
الشبكات العصبية المتكرّرة (RNNs) شبكات deep learning شهيرة جدًّا تُطبَّق على بيانات السلاسل: التنبّؤ بالسلاسل الزمنية، التعرّف على الكلام، تصنيف المشاعر، الترجمة الآلية، Named Entity Recognition، وغيرها..
استخدام الشبكات العصبية feedforward على بيانات السلاسل يُثير مشكلتَين رئيسيتَين:
- قد تختلف أطوال المدخلات والمخرجات في الأمثلة المختلفة
- لا تُشارك MLPs السمات المُتعلَّمة عبر المواضع المختلفة من عيّنة البيانات
في هذا المقال، سنكتشف الرياضيات وراء نجاح RNNs بالإضافة إلى بعض الأنواع الخاصّة من الخلايا مثل LSTMs وGRUs. وأخيرًا سنتعمّق في معماريات encoder-decoder المدمجة مع آليات الانتباه.
ملاحظة: بما أنّ Medium لا يدعم LaTeX، تمّ إدراج التعبيرات الرياضية كصور. لذا أنصحك بإيقاف الوضع الداكن للحصول على تجربة قراءة أفضل.
الملخّص كالتالي:
- الرموز
- نموذج RNN
- أنواع مختلفة من RNNs
- أنواع متقدّمة من الخلايا
- معمارية Encoder وDecoder
- آليات الانتباه
الرموز
كتوضيح، سننظر في مهمّة Named Entity Recognition التي تتمثّل في تحديد موقع الكيانات المُسمّاة والتعرّف عليها مثل الأسماء العَلَم:

نرمز:

عند التعامل مع بيانات غير رقمية، النصّ مثلًا، من المهمّ جدًّا ترميزها إلى متّجهات رقمية: تُسمّى هذه العملية embedding. إحدى أشهر طرق ترميز النصّ هي Bert التي طوّرتها Google.
نموذج RNN
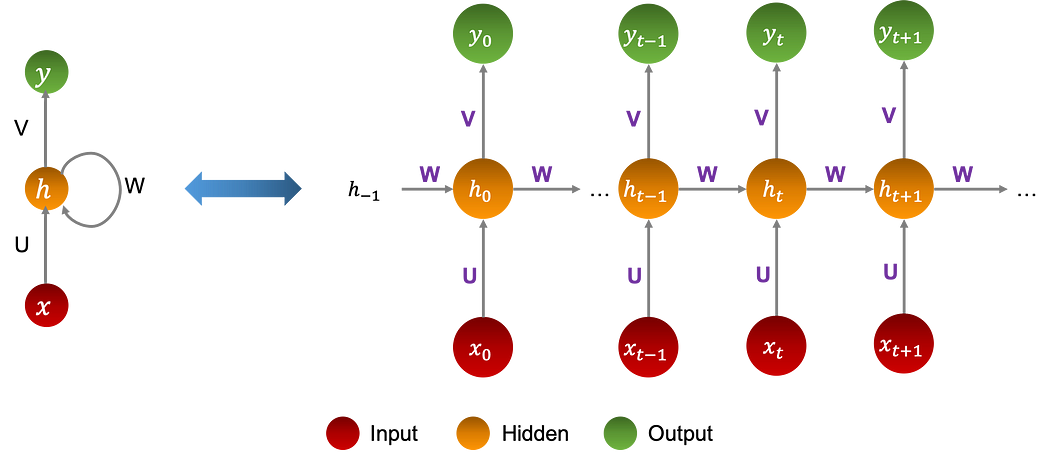
تمثّل RNNs حالة خاصّة من الشبكات العصبية حيث تكون بارامترات النموذج والعمليات المُنفَّذة هي نفسها في جميع أنحاء المعمارية. تُؤدّي الشبكة المهمّة نفسها لكلّ عنصر في سلسلة يكون output depends on the input and the previous state of the memory.
يوضّح الرسم البياني أدناه شبكة عصبية من الخلايا العصبية لها طبقة واحدة من الذاكرة المخفيّة:
المعادلات
المتغيّرات في المعمارية هي:

حيث:
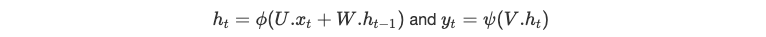
h(−1) تُهيَّأ عشوائيًا، وϕ وψ دوال غير خطّية، وU، V، وW هي parameters الانحدارات الخطّية المختلفة، التي تسبق التنشيطات غير الخطّية.
من المهمّ ملاحظة أنّها هي نفسها في جميع أنحاء المعمارية.
التطبيقات
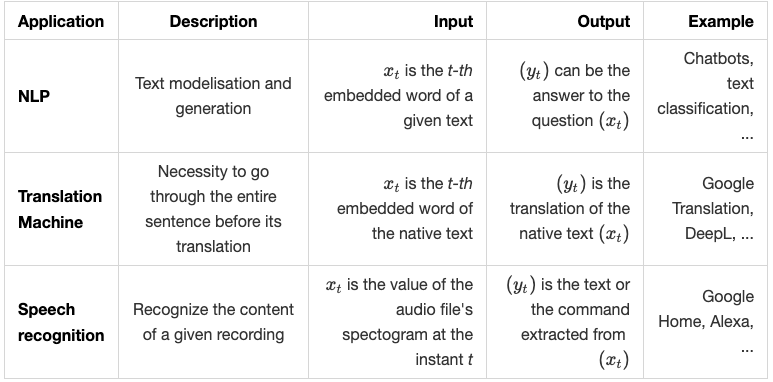
حسّنت الشبكات العصبية المتكرّرة بشكل ملحوظ النماذج التسلسلية، خصوصًا:
- مهام NLP، النمذجة وتوليد النصوص
- الترجمة الآلية
- التعرّف على الصوت
نُلخّص التطبيقات المذكورة أعلاه في الجدول التالي:
خوارزمية التعلّم
كما في الشبكات العصبية الكلاسيكية، يتمّ التعلّم في حالة الشبكات المتكرّرة بتحسين دالّة تكلفة بالنسبة لـ U، V وW. وبعبارة أخرى، نهدف إلى إيجاد أفضل البارامترات التي تُعطي أفضل تنبّؤ y^i، انطلاقًا من الإدخال xi، للقيمة الحقيقية yi.
لذلك، نُعرّف دالّة هدف تُسمّى loss function ويُرمز إليها بـ J تُكمّم المسافة بين القيم الحقيقية والمتنبّأ بها على مجموعة التدريب الكاملة.
نُصغّر J باتّباع خطوتَين رئيسيتَين:
Forward Propagation: نُمرّر البيانات عبر الشبكة إمّا كاملةً أو على دفعات، ونحسب loss function على هذه الدفعة وهي ليست إلّا مجموع الأخطاء المرتكبة عند الإخراج المتنبّأ به للصفوف المختلفة.Backward Propagation Through Time: تتمثّل في حساب gradients لدالّة التكلفة بالنسبة للبارامترات المختلفة، ثمّ تطبيق خوارزمية انحدار لتحديثها. وتُسمّى BPTT، لأنّ gradients عند كلّ إخراج تعتمد على عناصر اللحظة نفسها وحالة الذاكرة في اللحظة السابقة.
نُكرّر العملية نفسها عددًا من المرّات يُسمّى epoch number. بعد تعريف المعمارية، تُكتب خوارزمية التعلّم على النحو التالي:

(∗) تُقيّم دالّة التكلفة L المسافات بين القيم الحقيقية والمتنبّأ بها عند نقطة واحدة.
Forward propagation
لننظر في التنبّؤ بإخراج سلسلة واحدة عبر الشبكة العصبية.
في كلّ لحظة t، نحسب:
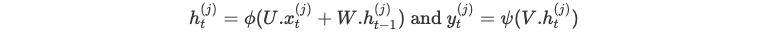
حتى نصل إلى نهاية السلسلة.
مرّة أخرى، البارامترات U، W وV تبقى نفسها على طول الشبكة العصبية.
عند التعامل مع dataset مكوّن من m صف، يكون تكرار هذه العمليات بشكل منفصل لكلّ سطر مكلفًا جدًّا. لذلك، نقتطع dataset للحصول على سلاسل موصوفة في الخطّ الزمني نفسه، أي:
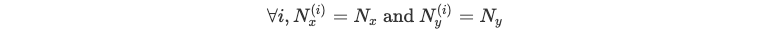
يمكننا استخدام الجبر الخطّي لإجراء ذلك بالتوازي على النحو التالي:
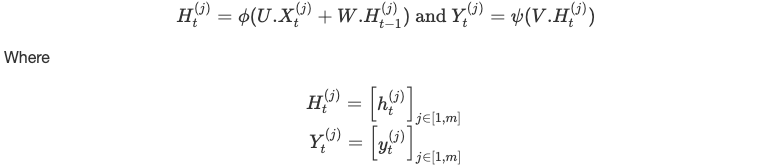
Backpropagation Through Time
backpropagation هي الخطوة الثانية من التعلّم، التي تتمثّل في injecting the error المُرتكب في مرحلة التنبّؤ (forward) داخل الشبكة وتحديث بارامتراتها للحصول على perform better on the next iteration. ومن ثمّ، تحسين الدالّة J، عادةً عبر طريقة الانحدار.

يمكننا الآن تطبيق طريقة انحدار كما هو مفصّل في مقالي السابق.
مشكلة الذاكرة
توجد عدّة مجالات نهتمّ فيها بالتنبّؤ بتطوّر سلسلة زمنية بناءً على تاريخها: الموسيقى، التمويل، المشاعر…إلخ.
تُعاني الشبكات المتكرّرة الجوهرية الموصوفة أعلاه، والتي تُسمّى ‘Vanilla’، من ذاكرة ضعيفة غير قادرة على أخذ عدّة عناصر من الماضي بعين الاعتبار في التنبّؤ بالمستقبل.
مع وضع هذا في الاعتبار، صُمّمت امتدادات مختلفة لـ RNNs لتعزيز الذاكرة الداخلية: الشبكات العصبية ثنائية الاتجاه، خلايا LSTM، آليات الانتباه…إلخ. يمكن أن يكون توسيع الذاكرة حاسمًا في مجالات معيّنة مثل التمويل حيث يسعى المرء إلى حفظ أكبر قدر ممكن من التاريخ من أجل التنبّؤ بسلسلة مالية.
قد تُعاني مرحلة التعلّم في RNN أيضًا من مشاكل gradient vanishing أو gradient exploding لأنّ gradient لدالّة التكلفة يتضمّن قوّة W التي تؤثّر على قدرتها على الحفظ.
أنواع مختلفة من RNNs
توجد عدّة امتدادات للشبكات العصبية المتكرّرة الكلاسيكية أو ‘Vanilla’، صُمّمت هذه الامتدادات لزيادة سعة ذاكرة الشبكة إلى جانب قدرة استخراج السمات.
التوضيح أدناه يُلخّص الامتدادات المختلفة:
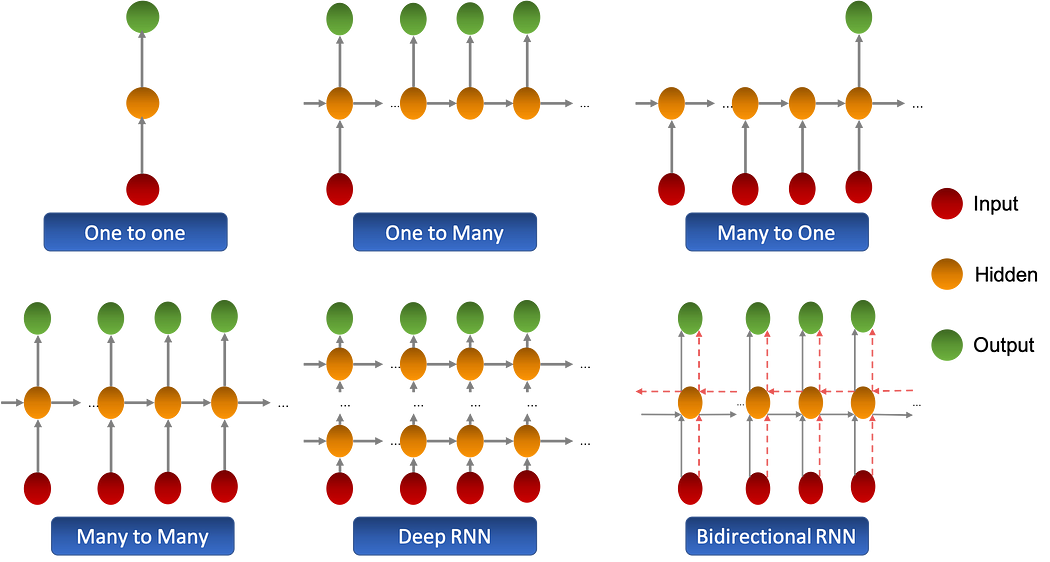
توجد أنواع أخرى من RNNs لها طبقة مخفيّة مصمّمة خصّيصًا سنناقشها في الفصل التالي.
أنواع متقدّمة من الخلايا
Gated Recurrent Unit
تسمح خلايا GRU (Gated Recurrent Unit) للشبكة المتكرّرة بحفظ مزيد من المعلومات التاريخية للحصول على تنبّؤ أفضل. تُقدّم update gate التي تُحدّد كمّية المعلومات المراد الاحتفاظ بها من الماضي، إلى جانب reset gate التي تُحدّد كمّية المعلومات المراد نسيانها.
الرسم البياني أدناه يُخطّط خليّة GRU:
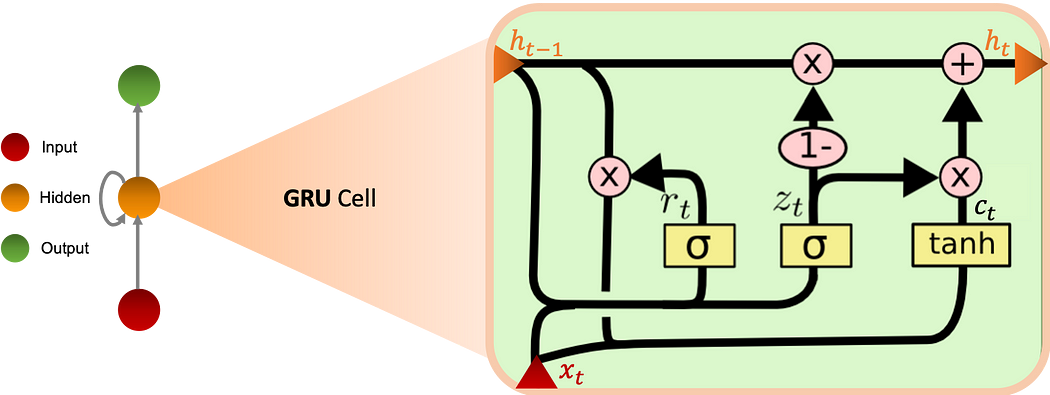
المعادلات
نُعرّف المعادلات في خليّة GRU على النحو التالي:
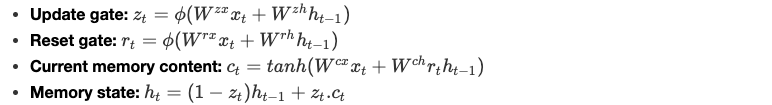
ϕ دالّة عدد صحيح غير خطّية والبارامترات W يتعلّمها النموذج.
Long Short Term Memory
قُدّمت LSTMs (Long Short Term Memory) أيضًا للتغلّب على مشكلة الذاكرة القصيرة، ولديها 4 أضعاف ذاكرة Vanilla RNNs. يستخدم هذا النموذج مفهوم البوّابات ولديه ثلاث منها:
- Input gate i: تتحكّم في تدفّق المعلومات الواردة.
- Forget gate f: تتحكّم في كمّية المعلومات من حالة الذاكرة السابقة.
- Output gate o: تتحكّم في تدفّق المعلومات الخارجة
الرسم البياني أدناه يوضّح عمل خليّة LSTM:
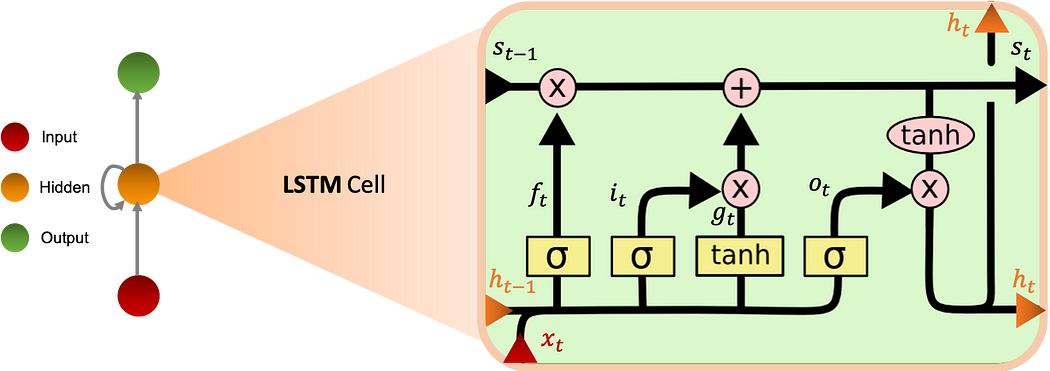
عندما تُغلَق بوّابات الإدخال والإخراج، يُحجَب التنشيط في خليّة الذاكرة.
المعادلات
نُعرّف المعادلات في خليّة LSTM على النحو التالي:
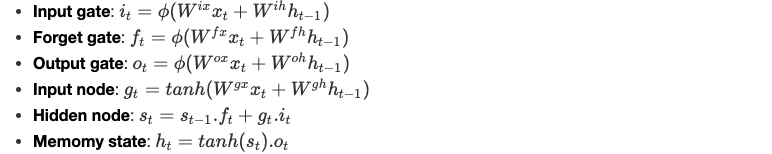
المزايا والعيوب
يمكننا تلخيص مزايا وعيوب خلايا LSTM في 4 نقاط رئيسية:
- المزايا
+ قادرة على نمذجة تبعيات السلاسل طويلة الأمد.
+ أكثر مرونة في مواجهة مشكلة الذاكرة القصيرة من ‘Vanilla’ RNNs لأنّ تعريف الذاكرة الداخلية يتغيّر من:
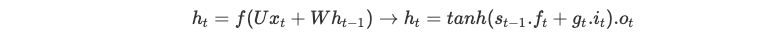
- العيوب
+ تزيد من تعقيد الحوسبة مقارنةً بـ RNN مع إدخال مزيد من البارامترات للتعلّم.
+ الذاكرة المطلوبة أعلى من تلك الخاصة بـ ‘Vanilla’ RNNs بسبب وجود عدّة خلايا ذاكرة.
معمارية Encoder وDecoder
إنّه نموذج تسلسلي يتكوّن من جزأين رئيسيَّين:
Encoder: الجزء الأوّل من النموذج يُعالج السلسلة ثمّ يُعيد في النهاية متّجه ترميز للسلسلة بأكملها يُسمّىcontext vectorيُلخّص معلومات المدخلات المختلفة.Decoder: يُؤخذ context vector بعد ذلك كإدخال للـ decoder من أجل إجراء التنبّؤات.
الرسم البياني أدناه يوضّح معمارية النموذج:
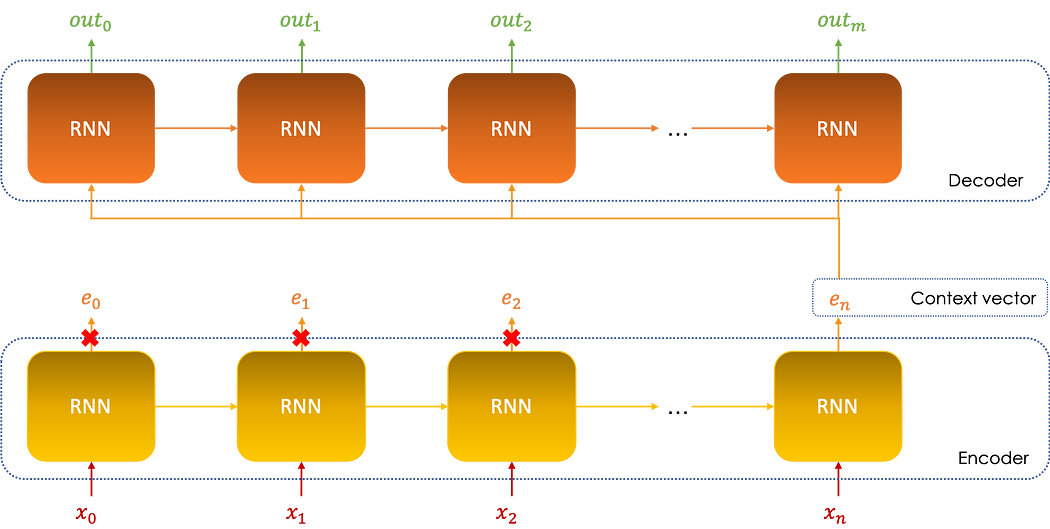
يمكن اعتبار encoder أداة تقليص الأبعاد، ففي الواقع، الـ context vector en ليس إلّا ترميز متّجهات الإدخال (in0,in1,…inn)، ومجموع أحجام هذه المتّجهات أكبر بكثير من حجم en، ومن هنا مفهوم تقليص الأبعاد.
آليات الانتباه
قُدّمت آليات الانتباه لمعالجة مشكلة محدودية الذاكرة، وتُجيب بشكل رئيسي على السؤالَين التاليَين:
- ما الوزن (الأهمّية) αj المُعطى لكلّ إخراج ej من encoder؟
- كيف يمكننا التغلّب على الذاكرة المحدودة لـ encoder للقدرة على "تذكّر" المزيد من عملية الترميز؟
تُدرج الآلية نفسها بين encoder وdecoder وتُساعد decoder على اختيار المدخلات المُرمَّزة المهمّة لكلّ خطوة من عملية فكّ الترميز outi بشكل كبير على النحو التالي:
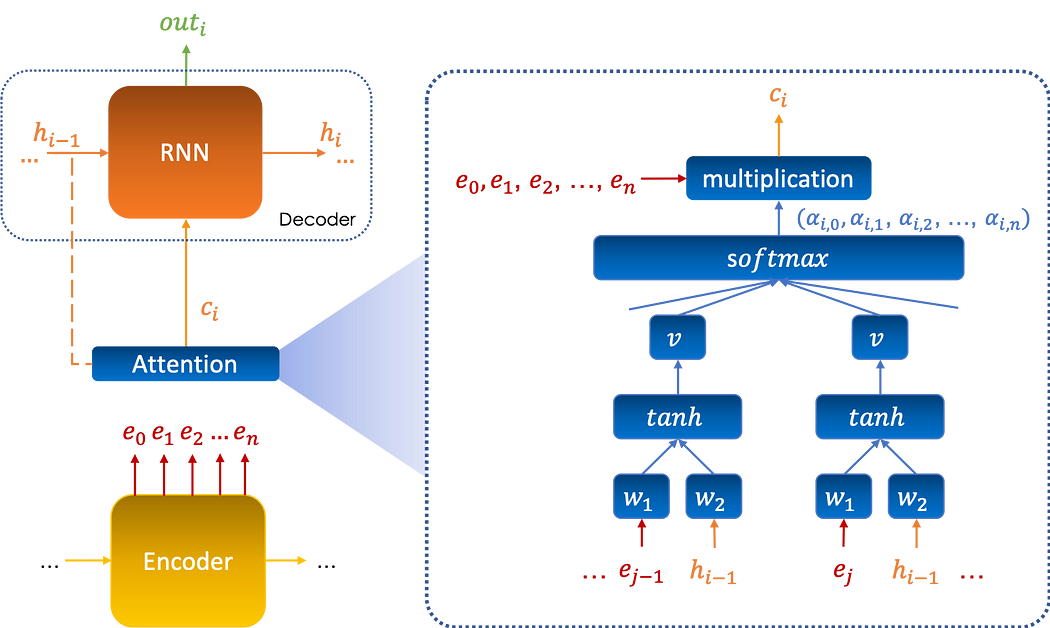
الصياغة الرياضية
مع الحفاظ على الرموز نفسها كما من قبل، نضع αi,j كالانتباه المُعطى من الإخراج i، المُرمز إليه outi، للمتّجه ej.
يُحسب الانتباه عبر شبكة عصبية تأخذ كمدخلات المتّجهات (e0,e1,…,en) وحالة الذاكرة السابقة h(i-1)، ويُعطى بـ:

تطبيق: الترجمة الآلية
يجعل استخدام آلية الانتباه من الممكن visualize and interpret ما يفعله النموذج داخليًا، خصوصًا عند التنبّؤ.
على سبيل المثال، برسم 'heatmap' لمصفوفة الانتباه لنظام ترجمة، يمكننا رؤية الكلمات في اللغة الأولى التي يُركّز عليها النموذج لترجمة كلّ كلمة إلى اللغة الثانية:
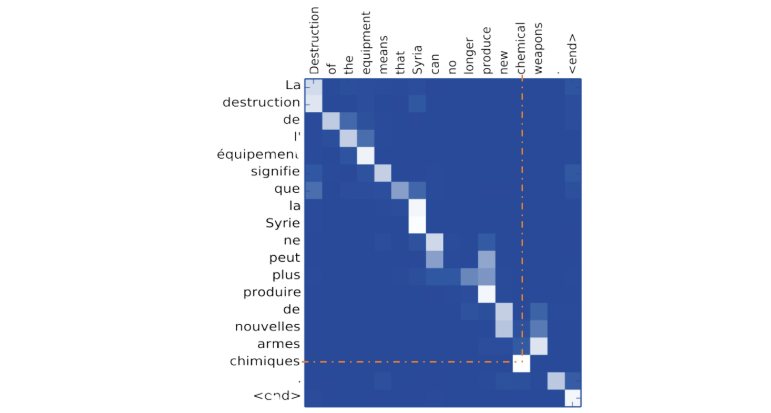
كما هو موضّح أعلاه، عند ترجمة كلمة إلى الإنجليزية، يُركّز النظام بشكل خاصّ على الكلمة الفرنسية المقابلة.
دمج LSTM وآلية الانتباه
من المُجدي دمج الطريقتَين لتحسين الذاكرة الداخلية، لأنّ الأولى تسمح بأخذ مزيد من عناصر الماضي في الاعتبار والثانية تختار إيلاء اهتمام دقيق لها عند التنبّؤ.
الإخراج ct لآلية الانتباه هو الإدخال الجديد لخليّة LSTM، فيصبح نظام المعادلات على النحو التالي:
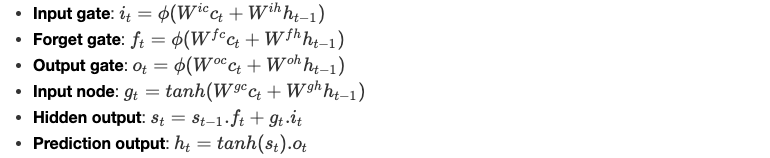
ϕ دالّة عدد صحيح غير خطّية والبارامترات W يتعلّمها النموذج.
الخاتمة
RNNs أداة قويّة جدًّا للتعامل مع بيانات السلاسل، فهي توفّر قدرات حفظ مذهلة وتُستخدم على نطاق واسع في الحياة اليومية.
كما أنّ لها امتدادات عديدة تُتيح معالجة أنواع مختلفة من المشاكل المعتمدة على البيانات، خصوصًا تلك التي تتعلّق بالسلاسل الزمنية.
لا تتردّد في الاطلاع على مقالاتي السابقة التي تناقش:
- Deep Learning’s mathematics
- Convolutional Neural Networks’ mathematics
- Object detection & Face recognition algorithms
المراجع
- Z.Lipton, J.Berkowitz, C.Elkan, A Critical Review of Recurrent Neural Networks for Sequence Learning, arXiv: 1506.00019v4, 2015.
- H.Salehinejad, S.Sankar, J.Barfett, E.Colak, S.Valaee, Recent Advances in Recurrent Neural Networks, arXiv: 1801.01078v3, 2018.
- Y.Baveye, C.Chamaret, E.Dellandréa, L.Chen, Affective Video Content Analysis: A Multidisciplinary Insight, HAL Id: hal-01489729, 2017.
- A.Azzouni, G.Pujolle, A Long Short-Term Memory Recurrent Neural Network Framework for Network Traffic Matrix Prediction, arXiv: 1705.05690v3, 2017.
- Y.G.Cinar, H.Mirisaee, P.Goswami, E.Gaussier, A.Ait-Bachir, V.Strijov, Time Series Forecasting using RNNs: an Extended Attention Mechanism to Model Periods and Handle Missing Values, arXiv: 1703.10089v1, 2017.
- K.Xu, L.Wu, Z.Wang, Y.Feng, M.Witbrock, V.Sheinin, Graph2Seq: Graph to Sequence Learning with Attention-Based Neural Networks, arXiv: 1804.00823v3, 2018.
- Rose Yu, Yaguang Li, Cyrus Shahabi, Ugur Demiryurek, Yan Liu, Deep Learning: A Generic Approach for Extreme Condition Traffic Forecasting, Southern California university, 2017.