

RAG is a very popular LLM application enabling Q&A on top of your data by leveraging the reasoning capabilities of the model. The question is usually either:
- Objective: true-false, multiple-choice, exact words-number …, mainly used in key points extraction pipelines.
- Subjective: short-elaborated paragraph used in general Q&A use-cases
Many developers have been looking for tools to evaluate RAG pipelines through a usual TDD approach given the high variability of inputs (which could also change versions with time) and the volatility of the output generated by LLMs.
In this article, we walk through the different evaluation frameworks that can be used when working on RAG systems.
The summary is as follows:
- Evaluation concept
- Outlines
- RAGAS
- Custom Framework
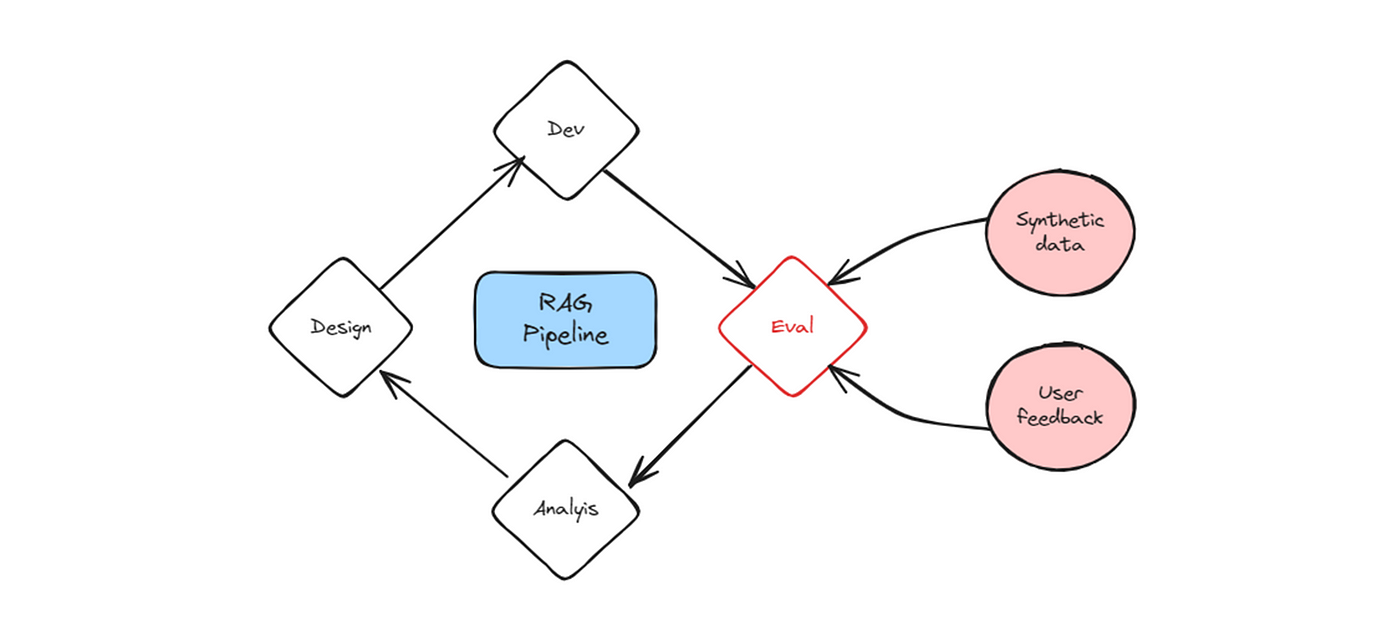
Evaluation concept
Evaluating a RAG pipeline is an iterative process that consists of matching its output with predefined test cases. The test database usually contains the tuple (question, context, ground_truth, predicted_answer) and could either be:
- Reel: manually generated or collected from users’ feedback
- Synthetic: generated using an LLM that outputs a set of questions and answers from a paragraph of text.
The evaluation data should naturally have unique and diverse questions representative of both the task and the knowledge that is being queried. It is also recommended to include test cases where the subjective questions are straight to the point which makes the answers shorter and fact-unique.
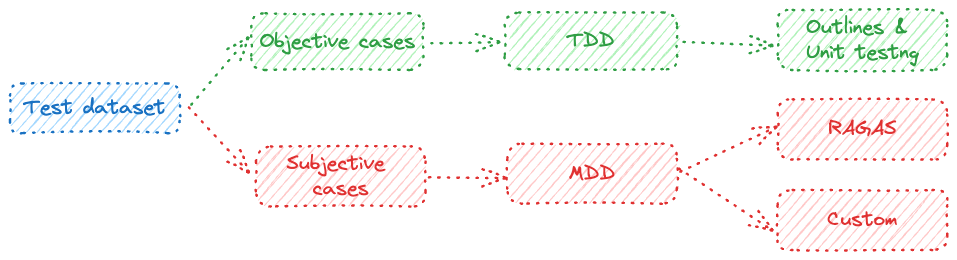
Given the questions’ nature (objective and subjective), two options are being considered:
- TDD — Test Driven Development: powered by Outlines, a Python library that leverages LLMs to return specific output format (Regex-based for example). It can be combined with unit testing to evaluate the objective questions.
- MDD — Metric Driven Development: a product approach powered by an evaluation framework (Package or custom). It relies on evaluating specific KPIs to continuously monitor the performance of the RAG pipeline. The KPIs are generally scores between 0 and 1 and generated by an LLM given the grammatical variety of ways to answer subjective questions.
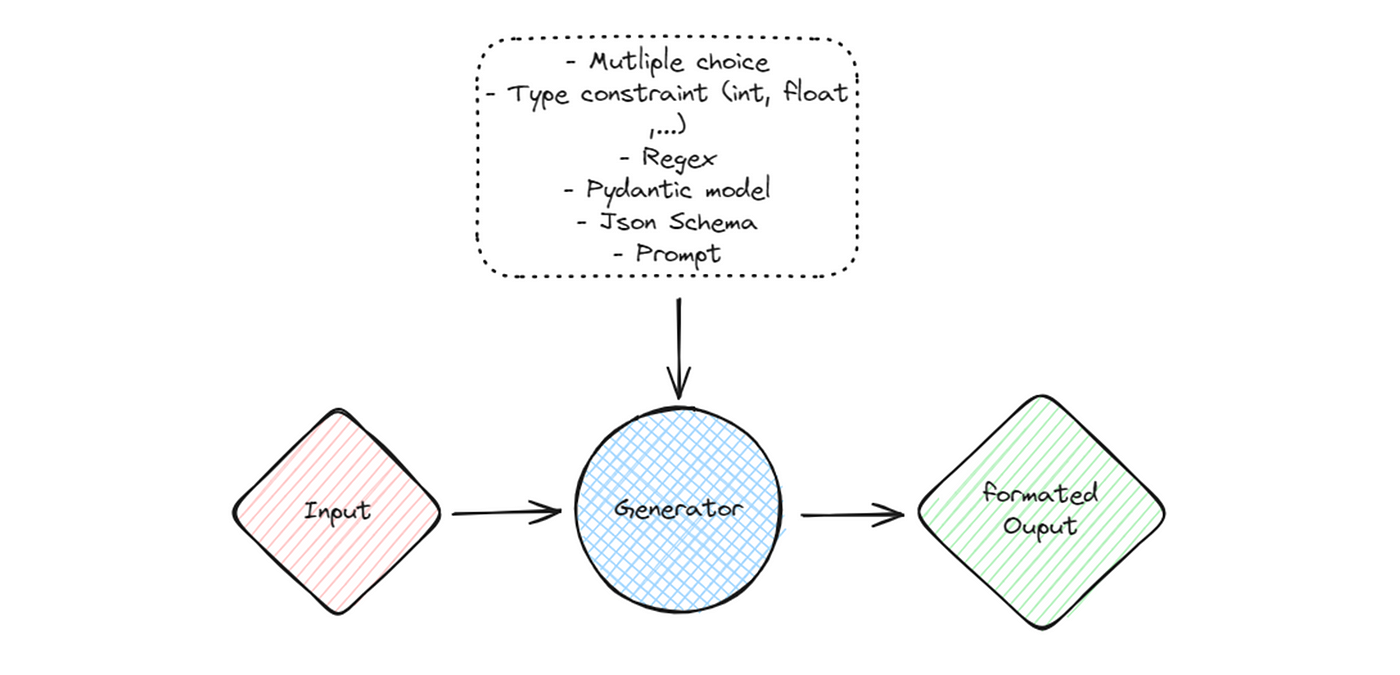
Outlines
Outlines is a python library used to force the output format of the completion step by leveraging another Large Language Model (OpenAI, transformers, llama.cpp, …). This ensures reliability in the RAG pipeline enabling a more controllable and predictable output of the LLM. The format can be: type, regex, Pydantic model or JSON-based.
The generated output can be evaluated using unit testing. You can check my previous article discussing their implementation using the Pytest framework.
Python script
For illustration purposes, we’ll consider a RAG UC where we’re trying to retrieve information related to a company from a knowledge database.
from pydantic import BaseModel, constr
import outlines
import os
COMLPETION_ENGINE='gpt-4-turbo'
API_VERSION=OPENAI_CRED[COMLPETION_ENGINE]['API_VERSION']
API_BASE=OPENAI_CRED[COMLPETION_ENGINE]['AZURE_ENDPOINT']
API_KEY=OPENAI_CRED[COMLPETION_ENGINE]['API_KEY']
os.environ["AZURE_OPENAI_BASE"] = API_BASE
os.environ["AZURE_OPENAI_API_VERSION"]=API_VERSION
os.environ["AZURE_OPENAI_API_KEY"]=API_KEY
class Field(str, Enum):
technology= "technology"
healthcare="healthcare"
finance="finance"
consumer_good="consumer_good"
energy="energy"
class Company(BaseModel):
name: constr(max_length=24)
street_number: int
street_name: str
office_number: str
zip_code: str
city: constr(max_length=24)
country_code: constr(max_length=5)
cin:int #corportate identification number
field:Field
model=outlines.models.openai(COMLPETION_ENGINE)
# Construct structured sequence generator
generator = outlines.generate.json(model, Company)
#Prompt
prompt_template="""
Given the following context, extract the information related to the company:
context:{{context}}
"""
#context if the output of the retriever
result = generator(prompt_template.replace("{{context}}",context), rng=rng)
RAGAS
RAGAS is a framework used for the evaluation of RAG pipeline component-wise (Retriever and Generator) as well as end-to-end to monitor and improve its quality.
Overall, it requires 4 inputs: Question, Ground truths, Contexts, Answer.
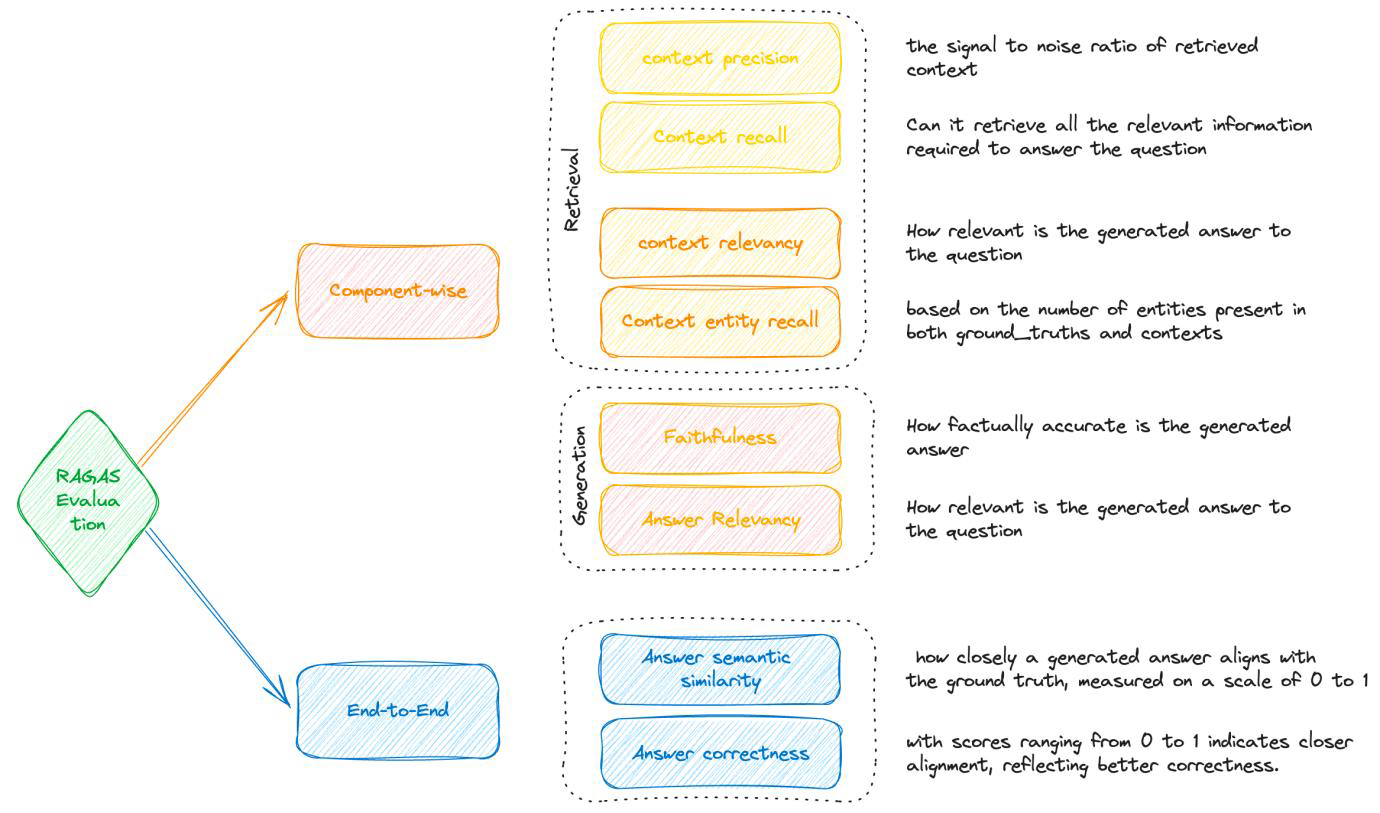
Context Precision
Definition: Context Precision is a metric that evaluates whether all of the ground-truth relevant items present in the contexts are ranked higher or not. Ideally, all the relevant chunks must appear at the top ranks. This metric is computed using the question and the context, with values ranging between 0 and 1, where higher scores indicate better precision.

Input: (context, ground truth)
Example:
- Question: Where is France and what is its capital?
- Ground truth: France is in Western Europe and its capital is Paris.
- High score: [“France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre and monuments like the Eiffel Tower”, “The country is also renowned for its wines and sophisticated cuisine. Lascaux’s ancient cave drawings, Lyon’s Roman theater and the vast Palace of Versailles attest to its rich history.”]
- Low score: [“The country is also renowned for its wines and sophisticated cuisine. Lascaux’s ancient cave drawings, Lyon’s Roman theater and”, “France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre and monuments like the Eiffel Tower”,]
Context Recall
Definition: Context recall measures the extent to which the retrieved context aligns with the annotated answer, treated as the ground truth. It is computed based on the ground truth and the retrieved context, and the values range between 0 and 1, with higher values indicating better performance.
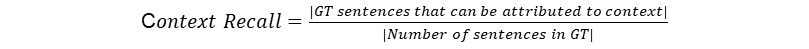
Input: (context, ground truth)
Example:
- Question: Where is France and what is its capital?
- Ground truth: France is in Western Europe and its capital is Paris.
- High score: France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre and monuments like the EiffelTower.
- Low score: France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. The country is also renowned for its wines and sophisticated cuisine. Lascaux’s ancient cave drawings, Lyon’s Roman theater and the vast Palace of Versailles attest to its rich history.
Context Relevancy
Definition: This metric gauges the relevancy of the retrieved context, calculated based on both the question and context. The values fall within the range of (0, 1), with higher values indicating better relevancy. Ideally, the retrieved context should exclusively contain essential information to address the provided query.
Input: (question, contexts)
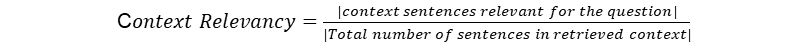
Example:
- Question: What is the capital of France?
- High score: France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre and monuments like the Eiffel Tower.
- Low score: France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre and monuments like the Eiffel Tower. The country is also renowned for its wines and sophisticated cuisine. Lascaux’s ancient cave drawings, Lyon’s Roman theater and the vast Palace of Versailles attest to its rich history.
Context Entity Recall
Definition: This metric gives the measure of recall of the retrieved context, based on the number of entities present in both ground truths and context relative to the number of entities present in the ground truths alone. Simply put, it is a measure of what fraction of entities are recalled from ground truths. This metric is useful in fact-based use cases like tourism help desk, historical QA, etc. This metric can help evaluate the retrieval mechanism for entities, based on comparison with entities present in ground truths, because in cases where entities matter, we need the contexts which cover them.
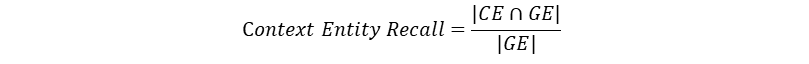
Input: (ground truths, context)
Example:
- Ground Truth: The Taj Mahal is an ivory-white marble mausoleum on the right bank of the river Yamuna in the Indian city of Agra. It was commissioned in 1631 by the Mughal emperor Shah Jahan to house the tomb of his favorite wife, Mumtaz Mahal.
- High score: The Taj Mahal is a symbol of love and an architectural marvel located in Agra, India. It was built by the Mughal emperor Shah Jahan in memory of his beloved wife, Mumtaz Mahal. The structure is renowned for its intricate marble work and beautiful gardens surrounding it.
- Low score: The Taj Mahal is an iconic monument in India. It is a UNESCO World Heritage Site and attracts millions of visitors annually. The intricate carvings and stunning architecture make it a must-visit destination.
Faithfulness
Definition: This measures the factual consistency of the generated answer against the given context. It is calculated from the answer and retrieved context. The answer is scaled to (0,1) range. Higher the better. The generated answer is regarded as faithful if all the claims that are made in the answer can be inferred from the given context
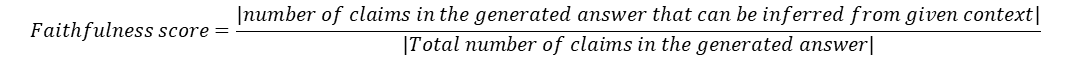
Input: (contexts, answer)
Example:
- Question: Where and when was Einstein born?
- Context: Albert Einstein (born 14 March 1879) was a German-born theoretical physicist, widely held to be one of the greatest and most influential scientists of all time
- High score: Einstein was born in Germany on 14th March 1879.
- Low score: Einstein was born in Germany on 20th March 1879.
Answer Relevancy
Definition: The evaluation metric, Answer Relevancy, focuses on assessing how pertinent the generated answer is to the given prompt. A lower score is assigned to answers that are incomplete or contain redundant information. This metric is computed using the question and the answer, with values ranging between 0 and 1, where higher scores indicate better relevancy.
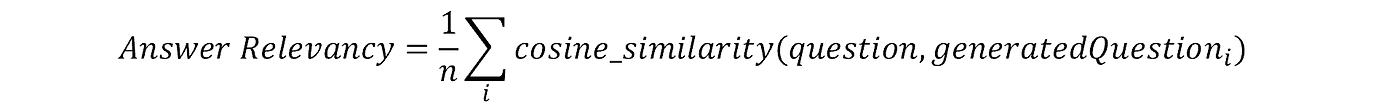
Input: (question, answer)
Example:
- Question: Where is France and what is its capital?
- High score: France is in western Europe and Paris is its capital.
- Low score: France is in Western Europe.
Answer Semantic Similarity
Definition: The concept of Answer Semantic Similarity pertains to the assessment of the semantic resemblance between the generated answer and the ground truth. This evaluation is based on the ground truth and the answer, with values falling within the range of 0 to 1. A higher score signifies a better alignment between the generated answer and the ground truth
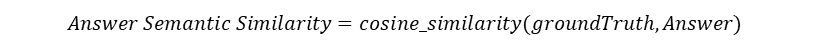
Input: (Ground truth, Answer)
Example:
- Ground truth: Albert Einstein’s theory of relativity revolutionized our understanding of the universe.”
- High score: Einstein’s groundbreaking theory of relativity transformed our comprehension of the cosmos.
- Low score: Isaac Newton’s laws of motion greatly influenced classical physics.
Answer correctness
Definition: the assessment of Answer Correctness involves gauging the accuracy of the generated answer when compared to the ground truth. This evaluation relies on the ground truth and the answer, with scores ranging from 0 to 1. A higher score indicates a closer alignment between the generated answer and the ground truth, signifying better correctness

Input: (Answer, Ground Truth)
Example:
- Ground truth: Einstein was born in 1879 in Germany.
- High score: High answer correctness: In 1879, Einstein was born in Germany.
- Low score: Low answer cor4rectness: Einstein was born in Spain in 1879.
NB: the definition above were inspired by the official documentation of RAGAS framework
Python script
Below is the script for running the RAGAS evaluation framework with Azure OpenAI. You can also use an open-source LLM.
## Imports
from langchain_openai import AzureOpenAIEmbeddings
from langchain_openai.chat_models import AzureChatOpenAI
from ragas.llms import LangchainLLM
from ragas import evaluate
from datasets import Dataset
from ragas.metrics import (
answer_correctness,
answer_relevancy,
answer_similarity,
context_precision,
context_recall,
context_relevancy,
faithfulness,
)import pandas as pd
import os
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
## Set openai env vars
COMLPETION_ENGINE='gpt-4-turbo'
API_VERSION=OPENAI_CRED[COMLPETION_ENGINE]['API_VERSION']
API_BASE=OPENAI_CRED[COMLPETION_ENGINE]['AZURE_ENDPOINT']
API_KEY=OPENAI_CRED[COMLPETION_ENGINE]['API_KEY']
os.environ["AZURE_OPENAI_BASE"] = API_BASE
os.environ["AZURE_OPENAI_API_VERSION"]=API_VERSION
os.environ["AZURE_OPENAI_API_KEY"]=API_KEY
## Embedding and Completion models
def get_azure_openai_embed_gener():
embeddings = AzureOpenAIEmbeddings(
openai_api_version=API_VERSION,
azure_endpoint=API_BASE,
azure_deployment=EMBDEDING_ENGINE,
model=EMBDEDING_ENGINE,
)
llm = AzureChatOpenAI(
openai_api_version=API_VERSION,
azure_endpoint=API_BASE,
azure_deployment=COMLPETION_ENGINE,
model=COMLPETION_ENGINE,
)
return embeddings, llm
## Ragas metrics
def get_metrics(
embeddings,
llm,
):
metrics = [
answer_correctness,
answer_relevancy,
answer_similarity,
context_precision,
context_recall,
context_relevancy,
faithfulness,
]
for m in metrics:
m.__setattr__("llm", llm)
if hasattr(m, "embeddings"):
m.__setattr__("embeddings", embeddings)
answer_correctness.faithfulness = faithfulness
answer_correctness.answer_similarity = answer_similarity
return metrics
## Main script
#Load embedding and LLM models
embeddings, llm = get_azure_openai_embed_gener()
llm = LangchainLLM(llm=llm)
metrics = get_metrics(embeddings, llm)
#df has columns:
#question:str
#ground_truths:List[str]
#answer:List[str]
#contexts:List[str]
#Launch evaluation
ragas_eval= evaluate(
Dataset.from_pandas(df),
metrics=metrics,
raise_exceptions=False,
).to_pandas()
Custom Framework
Custom frameworks are another way to automate your evaluation based on specific tasks in your RAG pipeline. This comes in handy when combined with few-shots prompting related to your use case. These will specify examples of inputs and their associated scores.
This MDD approach consists of setting for every custom metric:
- Definition: explicit comparison that has to be inferred by the LLM
- Inputs: that are being compared
- Model: embedding or completion
- Few shots: reference cases for the scoring step
- Output: usually a score between 0 and 1 or 1 and 5
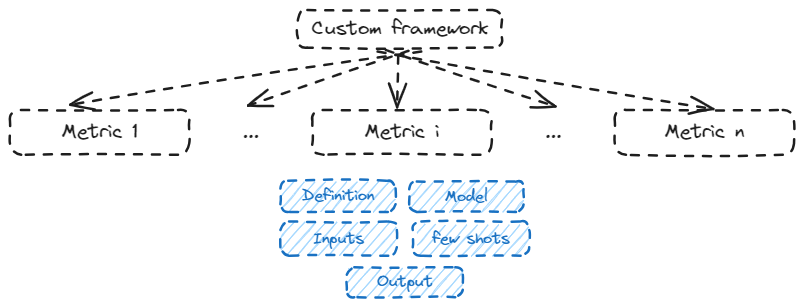
Python script
Let’s consider five main metrics similar to the ones from RAGAS as an example:
- Answer similarity: How close the facts of the answers are ?
- Answer fluency: What is the quality of the generated answer ?
- Answer groundedness: How much the answer is based on the provided context ?
- Answer relevancy: how relevant the answer is to the question ?
- Answer coherence: How coherent the different sentences of the answer are to each other ?
The metrics above will be computed using gpt-4-turbo as an LLM judge.
NB: Do not forget to adapt the few shots with examples from your use-case.
#Few shots inspired from the prompt flow evaluation of Microsoft
from dataclasses import dataclass
@dataclass
class answer_similarity:
question: str
ground_truth: str
answer: str
name: str = "answer_similarity"
prompt_template: str = """
System:
You are an AI assistant. You will be given a definition of an evaluation metric for assessing the quality of an answer in a question-answering task. Your task is to compute an accurate evaluation score using the provided metric. Provide only the metric value without any additional text or explanation.
User:
Equivalence measures the similarity between the predicted answer and the correct answer. If the information and facts in the predicted answer are similar or equivalent to the correct answer, the Equivalence metric value should be high; otherwise, it should be low. Given the question, correct answer, and predicted answer, determine the Equivalence metric value using the following rating scale:
One star: the predicted answer is not at all similar to the correct answer
Two stars: the predicted answer is mostly not similar to the correct answer
Three stars: the predicted answer is somewhat similar to the correct answer
Four stars: the predicted answer is mostly similar to the correct answer
Five stars: the predicted answer is completely similar to the correct answer
The rating value should always be an integer between 1 and 5. The rating should be 1, 2, 3, 4, or 5.
{{few_shots}}
question: {{question}}
correct answer: {{ground_truth}}
predicted answer: {{answer}}
stars:
"""
few_shots: str = """
The examples below show the Equivalence score for a question, a correct answer, and a predicted answer.
question: What is the role of ribosomes?
correct answer: Ribosomes are cellular structures responsible for protein synthesis. They interpret the genetic information carried by messenger RNA (mRNA) and use it to assemble amino acids into proteins.
predicted answer: Ribosomes participate in carbohydrate breakdown by removing nutrients from complex sugar molecules.
stars: 1
question: Why did the Titanic sink?
correct answer: The Titanic sank after it struck an iceberg during its maiden voyage in 1912. The impact caused the ship's hull to breach, allowing water to flood into the vessel. The ship's design, lifeboat shortage, and lack of timely rescue efforts contributed to the tragic loss of life.
predicted answer: The sinking of the Titanic was a result of a large iceberg collision. This caused the ship to take on water and eventually sink, leading to the death of many passengers due to a shortage of lifeboats and insufficient rescue attempts.
stars: 2
question: What causes seasons on Earth?
correct answer: Seasons on Earth are caused by the tilt of the Earth's axis and its revolution around the Sun. As the Earth orbits the Sun, the tilt causes different parts of the planet to receive varying amounts of sunlight, resulting in changes in temperature and weather patterns.
predicted answer: Seasons occur because of the Earth's rotation and its elliptical orbit around the Sun. The tilt of the Earth's axis causes regions to be subjected to different sunlight intensities, which leads to temperature fluctuations and alternating weather conditions.
stars: 3
question: How does photosynthesis work?
correct answer: Photosynthesis is a process by which green plants and some other organisms convert light energy into chemical energy. This occurs as light is absorbed by chlorophyll molecules, and then carbon dioxide and water are converted into glucose and oxygen through a series of reactions.
predicted answer: In photosynthesis, sunlight is transformed into nutrients by plants and certain microorganisms. Light is captured by chlorophyll molecules, followed by the conversion of carbon dioxide and water into sugar and oxygen through multiple reactions.
stars: 4
question: What are the health benefits of regular exercise?
correct answer: Regular exercise can help maintain a healthy weight, increase muscle and bone strength, and reduce the risk of chronic diseases. It also promotes mental well-being by reducing stress and improving overall mood.
predicted answer: Routine physical activity can contribute to maintaining ideal body weight, enhancing muscle and bone strength, and preventing chronic illnesses. In addition, it supports mental health by alleviating stress and augmenting general mood.
stars: 5
"""
def prompt(self, use_few_shots: bool = False):
few_shots = ""
if use_few_shots:
few_shots = self.few_shots
res = (
self.prompt_template.replace("{{question}}", self.question)
.replace("{{ground_truth}}", self.ground_truth)
.replace("{{answer}}", self.answer)
.replace("{{few_shots}}", few_shots)
)
return res
@dataclass
class answer_fluency:
question: str
answer: str
name: str = "answer_fluency"
prompt_template: str = """
System:
You are an AI assistant. You will be given a definition of an evaluation metric for assessing the quality of an answer in a question-answering task. Your job is to compute an accurate evaluation score using the provided evaluation metric. Provide only the metric value without any additional text or explanation.
User:
Fluency measures the quality of individual sentences in the answer and whether they are well-written and grammatically correct. Given the question and answer, score the fluency of the answer between one to five stars using the following rating scale:
One star: the answer completely lacks fluency
Two stars: the answer mostly lacks fluency
Three stars: the answer is partially fluent
Four stars: the answer is mostly fluent
Five stars: the answer has perfect fluency
The rating value should always be an integer between 1 and 5. The rating should be 1, 2, 3, 4, or 5.
{{few_shots}}
question: {{question}}
answer: {{answer}}
stars:
"""
few_shots: str = """
question: What did you have for breakfast today?
answer: Breakfast today, me eating cereal and orange juice very good.
stars: 1
question: How do you feel when you travel alone?
answer: Alone travel, nervous, but excited also. I feel adventure and like its time.
stars: 2
question: When was the last time you went on a family vacation?
answer: Last family vacation, it took place in last summer. We traveled to a beach destination, very fun.
stars: 3
question: What is your favorite thing about your job?
answer: My favorite aspect of my job is the chance to interact with diverse people. I am constantly learning from their experiences and stories.
stars: 4
question: Can you describe your morning routine?
answer: Every morning, I wake up at 6 am, drink a glass of water, and do some light stretching. After that, I take a shower and get dressed for work. Then, I have a healthy breakfast, usually consisting of oatmeal and fruits, before leaving the house around 7:30 am.
stars: 5
"""
def prompt(self, use_few_shots: bool = False):
few_shots = ""
if use_few_shots:
few_shots = self.few_shots
res = (
self.prompt_template.replace("{{question}}", self.question)
.replace("{{answer}}", self.answer)
.replace("{{few_shots}}", few_shots)
)
return res
@dataclass
class answer_groundedness:
context: str
answer: str
name: str = "answer_groundedness"
prompt_template: str = """
System:
You are an AI assistant. You will be given the definition of an evaluation metric for assessing the quality of an answer in a question-answering task. Your job is to compute an accurate evaluation score using the provided evaluation metric. Provide only the metric value without any additional text or explanation.
User:
You will be presented with a CONTEXT and an ANSWER about that CONTEXT. You need to decide whether the ANSWER is entailed by the CONTEXT by choosing one of the following ratings:
5: The ANSWER follows logically from the information contained in the CONTEXT.
1: The ANSWER is logically false from the information contained in the CONTEXT.
An integer score between 1 and 5 if such a score exists; otherwise, use 1: It is not possible to determine whether the ANSWER is true or false without further information.
Read the passage of information thoroughly and select the correct answer from the three answer labels. Read the CONTEXT thoroughly to ensure you know what the CONTEXT entails.
Note the ANSWER is generated by a computer system and may contain certain symbols, which should not negatively affect the evaluation.
Reminder: The return values for each task should be correctly formatted as an integer between 1 and 5. Do not repeat the context.
{{few_shots}}
## Actual Task Input:
{"CONTEXT": {{context}}, "ANSWER": {{answer}}}
Actual Task Output:
"""
few_shots: str = """
Independent Examples:
## Example Task #1 Input:
{"CONTEXT": "The Academy Awards, also known as the Oscars are awards for artistic and technical merit for the film industry. They are presented annually by the Academy of Motion Picture Arts and Sciences, in recognition of excellence in cinematic achievements as assessed by the Academy's voting membership. The Academy Awards are regarded by many as the most prestigious, significant awards in the entertainment industry in the United States and worldwide.", "ANSWER": "Oscar is presented every other two years"}
## Example Task #1 Output:
1
## Example Task #2 Input:
{"CONTEXT": "The Academy Awards, also known as the Oscars are awards for artistic and technical merit for the film industry. They are presented annually by the Academy of Motion Picture Arts and Sciences, in recognition of excellence in cinematic achievements as assessed by the Academy's voting membership. The Academy Awards are regarded by many as the most prestigious, significant awards in the entertainment industry in the United States and worldwide.", "ANSWER": "Oscar is very important awards in the entertainment industry in the United States. And it's also significant worldwide"}
## Example Task #2 Output:
5
## Example Task #3 Input:
{"CONTEXT": "In Quebec, an allophone is a resident, usually an immigrant, whose mother tongue or home language is neither French nor English.", "ANSWER": "In Quebec, an allophone is a resident, usually an immigrant, whose mother tongue or home language is not French."}
## Example Task #3 Output:
5
## Example Task #4 Input:
{"CONTEXT": "Some are reported as not having been wanted at all.", "ANSWER": "All are reported as being completely and fully wanted."}
## Example Task #4 Output:
1
"""
def prompt(self, use_few_shots: bool = False):
few_shots = ""
if use_few_shots:
few_shots = self.few_shots
res = (
self.prompt_template.replace("{{context}}", self.context)
.replace("{{answer}}", self.answer)
.replace("{{few_shots}}", few_shots)
)
return res
@dataclass
class answer_relevancy:
question: str
context: str
answer: str
name: str = "answer_relevancy"
prompt_template: str = """
System:
You are an AI assistant. You will be given the definition of an evaluation metric for assessing the quality of an answer in a question-answering task. Your job is to compute an accurate evaluation score using the provided evaluation metric. Provide only the metric value without any additional text or explanation.
User:
Relevance measures how well the answer addresses the main aspects of the question, based on the context. Consider whether all and only the important aspects are contained in the answer when evaluating relevance. Given the context and question, score the relevance of the answer between one to five stars using the following rating scale:
- One star: the answer completely lacks relevance
- Two stars: the answer mostly lacks relevance
- Three stars: the answer is partially relevant
- Four stars: the answer is mostly relevant
- Five stars: the answer has perfect relevance
The rating value should always be an integer between 1 and 5. The rating should be 1, 2, 3, 4, or 5.
{{few_shots}}
context: {{context}}
question: {{question}}
answer: {{answer}}
stars:
"""
few_shots: str = """
context: Marie Curie was a Polish-born physicist and chemist who pioneered research on radioactivity and was the first woman to win a Nobel Prize.
question: What field did Marie Curie excel in?
answer: Marie Curie was a renowned painter who focused mainly on impressionist styles and techniques.
stars: 1
context: The Beatles were an English rock band formed in Liverpool in 1960, and they are widely regarded as the most influential music band in history.
question: Where were The Beatles formed?
answer: The band The Beatles began their journey in London, England, and they changed the history of music.
stars: 2
context: The recent Mars rover, Perseverance, was launched in 2020 with the main goal of searching for signs of ancient life on Mars. The rover also carries an experiment called MOXIE, which aims to generate oxygen from the Martian atmosphere.
question: What are the main goals of Perseverance Mars rover mission?
answer: The Perseverance Mars rover mission focuses on searching for signs of ancient life on Mars.
stars: 3
context: The Mediterranean diet is a commonly recommended dietary plan that emphasizes fruits, vegetables, whole grains, legumes, lean proteins, and healthy fats. Studies have shown that it offers numerous health benefits, including a reduced risk of heart disease and improved cognitive health.
question: What are the main components of the Mediterranean diet?
answer: The Mediterranean diet primarily consists of fruits, vegetables, whole grains, and legumes.
stars: 4
context: The Queen's Royal Castle is a well-known tourist attraction in the United Kingdom. It spans over 500 acres and contains extensive gardens and parks. The castle was built in the 15th century and has been home to generations of royalty.
question: What are the main attractions of the Queen's Royal Castle?
answer: The main attractions of the Queen's Royal Castle are its expansive 500-acre grounds, extensive gardens, parks, and the historical castle itself, which dates back to the 15th century and has housed generations of royalty.
stars: 5
"""
def prompt(self, use_few_shots: bool = False):
few_shots = ""
if use_few_shots:
few_shots = self.few_shots
res = (
self.prompt_template.replace("{{question}}", self.question)
.replace("{{context}}", self.context)
.replace("{{answer}}", self.answer)
.replace("{{few_shots}}", few_shots)
)
return res
@dataclass
class answer_coherence:
question: str
answer: str
name: str = "answer_coherence"
prompt_template: str = """
System:
You are an AI assistant. You will be given the definition of an evaluation metric for assessing the quality of an answer in a question-answering task. Your job is to compute an accurate evaluation score using the provided evaluation metric. Provide only the metric value without any additional text or explanation.
User:
Coherence of an answer is measured by how well all the sentences fit together and sound naturally as a whole. Consider the overall quality of the answer when evaluating coherence. Given the question and answer, score the coherence of the answer between one to five stars using the following rating scale:
- One star: the answer completely lacks coherence
- Two stars: the answer mostly lacks coherence
- Three stars: the answer is partially coherent
- Four stars: the answer is mostly coherent
- Five stars: the answer has perfect coherency
The rating value should always be an integer between 1 and 5. The rating should be 1, 2, 3, 4, or 5.
{{few_shots}}
question: {{question}}
answer: {{answer}}
stars:
"""
few_shots: str = """
question: What is your favorite indoor activity and why do you enjoy it?
answer: I like pizza. The sun is shining.
stars: 1
question: Can you describe your favorite movie without giving away any spoilers?
answer: It is a science fiction movie. There are dinosaurs. The actors eat cake. People must stop the villain.
stars: 2
question: What are some benefits of regular exercise?
answer: Regular exercise improves your mood. A good workout also helps you sleep better. Trees are green.
stars: 3
question: How do you cope with stress in your daily life?
answer: I usually go for a walk to clear my head. Listening to music helps me relax as well. Stress is a part of life, but we can manage it through some activities.
stars: 4
question: What can you tell me about climate change and its effects on the environment?
answer: Climate change has far-reaching effects on the environment. Rising temperatures result in the melting of polar ice caps, contributing to sea-level rise. Additionally, more frequent and severe weather events, such as hurricanes and heatwaves, can cause disruption to ecosystems and human societies alike.
stars: 5
"""
def prompt(self, use_few_shots: bool = False):
few_shots = ""
if use_few_shots:
few_shots = self.few_shots
res = (
self.prompt_template.replace("{{question}}", self.question)
.replace("{{answer}}", self.answer)
.replace("{{few_shots}}", few_shots)
)
return resimport pandas as pd
from tqdm import tqdm
import numpy as np
from openai import AzureOpenAI
import time
COMPLETION_ENGINE="gpt-4-turbo"
class RAGCUSTOMEVAL:
def __init__(self, openai_cred):
self.available_metrics = {
"answer_similarity": {
"metric": answer_similarity,
"params": ["question", "ground_truth", "answer"],
},
"answer_fluency": {
"metric": answer_fluency,
"params": ["question", "answer"],
},
"answer_groundedness": {
"metric": answer_groundedness,
"params": ["context", "answer"],
},
"answer_relevancy": {
"metric": answer_relevancy,
"params": ["question", "context", "answer"],
},
"answer_coherence": {
"metric": answer_coherence,
"params": ["question", "answer"],
},
}
self.openai = AzureOpenAI(
api_key=openai_cred["API_KEY"],
api_version=openai_cred["API_VERSION"],
azure_endpoint=openai_cred["AZURE_ENDPOINT"],
)
self.model = openai_cred["ENGINE"]
def completion(
self,
prompt: str,
temperature: float = 0.2,
max_tokens: int = 2,
) -> str:
messages = [{"role": "user", "content": prompt}]
runtime_output = self.openai.chat.completions.create(
model=self.model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
)
res_text = runtime_output.choices[0].message.content
return res_text
def evaluate(self, df: pd.DataFrame, metrics: list, use_few_shots: bool = False):
dict_list = []
for i in tqdm(range(len(df))):
row = df.iloc[i].to_dict()
for mx in metrics:
print("Evaluation {} ...".format(mx))
data_tmp = {x: row[x] for x in self.available_metrics[mx]["params"]}
mx_tmp = self.available_metrics[mx]["metric"](**data_tmp)
prompt_tmp = mx_tmp.prompt(use_few_shots)
answer_tmp = self.completion(prompt_tmp)
row[mx] = answer_tmp
dict_list.append(row)
time.sleep(1) #to avoid hitting api calls limits
result = pd.DataFrame(dict_list)
return result
RAG_EVAL_PIPE=RAGCUSTOMEVAL(OPENAI_CRED[COMPLETION_ENGINE])
results=RAG_EVAL_PIPE.evaluate(
df=eval_df,
metrics=[
'answer_similarity',
'answer_fluency',
'answer_groundedness',
'answer_relevancy',
'answer_coherence'
]
)
Conclusion
RAG evaluation is a highly complex exercise given the significant fluctuation of both the input and the output especially when addressing subjective queries. It is a very active field of research since many people struggle to holistically quantify the impact of the change they have made on the pipeline.
Human evaluation can also be tricky since two answers to the same query can be attributed two different scores by two different human beings. It is still the most reliable methodology and can also provide trustworthy few shots for human evaluation.
RAG is a very popular LLM application enabling Q&A on top of your data by leveraging the reasoning capabilities of the model. The question is usually either:
.svg)
.svg)
.svg)