد، كلمات أو أرقام محدّدة …، ويُستخدم بشكل رئيسي في خطوط استخراج النقاط الجوهرية.
- ذاتياً: فقرة قصيرة ومفصّلة تُستخدم في حالات الأسئلة والأجوبة العامة
في هذا المقال، سنستعرض الخطوات المختلفة لبناء RAG pipeline بسيط ثم تعزيزه عبر إضافة وحدات مرتبطة بكلٍّ من الـ retriever والـ generator (انظر القسم التالي).
في المقال التالي، سنتناول تقييم خط الأنابيب RAG وفق منهجية TDD (Test Driven Development) وMDD (Metric Driven Development).
الملخّص كالتالي:
- RAG Pipeline
- التعزيز
RAG Pipeline
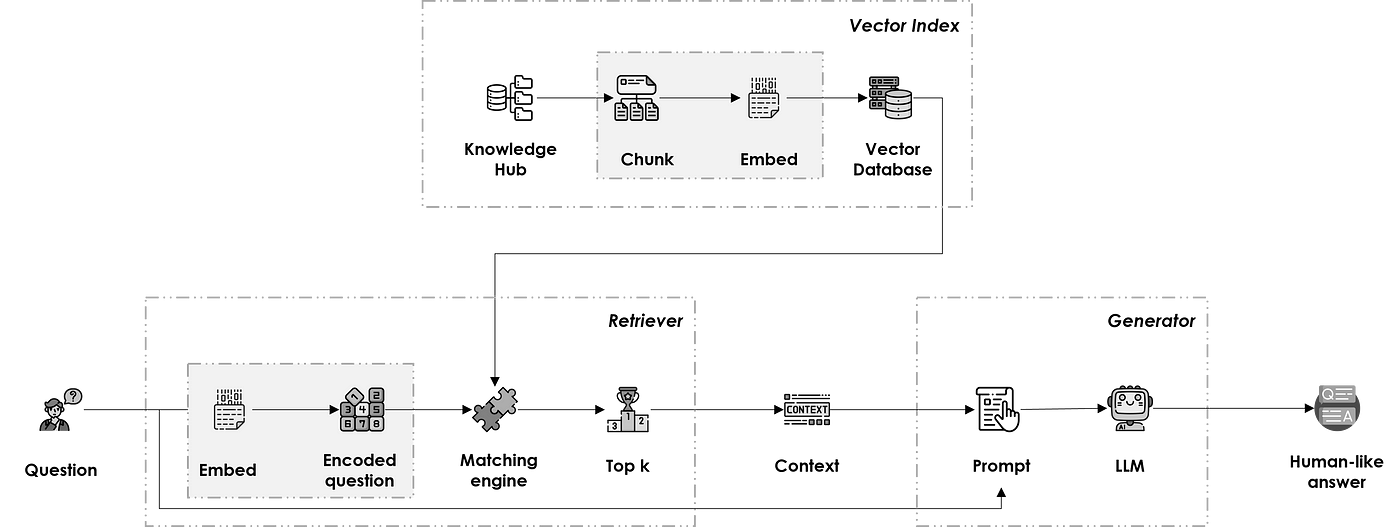
يتكوّن الـ RAG pipeline من ثلاثة مكوّنات رئيسية: Vector Index وRetriever وGenerator.
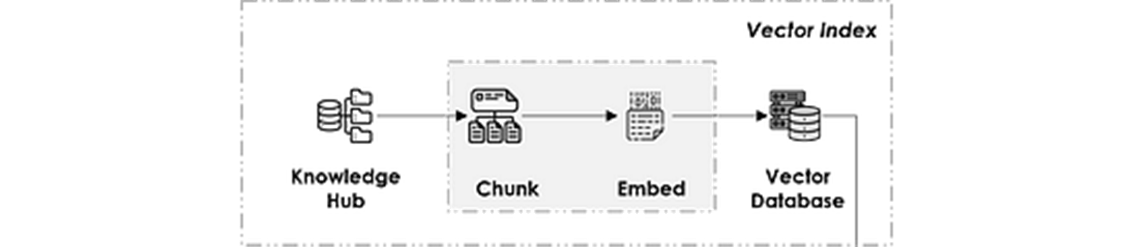
Vector Index
يمثّل مركز المعرفة الذي تُسحب منه المعلومات، ويُبنى وفق الخطوات التالية:
- جمع البيانات
- تنظيف البيانات: وفق المبدأ البسيط "garbage in, garbage out"
- تقسيم البيانات: تقسيم البيانات إلى أقسام صغيرة (بحسب الصفحة/الفقرة مثلاً) لأنّ الـ LLM لا يستطيع استيعاب سوى عدد محدّد من الـ tokens يُعرف بحجم الـ context.
- تضمين البيانات: ويحوّل النص إلى تمثيل دلالي شعاعي للمطابقة لاحقاً باستخدام embedding model (يُعدّ Openai ada-002 الأشهر بينها).
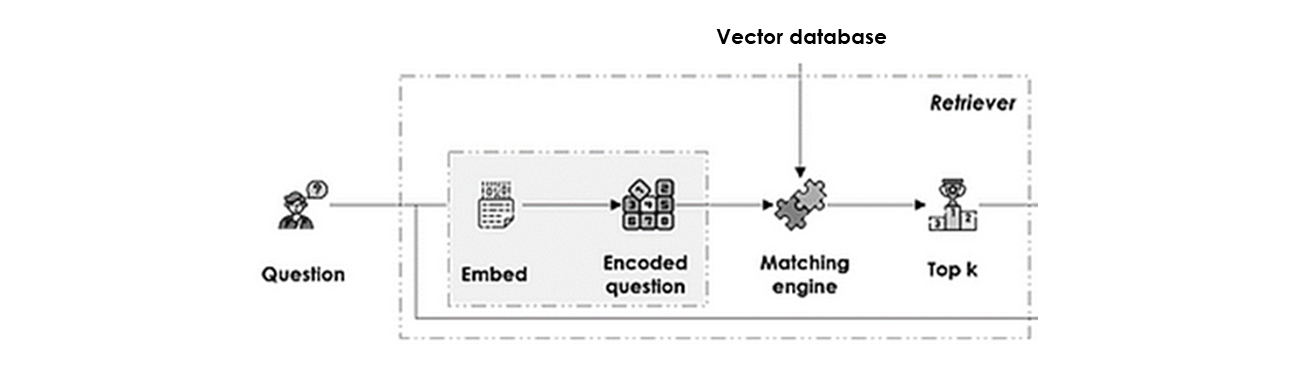
Retriever
يطابق السؤال مع المقطع المناسب من مركز المعرفة من خلال:
- ترميز السؤال: لتمثيل السؤال في الفضاء الشعاعي ذاته الخاص ببيانات المصدر باستخدام نفس الـ embedding model.
- المطابقة الدلالية: بين embedding السؤال والـ vector index، باستخدام مقياس cosine similarity مثلاً، وإرجاع أعلى k من السياقات الأكثر تشابهاً.
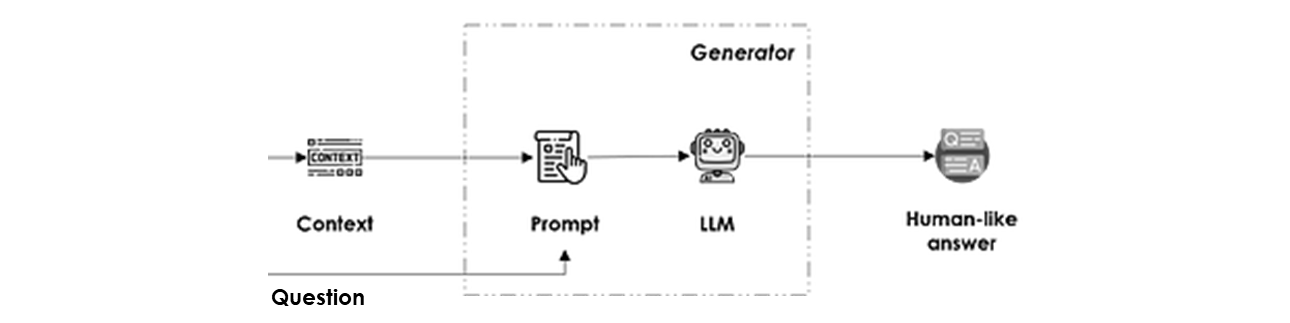
Generator
يُرجع إجابة شبيهة بإجابة البشر عن السؤال استناداً إلى السياق المختار في خطوتين متتاليتين:
- توليد الـ prompt: تقوم هذه الخطوة على إنشاء مجموعة من التعليمات للاستفادة الكاملة من قدرات الاستدلال لدى الـ LLM من خلال التحديد الصريح للسؤال والسياق الذي ينبغي استخراج المعلومة منه. كما تُستخدم لتحديد نبرة/أسلوب اللغة المولّدة بالإضافة إلى الصيغة المتوقّعة للمخرج (text، json، yaml، …).
يمكننا أيضاً إضافة آخر n من التفاعلات التاريخية بين المستخدم والنظام في الحوارات الدردشية، شريطة أن تتّسع هذه التفاعلات داخل نافذة الـ context. - LLM completion: أي مخرج استدلال الـ LLM على الـ prompt المُولَّد
التعزيز
قد يعاني الـ RAG pipeline البسيط الموصوف أعلاه من عدة مشاكل: precision/recall منخفض في الاسترجاع، hallucination في الـ generator، …إلخ.
للحدّ من هذه المخاطر، يمكن إضافة عدة خطوات إلى خط الأنابيب من أجل ضمان استرجاع أفضل للمعلومة وتوليد إجابة أدق.
Vector Indexing
- تحليل وحدي: للنصوص والجداول والصور
- تحسين استراتيجية التقسيم: تقسيم مخصّص بحسب القسم والقسم الفرعي…
- تحسين بنية الـ index: بإضافة هرمية
- Metadata إضافية: تصف محتوى الأقسام. والمطابقة على هذه الـ metadata في البداية قد تكون مرشّحاً جيّداً للضوضاء.
Retriever
- إعادة صياغة السؤال: لتصحيح البنية النحوية للسؤال نظراً لأنّ معظم نماذج الـ embedding دُرّبت على بيانات نظيفة. كما يساعد ذلك على محاذاة السؤال مع بنية لغة الـ LLM.
- fine-tuning للـ embedding: ويمكن أن يكون مفيداً جداً عند التعامل مع سياقات متخصّصة بمجال معيّن
- استخدام dynamic embedding: حيث يعتمد الشعاع المُولَّد على التعليمة الإضافية المُعطاة للـ embedding model
- Reranking: مثل Diversity Ranker وLost in the Middle Ranker. وقد أثبتت هذه التقنية فعّاليتها العالية في تعزيز دقة الاسترجاع
- Hybrid Retrieval: BM25 و embedding في حالات الاستخدام التي تكون فيها الكلمات المفتاحية مهمّة
- Prompt compression: حذف الضوضاء من النص المُسترجع والاحتفاظ بجوهر المعلومة المطلوبة من المقطع. وبذلك يُقلَّص حجم الـ context ويُتاح معالجة معلومات أكثر داخل النافذة ذاتها.
التوليد
- Prompt engineering: هو فنّ تطوير prompt يلبّي المستوى المتوقّع من المخرج
- fine-tuning لـ LLMs مفتوحة المصدر: مهمّة ثقيلة تتطلّب بناء dataset (يتألّف عادةً من سؤال وسياق وإجابة) لإجراء fine-tuning على نموذج اللغة المدرَّب. تتيح هذه المنهجية للنموذج التقاط كل من الأسلوب والمعرفة من مجموعة التدريب.
الخاتمة
يُعدّ RAG معماريةً شائعة وقويّة جداً اليوم نظراً لفوائدها الكبيرة. فهي قابلة للتوسعة بسهولة لمعرفة أكبر، وبالتالي التكيّف مع التغييرات المحتملة في الإصدارات القائمة. كما يمكنها التكيّف مع أنواع متعدّدة من البيانات والاستعلامات عبر الاستفادة من مفهوم الـ agents.
يمكن اعتبار الـ agents بمثابة عدة مشغّلين متخصّصين في مهمّة أو مجال معيّن، مما يجعلهم أكثر دقّة، ويعملون عند الحاجة عبر سلسلة توجيه من التفكير.
في المقال التالي، سنناقش تقييم الـ RAG pipeline والأُطر المختلفة التي يمكن الاستفادة منها لهذا الغرض.