
RAG, for Retrieval Augmented Generation, pipelines are one of the most famous and trending applications of LLMs nowadays, the main idea is to answer a question from one or multiple sources of information (PDF, Excel, Drive, SharePoint, …) by leveraging the reasoning capabilities of the large language model which knowledge has a cut off date.
The question can either be:
- Objective: true-false, multiple-choice, exact words-number …, mainly used in key points extraction pipelines.
- Subjective: short-elaborated paragraph used in general Q&A use-cases
In this article, we will go through the different steps of building a vanilla RAG pipeline and enhancing it by plugging additional modules linked to both the retriever and the generator(see next section).
In the next one, we will cover the evaluation of the RAG pipeline following a TDD (Test Driven Development) and MDD (Metric Driven Development).
The summary is as follows:
- RAG Pipeline
- Enhancement
RAG Pipeline
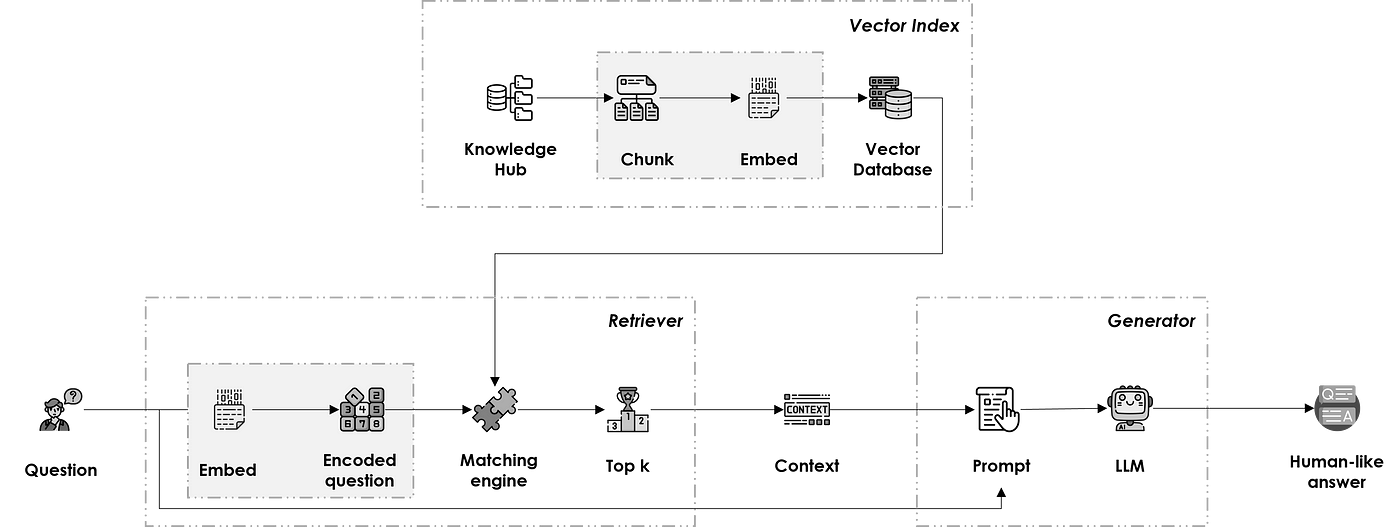
The RAG pipeline is composed of three main components: Vector Index, Retriever, and Generator.
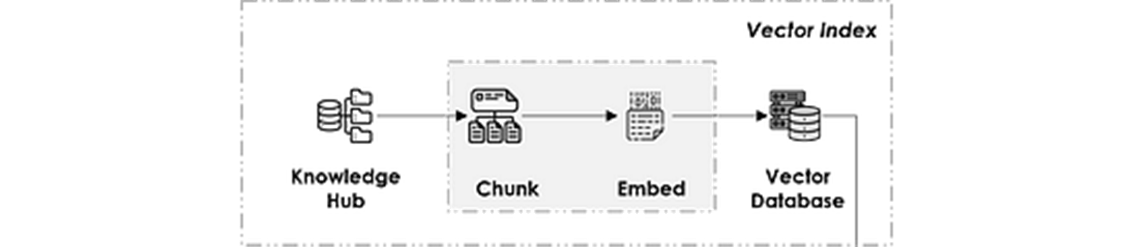
Vector Index
It stands for the knowledge hub from which the information is pulled. It is built following the steps below:
- Data collection
- Data cleaning: following the simple principle of “garbage in, garbage out”
- Data chunking: splitting the data into small sections (page/paragraph-wise for example) as the LLM can only ingest a determined number of tokens known as the context size.
- Data embedding: which transforms the text into a vectorial semantical representation for later matching using an embedding model (Openai ada-002 being the most famous one).
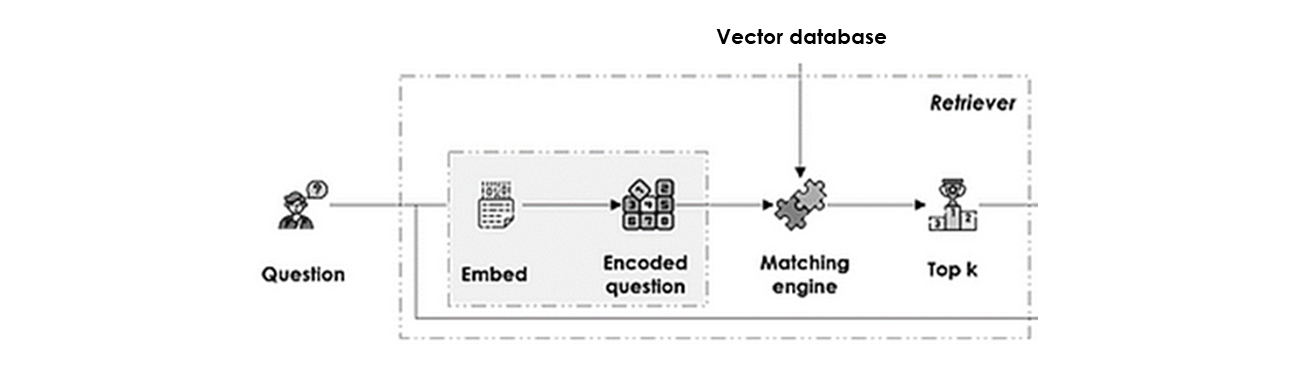
Retriever
It matches the question with the right chunk of the knowledge hub by:
- Question encoding: to represent the question in the same vectorial space as the source data using the same embedding model.
- Semantical Matching: of question’s embedding with the vector index, using cosine similarity metric for example, and returns the top k most similar contexts.
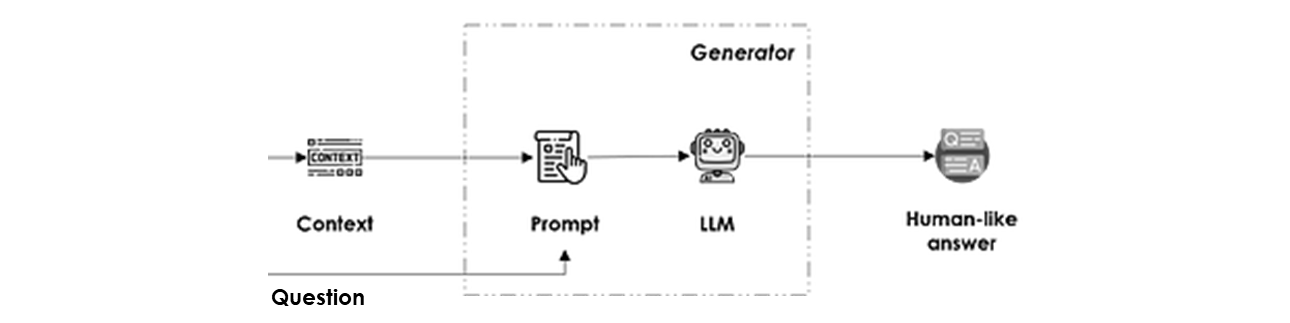
Generator
It returns a human-like answer to the question based on the selected context in two consecutive steps:
- Prompt generation: this step consists of creating a set of instructions to fully leverage the LLM’s reasoning capabilities by explicitly specifying the question and the context from which the information should be extracted. It is also used to determine the tone/style of the generated language along with the expected format of the output (text, json, yaml, …).
We can also add the last n historical interactions between the user and the system for chat dialogues providing that these interactions can fit within the context window. - LLM completion: in other words the output of the LLM inference on the generated prompt
Enhancement
The vanilla RAG pipeline described above may suffer from multiple issues: low precision/recall with the retrieval, hallucination with the generator, …etc.
To mitigate the risks above, multiple steps can be added to the pipeline in order to ensure better information retrieval and answer generation.
Vector Indexing
- Modular parsing: of text, tables and images
- Optimize the chunking strategy: custom chunking by section, subsection, …
- Optimize the index structure: by adding a hierarchy
- Additional Metadata: describing the content for the sections. Matching on this metadata at first might be a good noise filter.
Retriever
- Question rewriting: to correct the grammatical structure of the question as most of the embedding models have been trained on clean data. This also helps align the question with the LLM’s language structure.
- Embedding fine-tuning: which can be very useful when dealing with domain-heavy contexts
- Use of dynamic embedding: where the generated vector depends on the additional instruction given the embedding model
- Reranking: Diversity Ranker, Lost in the Middle Ranker for example. This technique has proven to be very efficient in enhancing the retrieval’s precision
- Hybrid Retrieval: BM25 & embedding for use cases where keywords matter
- Prompt compression: delete noise from the retrieved text and keep the essence of the required information from the chunk. By doing so, it also shrinks the size of the context and allows more information to be processed within the same context window.
Generation
- Prompt engineering: is the art of developing a prompt that meets the expected level of output
- Finetuned open-source LLMs: a heavy task that requires building a dataset (usually with question, context, and answer) to finetune the trained language model. This methodology allows it to capture both the style and the knowledge from the training set.
Conclusion
RAG is a very popular and powerful architecture nowadays given its significant benefits. It can easily be scaled to more knowledge and thus adapt to the potential version changes in the existing one. It can also adapt to multiple types of data and queries by leveraging the concept of agents.
Agents can be considered as multiple operators specialized in a task or field, which makes them more accurate, and act when necessary through a routing chain of thoughts.
In the next article, we will be discussing the evaluation of the RAG pipeline and the different frameworks that can be leveraged for this purpose.