
La computer vision est un sous-domaine du deep learning qui traite des images à toutes les échelles. Elle permet à l'ordinateur de traiter et de comprendre le contenu d'un grand nombre d'images grâce à un processus automatique.
L'architecture principale derrière la computer vision est le convolutional neural network, qui est un dérivé des feedforward neural networks. Ses applications sont très variées telles que la classification d'images, la détection d'objets, le neural style transfer, l'identification de visages, etc. Si vous n'avez aucune base en deep learning en général, je vous recommande de lire d'abord mon article sur les feedforward neural networks.
NB : Medium ne supportant pas LaTeX, les expressions mathématiques sont insérées sous forme d'images. Je vous conseille donc de désactiver le mode sombre pour une meilleure expérience de lecture.
Le sommaire est le suivant :
- Traitement par filtre
- Définitions
- Fondamentaux
- Entraînement du CNN
- Architectures courantes
Traitement par filtre
Le premier traitement d'images était basé sur des filtres permettant, par exemple, d'obtenir les contours d'un objet dans une image en utilisant la combinaison de filtres vertical-edge et horizontal-edge.
Mathématiquement parlant, le vertical edge filter, VEF, est défini comme suit :
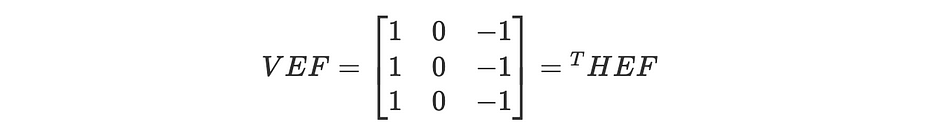
Où HEF désigne le horizontal edge filter.
Pour simplifier, nous considérons une image A en niveaux de gris de 6x6, une matrice 2D où la valeur de chaque élément représente la quantité de lumière dans le pixel correspondant.
Afin d'extraire les contours verticaux de cette image, nous effectuons un convolutional product (⋆) qui est essentiellement la somme du elementwise product dans chaque bloc :
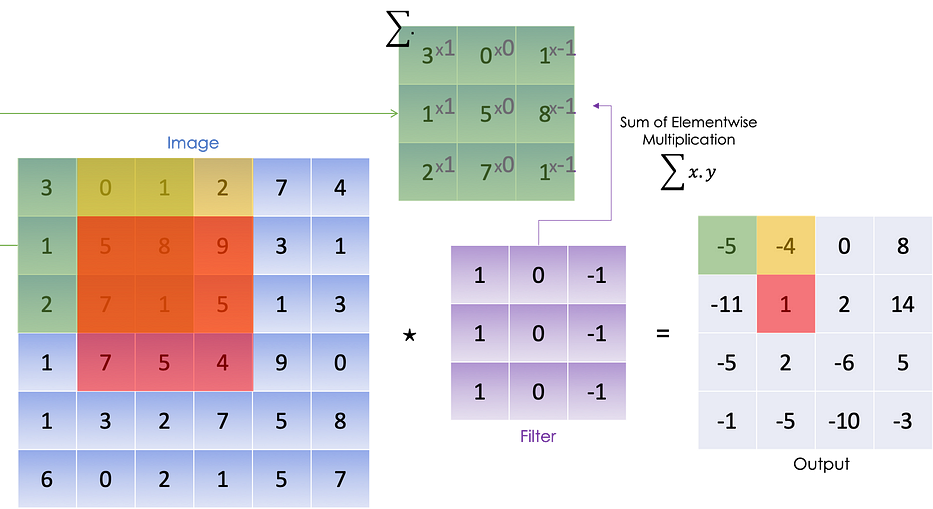
Nous effectuons la multiplication elementwise sur le premier bloc 3x3 de l'image, puis nous considérons le bloc suivant à droite et faisons la même chose jusqu'à avoir couvert tous les blocs potentiels.
Nous pouvons résumer le processus suivant en :

Étant donné cet exemple, nous pouvons envisager d'utiliser le même processus pour any objective où le filter is learned par un neural network comme suit :
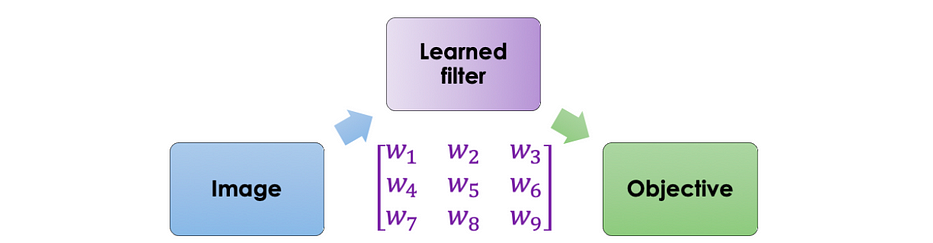
L'intuition principale est de définir un neural network qui prend l'image en entrée et renvoie une cible définie. Les paramètres sont appris en utilisant la backpropagation.
Définition
Un convolutional neural network est une série de couches convolutionnelles et de pooling qui permet d'extraire les features principales des images répondant le mieux à l'objectif final.
Dans la section suivante, nous détaillerons chaque brique avec ses équations mathématiques.
Produit de convolution
Avant de définir explicitement le produit de convolution, nous commencerons par définir certaines opérations de base telles que le padding et le stride.
Padding
Comme nous l'avons vu dans le produit convolutionnel utilisant le vertical-edge filter, les pixels au coin de l'image (matrice 2D) sont moins utilisés que les pixels au milieu de l'image, ce qui signifie que l'information des bords est rejetée.
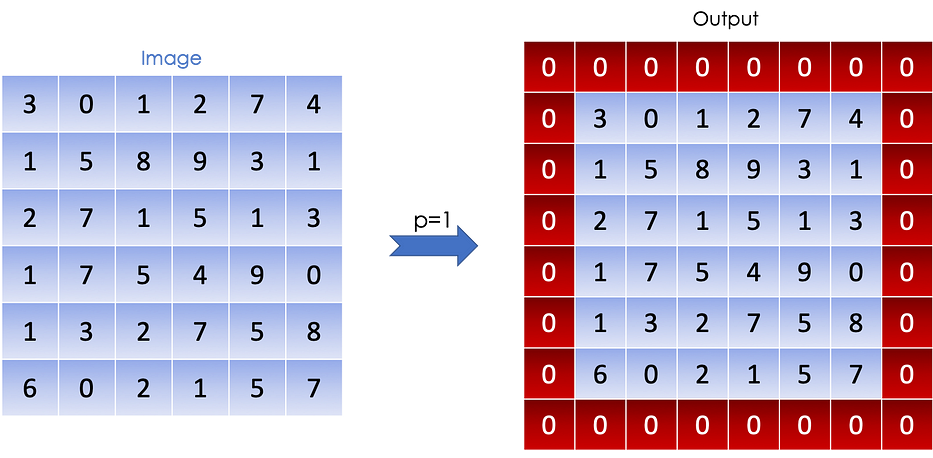
Pour résoudre ce problème, nous ajoutons souvent du padding autour de l'image afin de prendre en compte les pixels des bords. Par convention, nous padde avec des zeros et notons p le paramètre de padding qui représente le nombre d'éléments ajoutés sur chacun des quatre côtés de l'image.
L'image suivante illustre le padding d'une image en niveaux de gris (matrice 2D) où p=1 :
Stride
Le stride est le pas effectué dans le produit convolutionnel. Un large stride permet de réduire la taille de la sortie et vice-versa. Nous notons s le paramètre de stride.
L'image suivante illustre un produit convolutionnel (somme de element-wise element par bloc) avec s=1 :
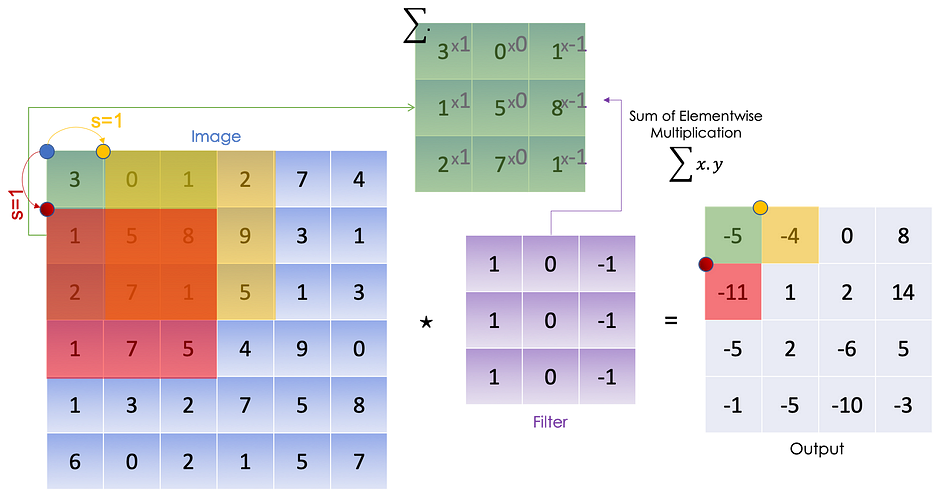
Convolution
Une fois le stride et le padding définis, nous pouvons définir le produit de convolution entre un tenseur et un filtre.
Après avoir précédemment défini le produit de convolution sur une matrice 2D qui est la somme du element-wise product, nous pouvons maintenant définir formellement le produit de convolution sur un volume.
Une image, en général, peut être représentée mathématiquement comme un tenseur avec les dimensions suivantes :
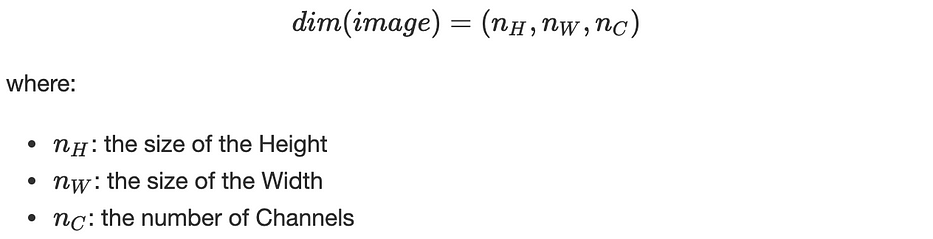
Dans le cas d'une image RGB, par exemple, n_C=3, nous avons Red, Green et Blue. Par convention, nous considérons que le filtre K est squared et a une odd dimension notée f, ce qui permet à chaque pixel d'être centré dans le filtre et donc de considérer tous les éléments qui l'entourent.
Lors de l'opération du produit convolutionnel, le filter/kernel K doit avoir le same number of channels que l'image, ainsi nous appliquons un filtre différent à chaque channel. Ainsi la dimension du filtre est la suivante :
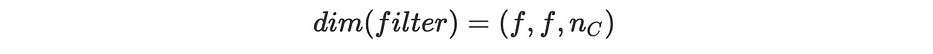
Le convolutional product entre l'image et le filtre est une 2D matrix où chaque élément est la somme de la multiplication elementwise du cube (filtre) et du sous-cube de l'image donnée, comme illustré ci-dessous :
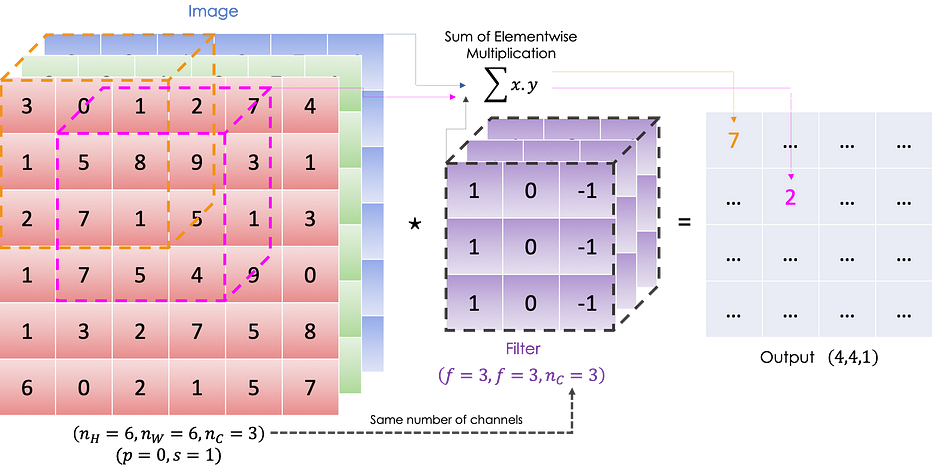
Mathématiquement parlant, pour une image et un filtre donnés, nous avons :
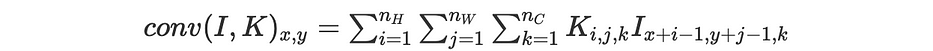
En gardant les mêmes notations qu'auparavant, nous avons :

Pooling
C'est l'étape de downsampling des features de l'image en résumant l'information. L'opération est effectuée à travers chaque channel et n'affecte donc que les dimensions (n_H, n_W) et préserve n_C intact.
Étant donné une image, nous faisons glisser un filtre, sans no parameters à apprendre, suivant un certain stride, et nous appliquons une fonction sur les éléments sélectionnés. Nous avons :
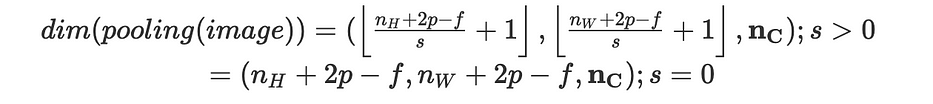
Par convention, nous considérons un filtre carré de taille f et nous fixons généralement f=2 et considérons s=2.
Nous appliquons souvent :
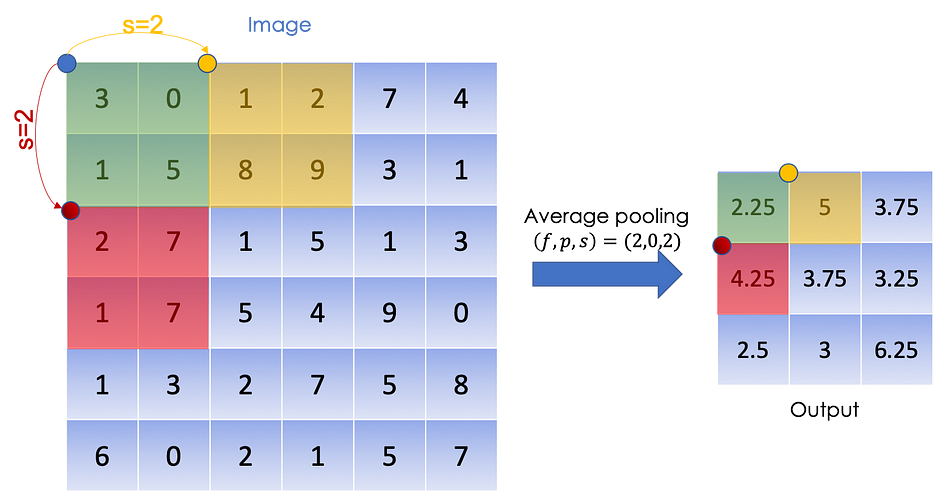
Average pooling: nous moyennons sur les éléments présents dans le filtreMax pooling: étant donné tous les éléments du filtre, nous renvoyons le maximum
Ci-dessous, une illustration d'un average pooling :
Fondamentaux
Dans cette section, nous combinerons toutes les opérations définies ci-dessus pour construire un convolutional neural network, couche par couche.
Une couche d'un CNN
Chaque couche du convolutional neural network peut être :
Convolutional layer -CONV-suivie d'uneactivation functionPooling layer -POOL-comme détaillé ci-dessusFully connected layer -FC-une couche qui est essentiellement similaire à celle d'un feedforward neural network,
Vous pouvez avoir plus de détails sur les fonctions d'activation et la fully connected layer dans mon post précédent.
• Convolutional layer
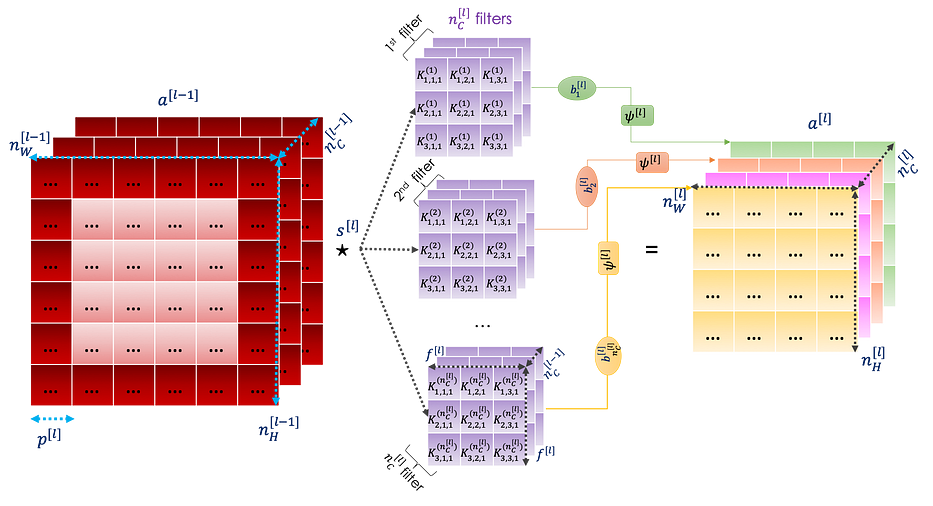
Comme vu précédemment, au niveau de la convolutional layer, nous appliquons des convolutional products, en utilisant cette fois plusieurs filtres, sur l'entrée suivi d'une fonction d'activation ψ.

Nous pouvons résumer la convolutional layer dans le graphique suivant :
• Pooling layer
Comme mentionné précédemment, la pooling layer vise à downsampler les features de l'entrée sans impacter le nombre de channels.
Nous considérons la notation suivante :
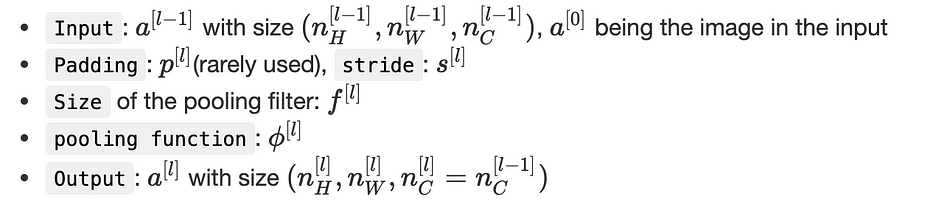
Nous pouvons affirmer que :
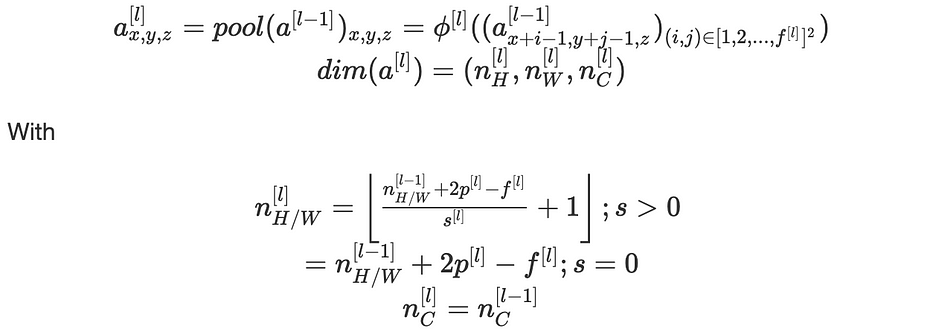
La pooling layer n'a no parameters à apprendre.
Nous résumons les opérations précédentes dans l'illustration suivante :
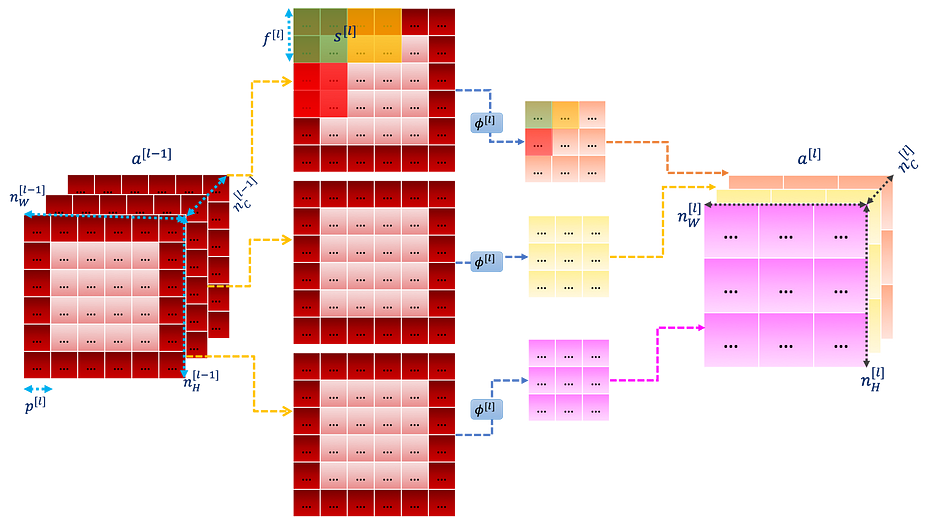
• Fully connected layer
Une fully connected layer est un nombre fini de neurones qui prend en entrée un vecteur et renvoie un autre.

Nous résumons la fully connected layer dans l'illustration suivante :
Pour plus de détails, vous pouvez visiter mon article précédent sur les feedforward neural networks.
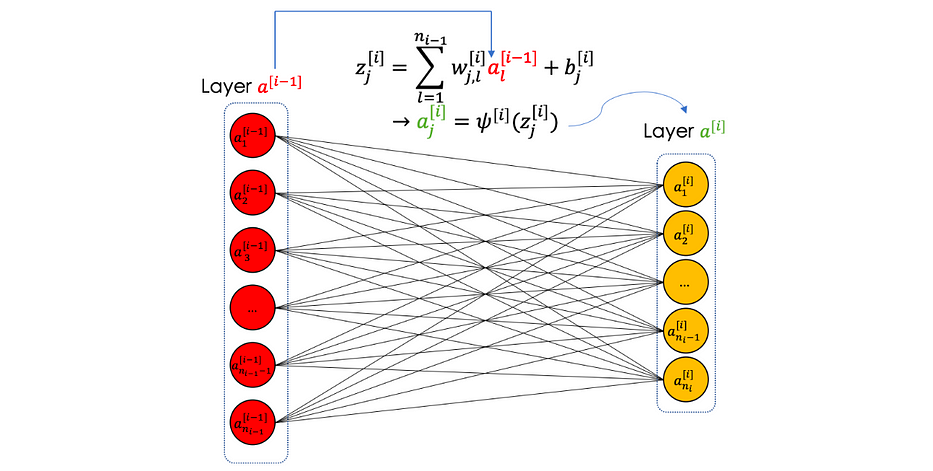
CNN dans son ensemble
En général, un convolutional neural network est une série de toutes les opérations décrites ci-dessus comme suit :
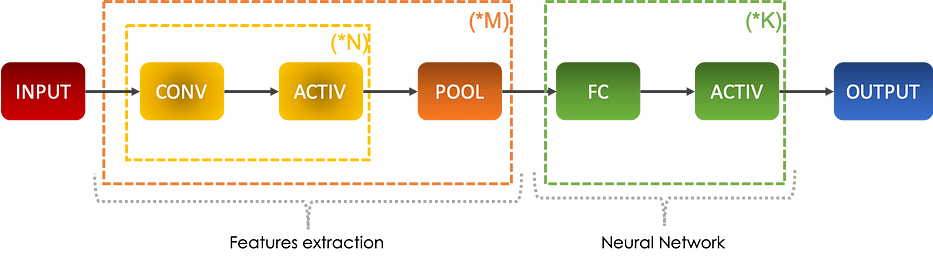
Après avoir répété une série de convolutions suivies de fonctions d'activation, nous appliquons un pooling et répétons ce processus un certain nombre de fois. Ces opérations permettent d'extract features de l'image qui seront fed à un neural network décrit par les fully connected layers, régulièrement suivies de fonctions d'activation également.
L'idée principale est de decrease n_H & n_W et d'increase n_C en s'enfonçant dans le réseau.
En 3D, un convolutional neural network a la forme suivante :
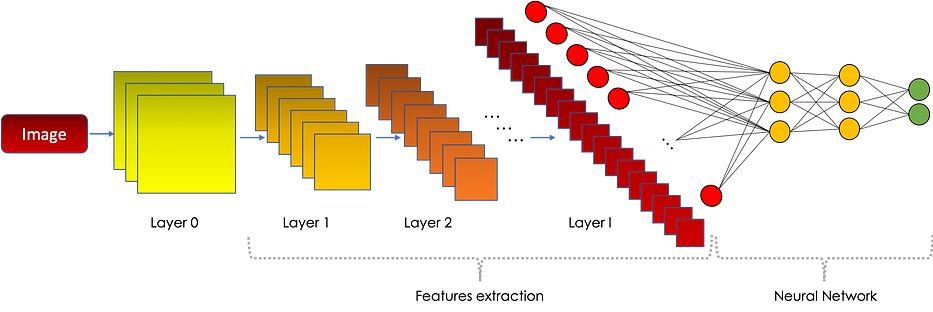
Pourquoi les CNN fonctionnent-ils efficacement ?
Les convolutional neural networks permettent d'obtenir l'état de l'art dans le traitement d'images pour deux raisons principales :
- Parameter sharing : un feature detector dans la convolutional layer qui est utile dans une partie de l'image peut être utile dans d'autres
- Sparsity of connections : dans chaque couche, chaque valeur de sortie ne dépend que d'un petit nombre d'entrées
Entraînement du CNN
Les convolutional neural networks sont entraînés sur un ensemble d'images labellisées. À partir d'une image donnée, nous la propageons à travers les différentes couches du CNN et renvoyons la sortie recherchée.
Dans ce chapitre, nous passerons en revue l'algorithme d'apprentissage ainsi que les différentes techniques utilisées dans la data augmentation.
Data preprocessing
Data augmentation est l'étape d'augmentation du nombre d'images dans un dataset donné. Il existe de nombreuses techniques utilisées dans la data augmentation telles que :
CroopingRotationFlippingNoise injectionColor space transformation
Elle permet un better learning grâce à la plus grande taille du training set et permet à l'algorithme d'apprendre à partir de différentes conditions de l'objet en question.
Une fois le dataset prêt, nous le splittons en trois parties comme tout projet de machine learning :
- Train set : utilisé pour entraîner l'algorithme et construire des batches
- Dev set : utilisé pour finetuner l'algorithme et évaluer le bias et la variance
- Test set : utilisé pour généraliser l'erreur/la précision de l'algorithme final
Algorithme d'apprentissage
Les convolutional neural networks sont un type particulier de neural networks spécialisés dans les images. L'apprentissage dans les neural networks, en général, est l'étape de calcul des poids des paramètres définis ci-dessus dans plusieurs couches.
En d'autres termes, nous cherchons à trouver les meilleurs paramètres qui donnent la meilleure prédiction/approximation, à partir de l'image d'entrée, de la valeur réelle.
Pour cela, nous définissons une fonction objectif appelée loss function et notée J qui quantifie la distance entre les valeurs réelles et prédites sur l'ensemble du training set.
Nous minimisons J en suivant deux étapes majeures :
Forward Propagation: nous propageons les données à travers le réseau soit entièrement, soit par batches, et nous calculons la loss function sur ce batch qui n'est autre que la somme des erreurs commises à la prédiction de sortie pour les différentes lignes.Backpropagation: consiste à calculer les gradients de la cost function par rapport aux différents paramètres, puis à appliquer un algorithme de descente pour les mettre à jour.
Nous itérons le même processus un certain nombre de fois appelé epoch number. Après avoir défini l'architecture, l'algorithme d'apprentissage s'écrit comme suit :

(*) La cost function évalue les distances entre la valeur réelle et prédite sur un seul point.
Pour plus de détails, vous pouvez visiter mon article précédent sur les feedforward neural networks.
Architectures courantes
Resnet
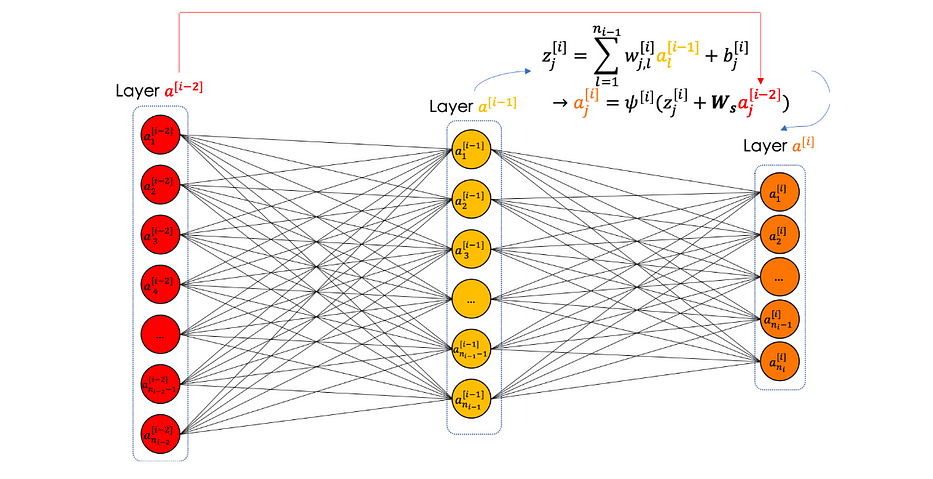
Un Resnet, short cut ou skip connection est une convolutional layer qui prend en compte la couche n-2 au niveau de la couche n. L'intuition vient du fait que lorsque les neural networks deviennent très profonds, la précision en sortie devient très stable et n'augmente plus. Injecter des résidus de la couche précédente aide à résoudre ce problème.
Considérons un residual block, lorsque la skip connection est off, nous avons les équations suivantes :

Nous pouvons résumer le residual block dans l'illustration suivante :
Inception Networks
Lors de la conception d'un convolutional neural network, nous devons souvent choisir le type de couche : CONV, POOL ou FC. La couche inception les fait tous. Le résultat de toutes les opérations est ensuite concatenated dans un seul bloc qui sera l'entrée de la couche suivante comme suit :
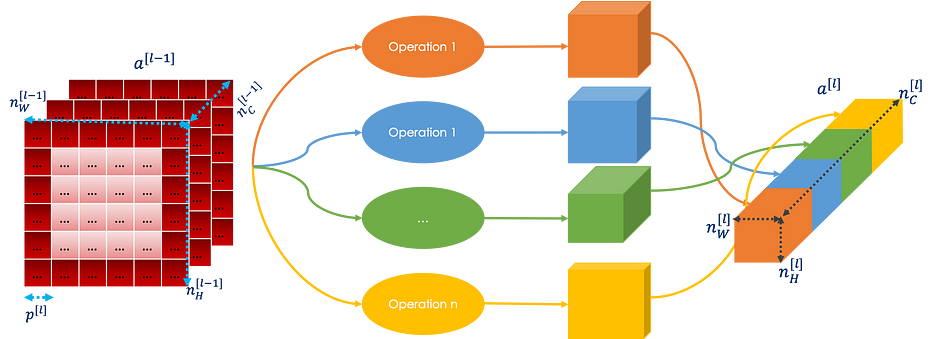
Il est important de noter que la couche inception soulève le problème du computational cost. Pour information, le nom inception vient du film !
Conclusion
Dans la première partie de cet article, nous avons vu les fondamentaux des CNN, des produits convolutionnels, du pooling/fully connected layers à l'algorithme d'entraînement.
Dans la seconde partie, nous discuterons de certaines des architectures les plus célèbres utilisées dans le traitement d'images.
N'hésitez pas à consulter mes articles précédents traitant de :
- Les mathématiques du Deep Learning
- Algorithmes de détection d'objets & reconnaissance faciale
- Recurrent Neural Networks
Références
- Deep Learning Specialization, Coursera, Andrew Ng
- Machine Learning, Loria, Christophe Cerisara