
Many companies nowadays have to deal with the processing of similar cases within their activity. Few of them, take advantage of the old and previous work while the vast majority go all over again.
In this article, we will discover how we can leverage AI algorithms to build a matching engine that can use textual, categorical, and numerical variables as well.
For the sake of simplicity, we will consider that a case is described by the following data:
- Num: Numerical variable
- Categ: Categorical variable (one word)
- Sent: Textual variable (1 sentence - requires embedding)
- Parag: Textual variable (paragraph - requires embedding)
If your database does not follow the same structure, you can apply a preprocessing pipeline to fall into the same scenario.
The summary is as follows:
- Embeddings
- Similarities
- Matching engine
Embeddings
Word embedding
Word embedding is the art of representing a word in a vectorial space of size N where semantically similar words are, mathematically speaking, close to each other.
This is an important step when dealing with textual data since ML algorithms work mostly with numerical values.
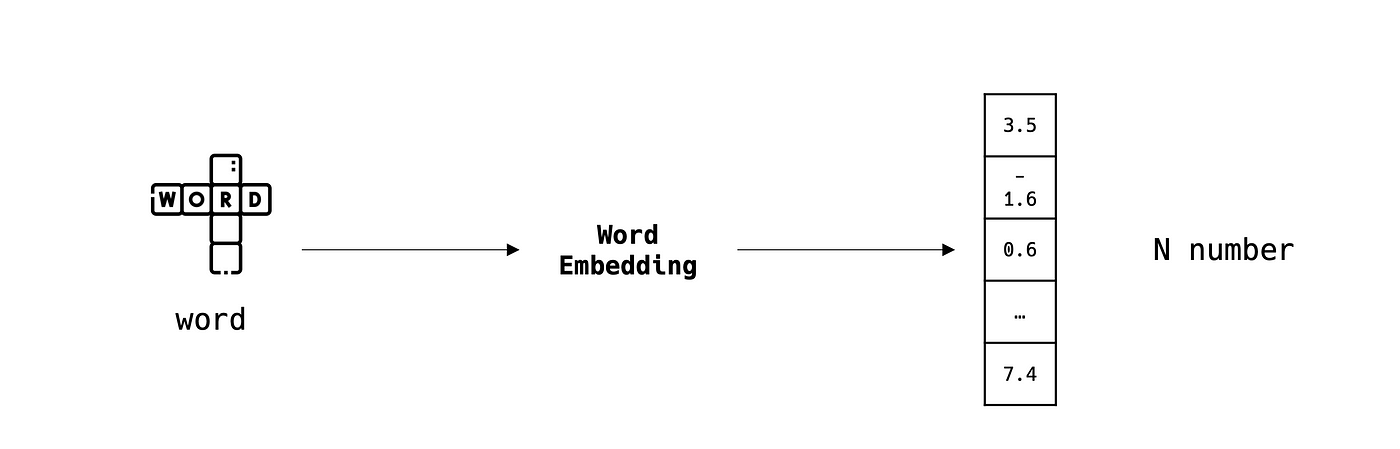
There are many word embedding algorithms such as Word2Vec, FastText, BERT, …, which have several adaptations in different languages.
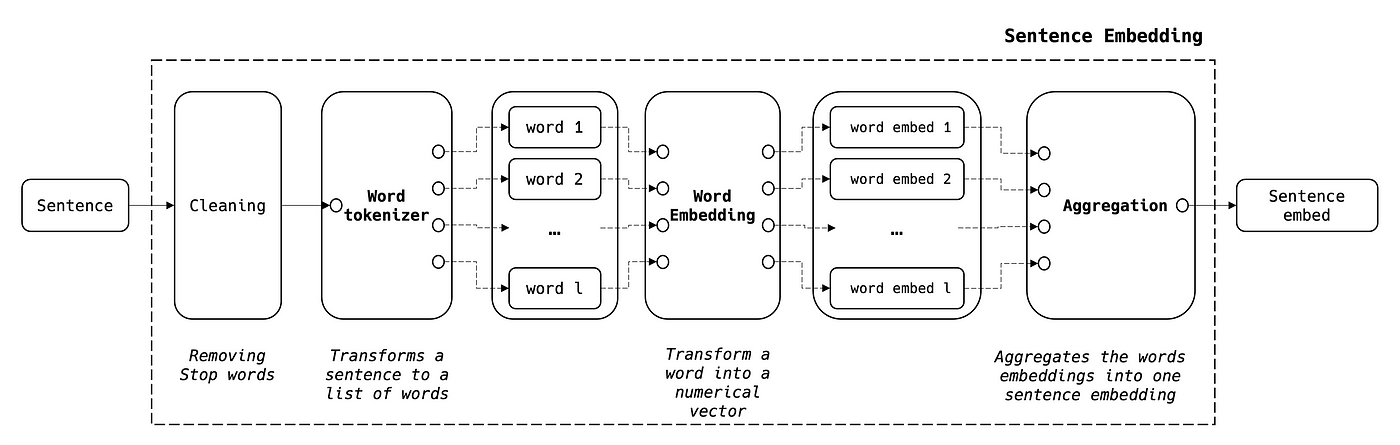
Sentence Embedding
A sentence is a sequence of words. With that being said, we can aggregate words embeddings to generate the sentence’s embedding following the steps below:
where:
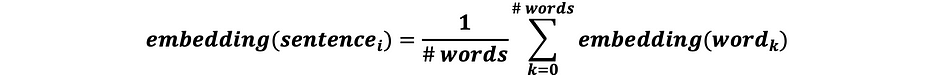
- NB1: in the cleaning stage, we can keep only keywords to be embedded
- NB2: the aggregated formula allows to balance between long and short sentences
- NB3: the size of the sentence’s embedding is the same as the size of the word’s embedding N
Paragraph Embedding
We can use the same approach as above given the fact that a paragraph is a sequence of sentences:
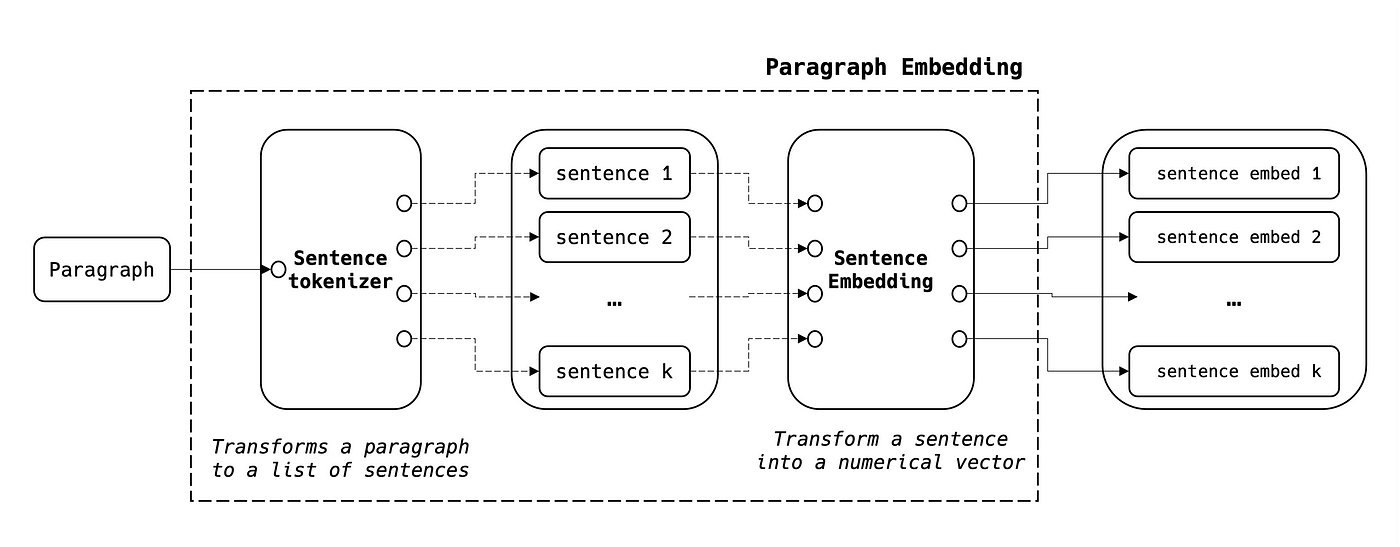
- NB1: in the common language, sentences are often separated using the string “ . ”, but customization might be required in some cases.
- NB2: The size of the paragraph’s embedding is (N, k) where N is the size of the sentence’s embedding and k is the number of sentences within the paragraph.
Similarity
Numerical similarities
Let’s consider two numerical values x and y and NumSim the distance between the two is defined as follows:
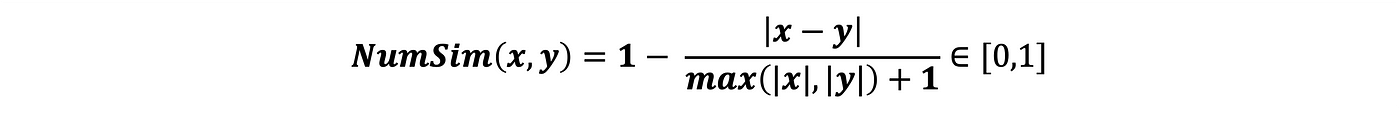
if:
- x=y => NumSim(x,y)=1
- x>>y => NumSim(x,y)≈1/(|x|+1)≈0
Words similarities
There are many methods to compute the similarity between two words, we cite below two of the most famous approaches:
- Approximate string matching (character-based): Levenshtein’s distance, …
- Semantic string matching (Embedding-based): Cosine similarity, Euclidian distance, …
In this article, we will focus mainly on the cosine similarity which is nothing but the cosine of the angle between the two embedding vectors of the two compared words:
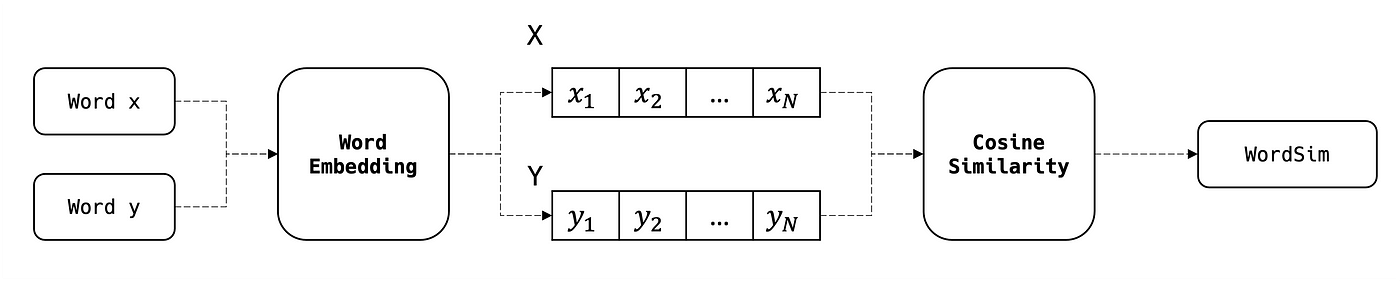
Where:
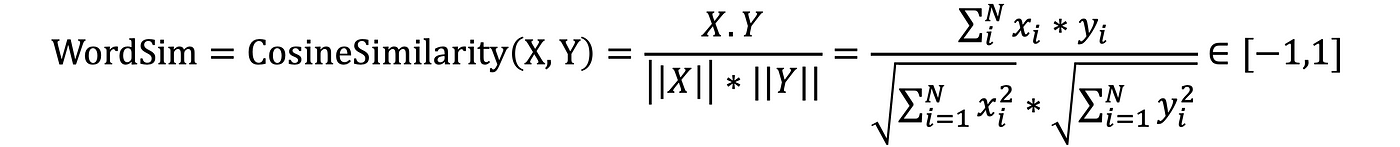
Sentences similarities
We follow the same approach using this time the sentence embedding algorithm defined above:

Where:

Paragraphs similarities
The paragraph’s similarities are slightly more complicated since their embeddings are considered as 2D matrices rather than vectors. To compare the two paragraphs, we compute the SentSim of each peer to peer sentences and generate a 2D similarity matrix which is then aggregated into one score:
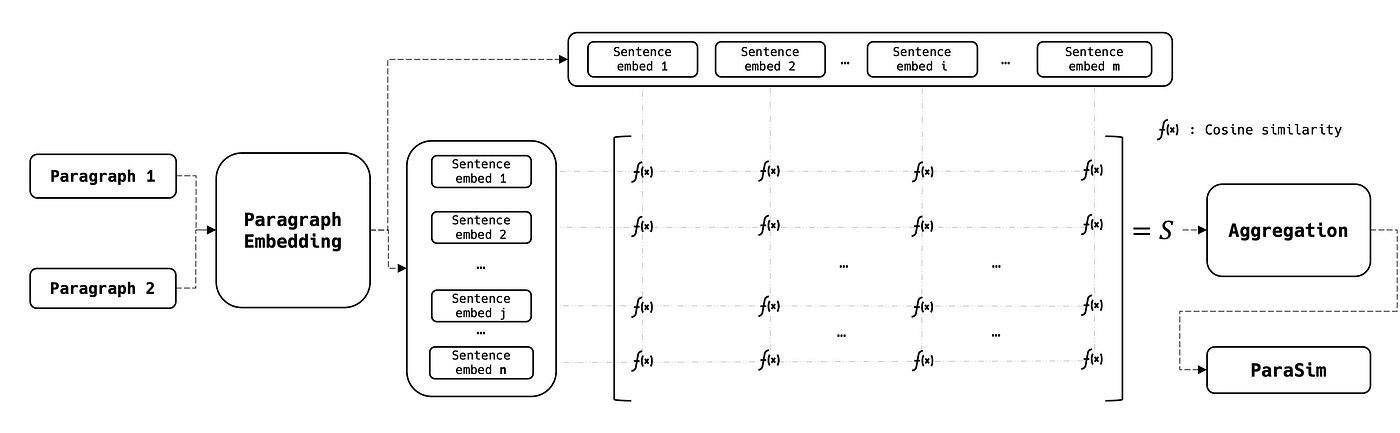
Where:

Matching Engine
As previously mentioned, let’s consider a business case where we have to deal with the processing of many cases. Each case is described with the four variables: Num, Categ, Sent, and Parag (see introduction).
We can leverage historical data to compare each new case with the whole database and select the ones that are the most similar using the following diagram:
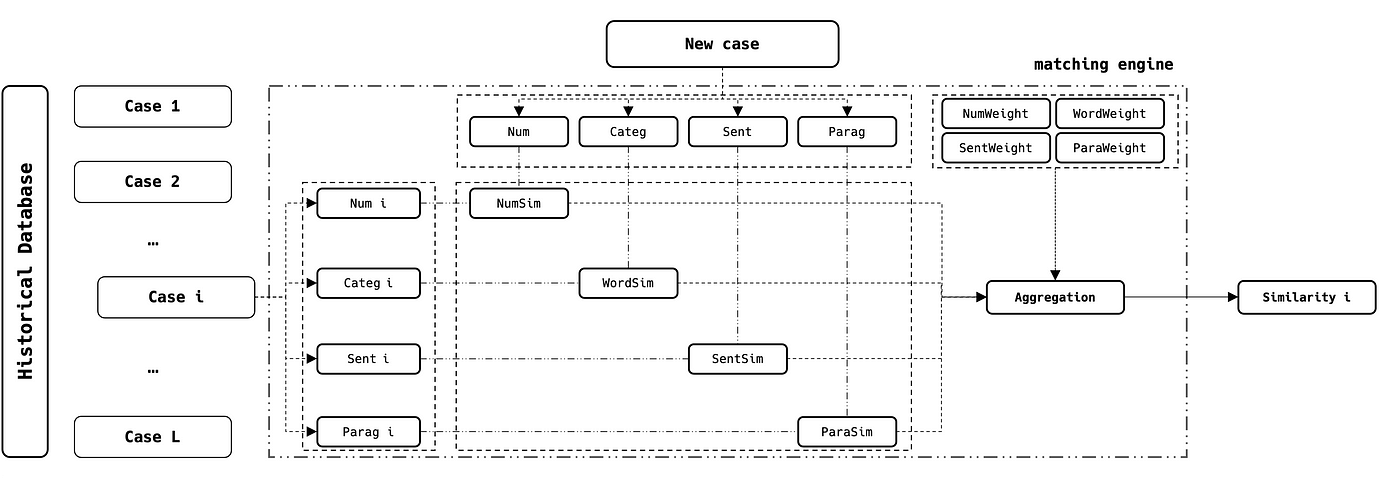
Where:
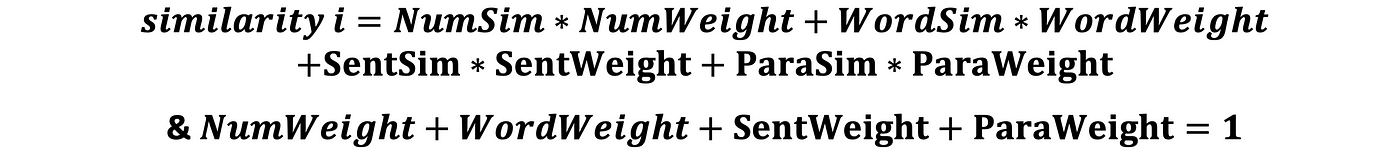
We perform these operations on all cases from 1 to L (being the size of the database) and output the highest matching scores.
- NB1: if the Categ variable has unique and stable modalities we can replace the matching with a simple filtering
- NB2: if you have more than one variable per type, you can stack them to the same engine using the right similarity approach
- NB3: the weight of each variable is chosen depending on its business priority and importance
Conclusion
Matching engines are widely popular and used in the tech world. They enable businesses with faster processing tools that allow time and financial gains.
In this article, we have focused on a specific type of input (Numerical and Textual), but you could also imagine having an image as an extra description of our case. This calls for using CNN technics such as Siamese networks which generate an image embedding used with cosine similarity to generate an extra matching score.