
Le deep learning est un sous-domaine du Machine Learning Science qui est basé sur les réseaux de neurones artificiels. Il a plusieurs dérivés tels que le Multi-Layer Perceptron-MLP-, les Convolutional Neural Networks -CNN- et les Recurrent Neural Networks -RNN- qui peuvent être appliqués à de nombreux domaines incluant la Computer Vision, le Natural Language Processing, la traduction automatique...
Le deep learning prend son essor pour trois raisons principales :
- Features engineering instinctif : alors que la plupart des algorithmes de machine learning nécessitent une expertise humaine pour le feature engineering et l'extraction, le deep learning gère automatiquement le choix des variables et leurs poids
- Datasets énormes : la collecte continue de données a conduit à de grandes databases qui permettent des réseaux de neurones plus profonds
- Évolution du Hardware : les nouveaux GPUs, pour Graphical Process Units, permettent un calcul algébrique plus rapide qui est le socle de base du DL
Dans ce blog, nous nous concentrerons principalement sur le Multi-Layer Perceptron -MLP- où nous détaillerons le contexte mathématique derrière le succès du deep learning et explorerons les algorithmes d'optimisation utilisés pour améliorer ses performances.
Le sommaire est le suivant :
- Définition
- Algorithme d'apprentissage
- Initialisation des paramètres
- Forward, Backpropagation
- Fonctions d'activation
- Algorithme d'optimisation
NB : Medium ne supportant pas LaTeX, les expressions mathématiques sont insérées sous forme d'images. Je vous conseille donc de désactiver le mode sombre pour une meilleure expérience de lecture.
Définition
Un neurone
C'est un bloc d'opérations mathématiques liant des entités
Considérons le problème où nous estimons le prix d'une maison en fonction de sa taille, il peut être schématisé comme suit :
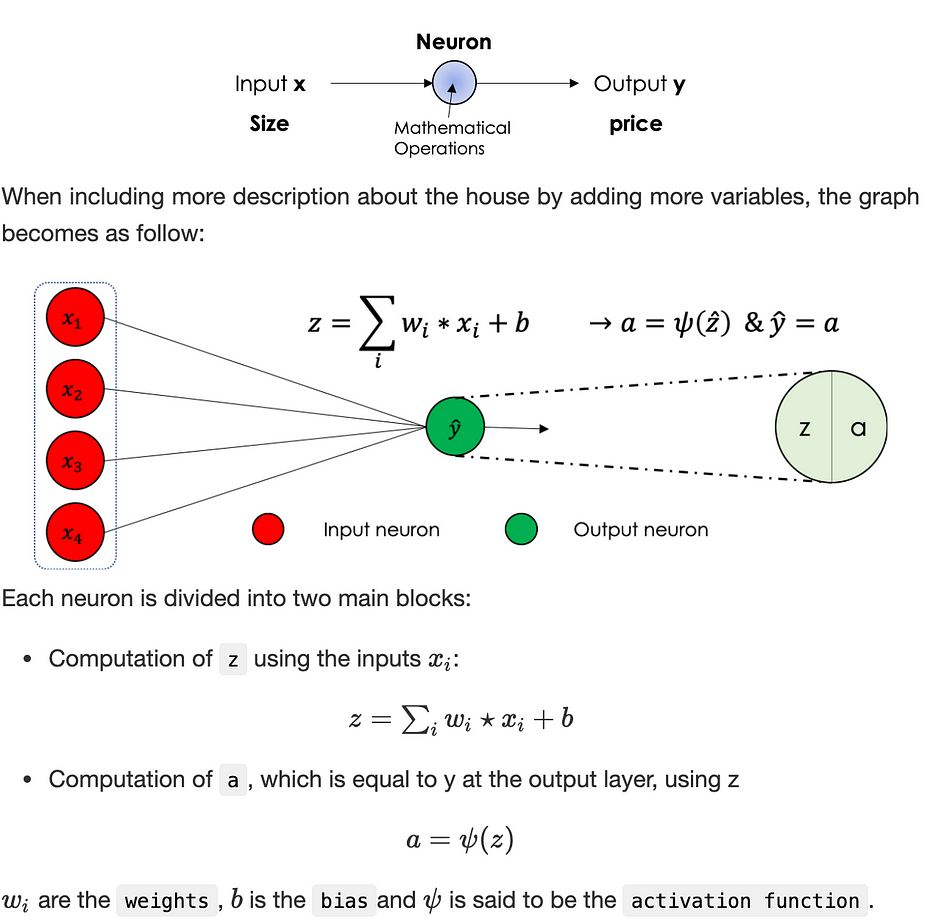
En général, les neural networks plus connus sous le nom de MLP, pour 'Multi Layers Perceptron', sont un type de réseau de neurones formel direct organisé en plusieurs couches dans lequel l'information circule de la couche d'entrée à la couche de sortie uniquement.
Chaque couche est composée d'un nombre défini de neurones, nous distinguons :
- La couche d'entrée
- Les couches cachées
- La couche de sortie
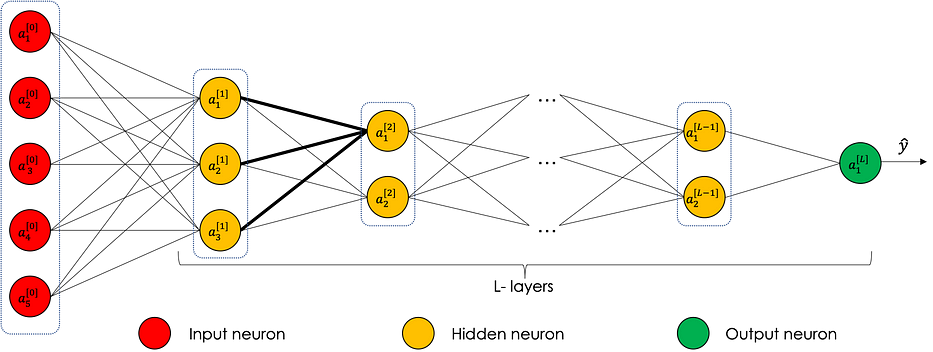
Le graphe suivant représente un neural network avec 5 neurones en entrée, 3 dans la première couche cachée, 3 dans la deuxième couche cachée et 2 en sortie.
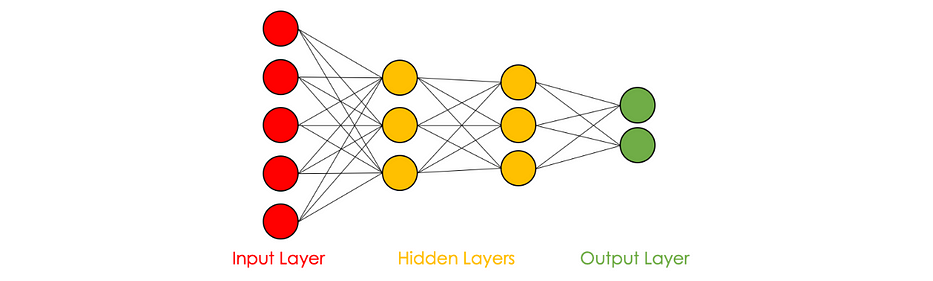
Certaines variables dans les couches cachées peuvent être interprétées en fonction des features d'entrée : dans le cas du pricing de maison et sous l'hypothèse que le premier neurone de la première couche cachée porte plus d'attention aux variables x_1 et x_2, il peut être interprété comme la quantification de la taille de la famille de la maison par exemple.
DL comme tâche supervisée
Dans la plupart des problèmes de DL, nous tendons à prédire une sortie y en utilisant un ensemble de variables X, dans ce cas, nous supposons que pour chaque ligne de la database X_i nous avons la prédiction correspondante y_i, donc des données labellisées.
Applications : Immobilier, Reconnaissance vocale, Classification d'images...
Les données utilisées peuvent être :
- Structurées : databases explicites avec features bien définies
- Non structurées : Audio, Image, Texte, ...
Théorème d'approximation universelle
Le deep learning dans la vie réelle est l'approximation d'une fonction donnée f. Cette approximation est possible et précise grâce au théorème suivant :

(*) En dimension finie, un ensemble est dit compact s'il est fermé et borné. Visitez ce link pour plus de détails.
Le principal enseignement de cet algorithme est que le deep learning permet de résoudre tout problème pouvant être exprimé mathématiquement
Data Preprocessing
Dans tout projet de machine learning en général, nous divisons nos données en 3 ensembles :
- Train set : utilisé pour entraîner l'algorithme et construire des batches
- Dev set : utilisé pour finetuner l'algorithme et évaluer le bias et la variance
- Test set : utilisé pour généraliser l'erreur/la précision de l'algorithme final
Le tableau suivant résume la répartition des trois ensembles selon la taille du dataset m :
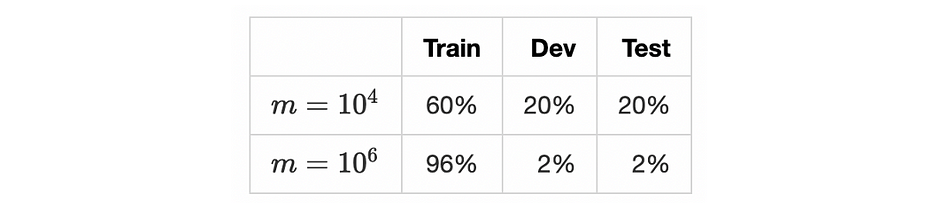
Les algorithmes de deep learning standard nécessitent un grand dataset où le nombre d'échantillons est de l'ordre de plusieurs lignes. Maintenant que les données sont prêtes, nous verrons dans la section suivante l'algorithme d'entraînement.
Généralement, avant de splitter les données, nous normalisons également les entrées, une étape détaillée plus loin dans cet article.
Algorithme d'apprentissage
L'apprentissage dans les neural networks est l'étape de calcul des poids des paramètres associés aux différentes régressions à travers le réseau. En d'autres termes, nous cherchons à trouver les meilleurs paramètres qui donnent la meilleure prédiction/approximation, à partir de l'entrée, de la valeur réelle.
Pour cela, nous définissons une fonction objectif appelée loss function et notée J qui quantifie la distance entre les valeurs réelles et prédites sur l'ensemble du training set.
Nous minimisons J en suivant deux étapes majeures :
- Forward Propagation : nous propageons les données à travers le réseau soit entièrement, soit par batches, et nous calculons la loss function sur ce batch qui n'est autre que la somme des erreurs commises à la prédiction de sortie pour les différentes lignes.
- Backpropagation : consiste à calculer les gradients de la cost function par rapport aux différents paramètres, puis à appliquer un algorithme de descente pour les mettre à jour.
Nous itérons le même processus un certain nombre de fois appelé epoch number. Après avoir défini l'architecture, l'algorithme d'apprentissage s'écrit comme suit :

(∗) La cost function L évalue les distances entre la valeur réelle et prédite sur un seul point.
Initialisation des paramètres
La première étape après la définition de l'architecture du neural network est l'initialisation des paramètres. C'est équivalent à injecter un bruit initial dans les poids du modèle.
- Zero initialization : on peut penser à initialiser les paramètres avec des 0 partout, c'est-à-dire : W=0 et b=0
En utilisant les équations de la forward propagation, nous notons que toutes les hidden units seront symétriques, ce qui pénalise la phase d'apprentissage.
- Random initialization : c'est une alternative couramment utilisée et consiste à injecter du bruit aléatoire dans les paramètres. Si le bruit est trop grand, certaines fonctions d'activation peuvent saturer, ce qui peut ensuite affecter le calcul du gradient.
Deux des méthodes d'initialisation les plus connues sont :
Xavier: elle consiste à remplir les paramètres avec des valeurs échantillonnées aléatoirement à partir d'une variable centrée suivant la distribution normale :
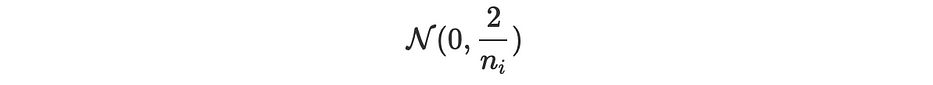
Glorot: la même approche avec une variance différente :
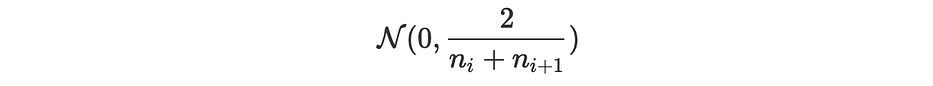
Forward et Backpropagation
Avant de plonger dans l'algèbre derrière le deep learning, nous définirons d'abord la notation qui sera utilisée pour expliciter les équations de la forward et de la backpropagation.
Représentation du réseau de neurones
Le neural network est une séquence de regressions suivies d'une activation function. Toutes deux définissent ce que nous appelons la forward propagation et sont les paramètres appris à chaque couche. La backpropagation est également une séquence d'opérations algébriques effectuées de la sortie vers l'entrée.
Forward propagation
- Algèbre à travers le réseau
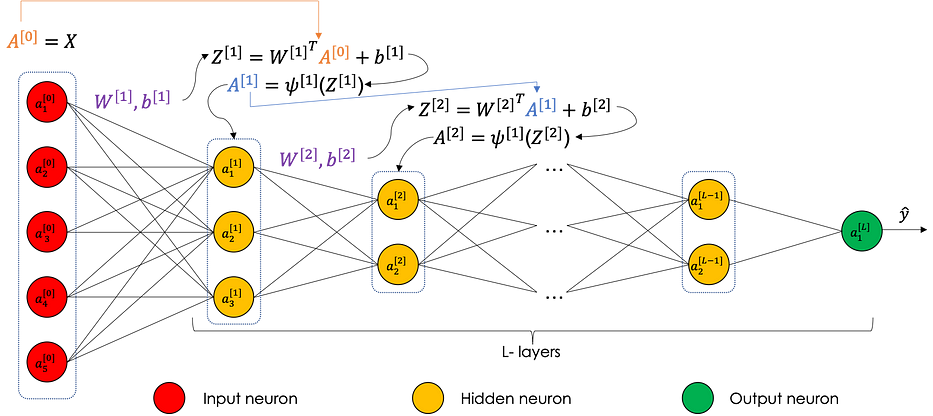
Considérons un neural network ayant L layers comme suit :

Algèbre à travers le training set
Considérons la prédiction de la sortie d'un data frame d'une seule ligne, à travers le neural network.

Lors du traitement d'un dataset à m lignes, répéter ces opérations séparément pour chaque ligne est très coûteux.
Nous avons, à chaque couche [i] :

Le paramètre b_i utilise le broadcasting pour se répéter à travers les colonnes. Cela peut être résumé dans le graphe suivant :
Backpropagation
La backpropagation est la deuxième étape de l'apprentissage, qui consiste à injecter l'erreur commise dans la phase de prédiction (forward) dans le réseau et à mettre à jour ses paramètres pour mieux performer à la prochaine itération.
D'où l'optimisation de la fonction J, généralement via une méthode de descente.
Computational graph
La plupart des méthodes de descente nécessitent le calcul du gradient de la loss function noté ∇J(θ).
Dans un neural network, l'opération est effectuée via un computational graph qui décompose la fonction J en plusieurs variables intermédiaires.
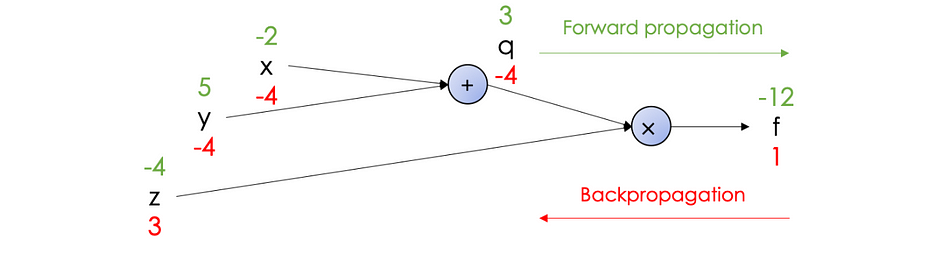
Considérons la fonction suivante : f(x,y,z)=(x+y).z
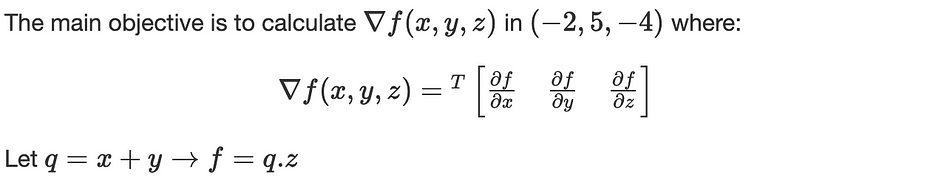
Nous effectuons le calcul en deux passes :
- Forward propagation : calcule la valeur de f des entrées à la sortie : f(−2,5,−4)=−12
- Backpropagation : applique récursivement la chain-rule pour calculer les gradients de la sortie aux entrées :
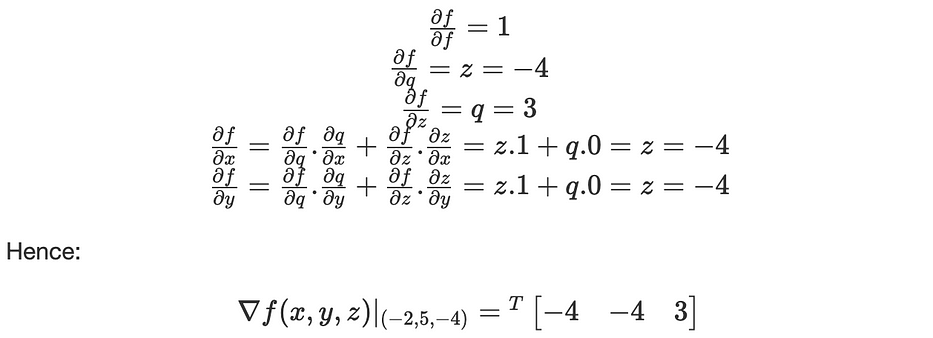
Les dérivées peuvent être résumées dans le computational graph suivant :
Équations
Mathématiquement, nous calculons les gradients de la cost function J, par rapport aux paramètres de l'architecture W et b.
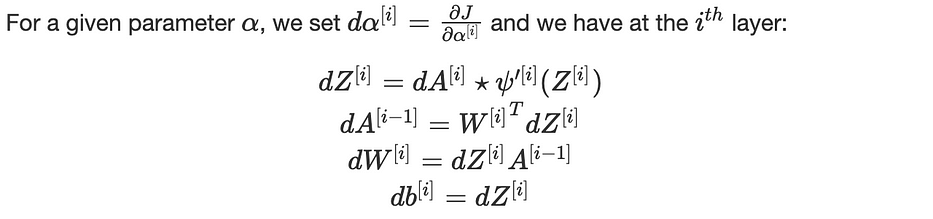
où (⋆) est la multiplication element-wise.
Nous appliquons récursivement ces équations pour i=L, L−1,…,1
Gradient Checking
Lors de l'exécution de la backpropagation, une vérification supplémentaire est ajoutée pour s'assurer que les calculs algébriques sont corrects.
Algorithme :

Cela devrait être proche de la valeur de ϵ, une erreur est suspectée lorsque la valeur de la quantité est mille fois supérieure à ϵ.
Nous pouvons résumer la forward et la backward propagation dans le bloc suivant :
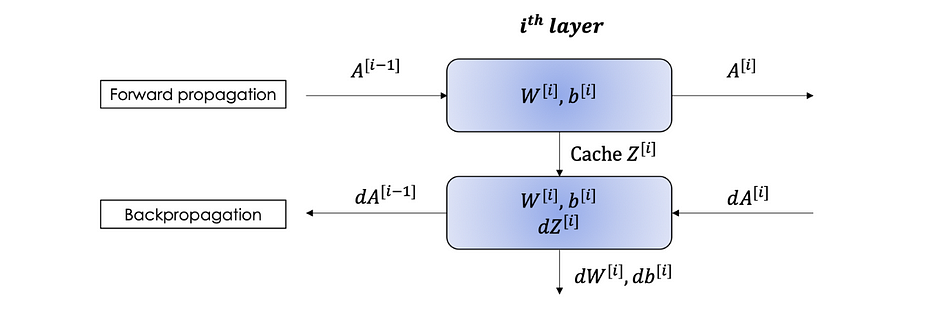
Parameters vs Hyperparameters
-Parameters, notés θ, sont les éléments que nous apprenons à travers les itérations et sur lesquels nous appliquons la backpropagation et la mise à jour : W et b.
-Hyperparameters sont toutes les autres variables que nous définissons dans notre algorithme qui peuvent être tunnées afin d'améliorer le neural network :
- Learning rate α
- Nombre d'itérations
- Choix des fonctions d'activation
- Nombre de couches L
- Nombre d'unités dans chaque couche
Fonctions d'activation
Les fonctions d'activation sont une sorte de fonctions de transfert qui sélectionnent les données propagées dans le neural network. L'interprétation sous-jacente est de permettre à un neurone du réseau de propager les données d'apprentissage (s'il est en phase d'apprentissage) uniquement s'il est suffisamment excité.
Voici une liste des fonctions les plus courantes :
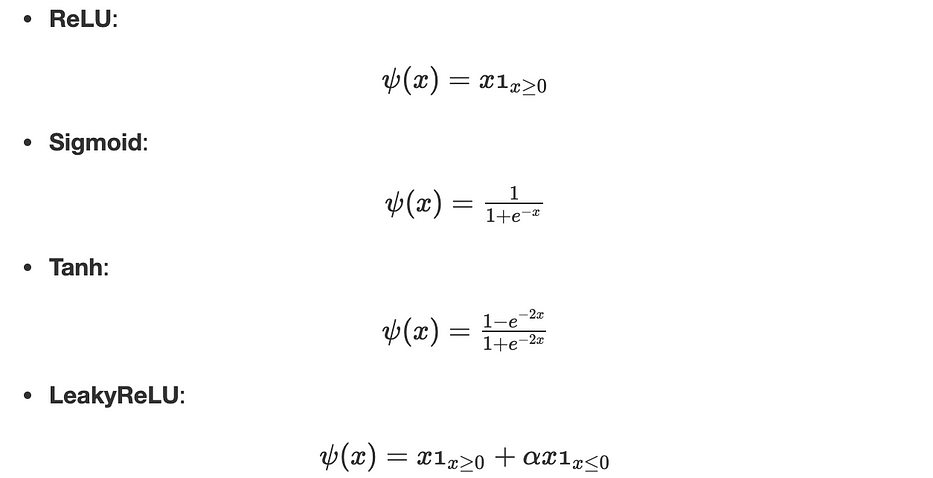
Remarque : si les fonctions d'activation sont toutes linéaires, le neural network est précisément équivalent à une simple régression linéaire
Algorithme d'optimisation
Risk
Considérons un neural network noté f. Le véritable objectif à optimiser est défini comme l'expected loss sur tous les corpora :
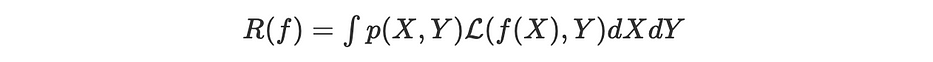
Où X est un élément d'un espace continu d'observables auquel correspond une cible Y et p(X,Y) étant la probabilité marginale d'observer le couple (X,Y).
Empirical risk
Comme nous ne pouvons pas avoir tous les corpora et donc nous ignorons la distribution, nous restreignons l'estimation du risque à un certain dataset bien représentatif des corpora globaux et considérons tous les cas équiprobables.
Dans ce cas : nous fixons m comme la taille des corpora représentatifs, nous obtenons : ∫=∑ et p(X,Y)=1/m. Par conséquent, nous optimisons itérativement la loss function définie comme suit :
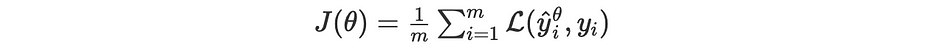
De plus nous pouvons affirmer que :
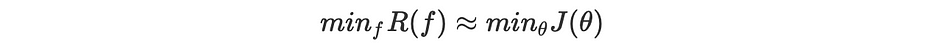
Il existe de nombreuses techniques et algorithmes, principalement basés sur la gradient descent, qui effectuent l'optimisation. Dans les sections ci-dessous, nous passerons en revue les plus célèbres. Il est important de noter que ces algorithmes peuvent rester bloqués dans des minima locaux et rien ne garantit d'atteindre le global.
Normalisation des entrées
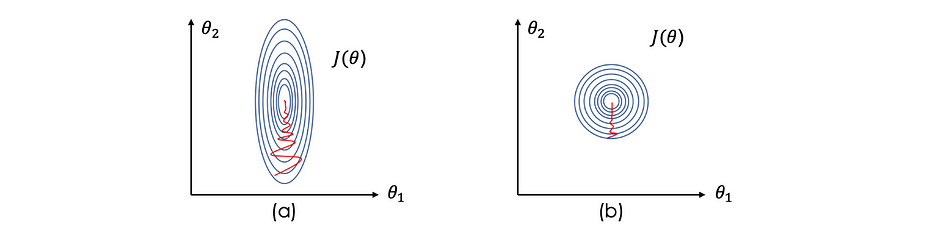
Avant d'optimiser la loss function, nous devons normaliser les entrées afin d'accélérer l'apprentissage. Dans ce cas, J(θ) devient plus serré et plus symétrique, ce qui aide la gradient descent à trouver le minimum plus rapidement et donc en moins d'itérations.
Les données standard sont l'approche couramment utilisée qui consiste à soustraire la moyenne des variables et à diviser par leur écart-type. En considérant, l'image suivante illustre l'effet de la normalisation de l'entrée sur les lignes de contour - standard data à droite - :
Soit X une variable dans notre database, nous définissons :
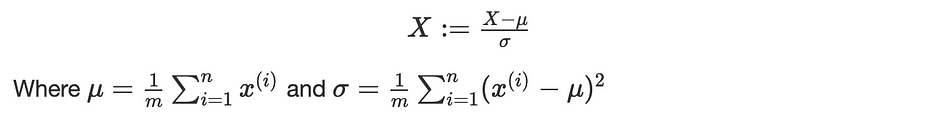
Gradient descent
En général, nous tendons à construire une fonction J convex et differentiable où tout minimum local est un minimum global. Mathématiquement parlant, trouver le minimum global d'une fonction convexe équivaut à résoudre l'équation ∇J(θ)=0, nous notons θ⋆ sa solution.
La plupart des algorithmes utilisés sont du type :

Mini-batch gradient descent
Cette technique consiste à diviser le training set en batches :

Choix de la taille du mini-batch :
- Un petit nombre de lignes ∼2000 lignes
- Taille typique : la puissance de 2 qui est bonne pour la mémoire
- Le mini-batch doit tenir dans la mémoire CPU/GPU
Remarque : dans le cas où il n'y a qu'une seule ligne de données dans le batch, l'algorithme est appelé stochastic gradient descent
Gradient descent with momentum
Une variante de la gradient descent qui inclut la notion de momentum, l'algorithme est le suivant :
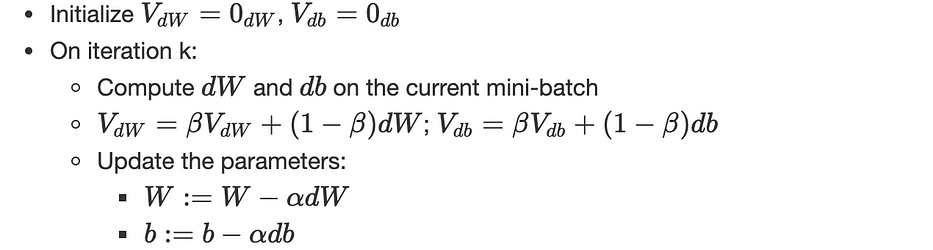
(α,β) sont des hyperparameters.
Comme dθ est calculé sur un mini-batch, le gradient résultant ∇J est très bruité, ces exponentially weighted averages incluses par le momentum donnent une meilleure estimation des dérivées.
RMSprop
Root Mean Square prop est très similaire à la gradient descent with momentum, la seule différence est qu'elle inclut le momentum de second ordre au lieu du premier ordre, plus un léger changement sur la mise à jour des paramètres :
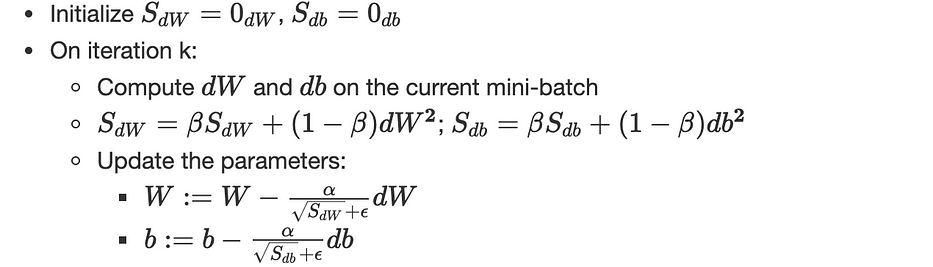
(α,β) sont des hyperparameters et ϵ assure la stabilité numérique (≈10−8)
Adam
Adam est un algorithme d'optimisation à learning rate adaptatif conçu spécifiquement pour l'entraînement de deep neural networks. Adam peut être vu comme une combinaison de RMSprop et de la gradient descent with momentum.
Il utilise les gradients carrés pour définir le learning rate à l'échelle comme RMSprop et tire parti du momentum en utilisant la moving average du gradient au lieu du gradient lui-même comme le fait la gradient descent with momentum.
L'idée principale est d'éviter les oscillations pendant l'optimisation en accélérant la descente dans la bonne direction.
L'algorithme de l'optimiseur Adam est le suivant :

Learning rate decay
L'objectif principal du learning rate decay est de réduire lentement le learning rate au fil du temps/des itérations. Cela se justifie par le fait que nous pouvons nous permettre de faire de grands pas au début de l'apprentissage mais qu'en approchant du minimum global, nous ralentissons et donc diminuons le learning rate.
Il existe de nombreuses lois de learning rate decay, voici quelques-unes des plus courantes :

Régularisation
Variance/bias
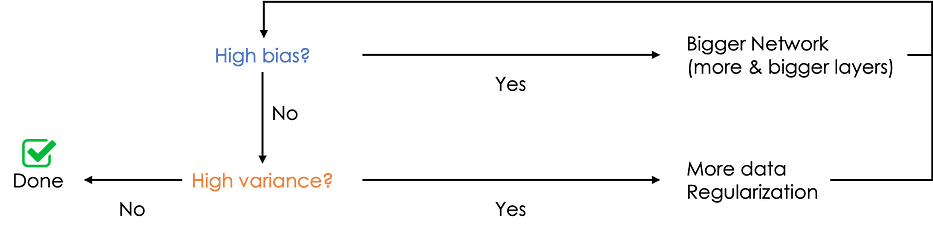
Lors de l'entraînement d'un neural network, il peut souffrir de :
- High bias : ou underfitting, où le réseau ne parvient pas à trouver le chemin dans les données, dans ce cas, J_train est très élevé tout comme J_dev. Mathématiquement parlant, lors de la cross-validation ; la moyenne de J sur tous les folds considérés est élevée.
- High variance ou overfitting, le modèle s'ajuste parfaitement aux données d'entraînement mais ne parvient pas à généraliser sur des données non vues, dans ce cas, J_train est très bas et J_dev est relativement élevé. Mathématiquement parlant, lors de la cross-validation ; la variance de J sur tous les folds considérés est élevée.
Considérons le jeu des fléchettes, où atteindre la cible rouge est le meilleur des cas. Avoir un low bias (première ligne) signifie qu'en moyenne nous sommes proches du but. Dans le cas d'une low variance, les coups sont tous concentrés autour de la cible (la variance de la distribution des coups est faible). Lorsque la variance est élevée, sous l'hypothèse d'un low bias, les coups sont dispersés mais toujours autour du cercle rouge.
Vice-versa, nous pouvons définir le high bias avec une low/high variance.
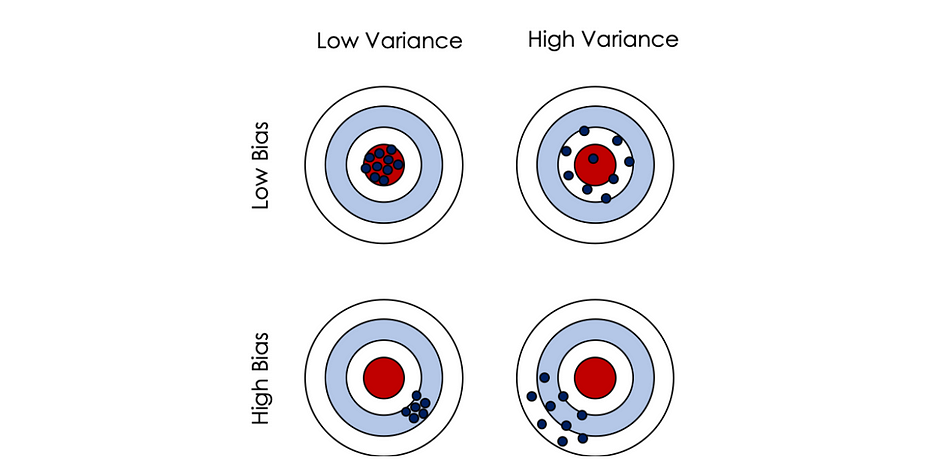
Mathématiquement parlant, soit f une vraie fonction de régression : y=f(x)+ϵ où : ϵ~N(0,σ²)
Nous ajustons une hypothèse h(x)=Wx+b avec MSE et considérons x_0 comme un nouveau data point, y_0=f(x_0)+ϵ : l'erreur attendue peut être définie par :
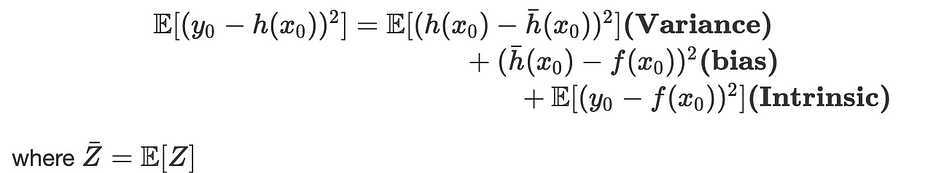
Un compromis doit être trouvé entre variance et bias pour trouver la complexité optimale du modèle, soit en utilisant les critères AIC, soit en utilisant la cross-validation.
Voici un schéma simple à suivre pour résoudre les problèmes de bias/variance :
Régularisation L1, L2
La régularisation est une technique d'optimisation qui empêche l'overfitting.
Elle consiste à ajouter un terme dans la fonction objectif à minimiser comme suit :
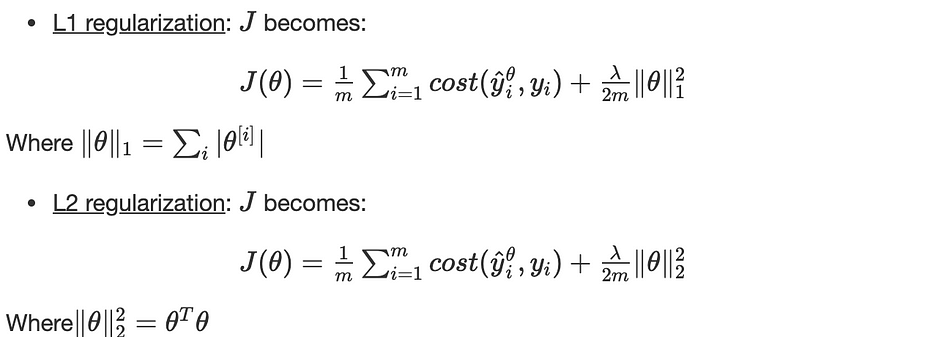
λ est l'hyperparameter de la régularisation.
Backpropagation et régularisation
La mise à jour des paramètres lors de la backpropagation dépend du gradient ∇J, auquel s'ajoute un nouveau terme de régularisation. Dans la régularisation L2, cela devient comme suit :
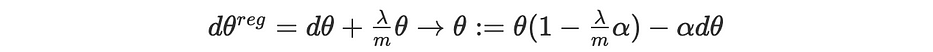
Considérant λ>>1, minimiser la cost function conduit à des valeurs faibles des paramètres à cause du terme (λ/2m)∥θ∥ qui simplifie le réseau et le rend plus cohérent, donc moins exposé à l'overfitting.
Dropout regularization
En gros, l'idée principale est d'échantillonner une variable aléatoire uniforme, for each layer for each node, et d'avoir p de chance de garder le node et 1−p de le supprimer, ce qui diminue le réseau.
L'intuition principale du dropout est basée sur l'idée que le réseau ne devrait pas s'appuyer sur une feature spécifique mais devrait plutôt répartir les poids !
Mathématiquement parlant, lorsque le dropout est off et en considérant le j ème node de la i ème couche, nous avons les équations suivantes :
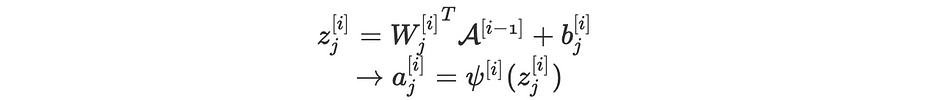
Lorsque le dropout est on, les équations deviennent comme suit :
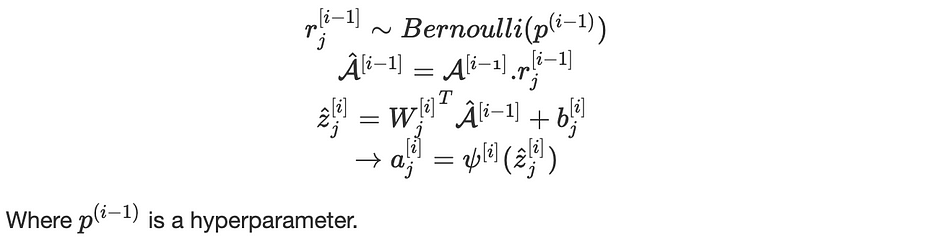
Early stopping
Cette technique est assez simple et consiste à arrêter l'itération autour de la zone où J_train et J_dev commencent à se séparer :
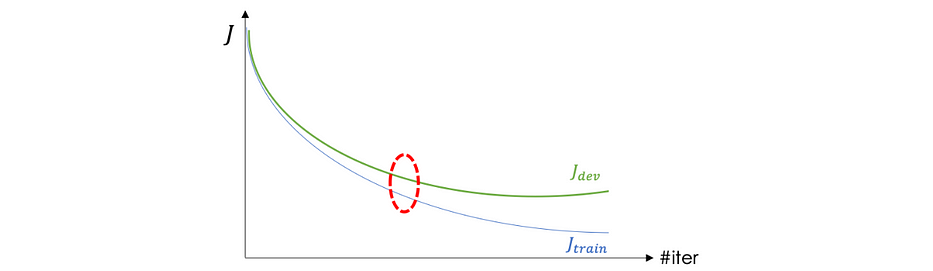
Problèmes de gradient
Le calcul des gradients souffre de deux problèmes majeurs : le gradient vanishing et le gradient exploding.
Pour illustrer les deux situations, considérons un neural network où toutes les fonctions d'activation ψ[i] sont linéaires et :
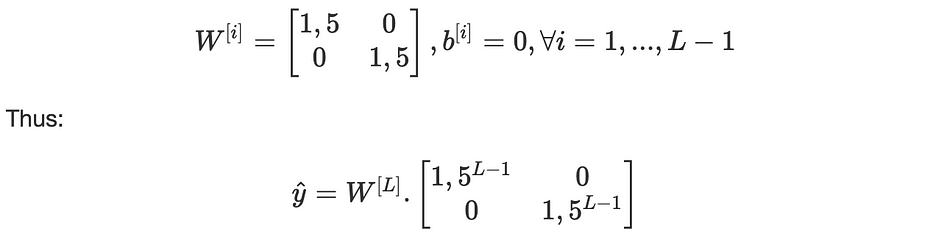
Nous notons que 1,5^(L−1) va exploser exponentiellement en fonction de la profondeur L. Si nous utilisons 0.5 au lieu de 1,5 alors 0,5^(L-1) s'évanouira exponentiellement également.
Le même problème se produit avec les gradients.
Conclusion
En tant que data scientist, il est très important d'être conscient des mathématiques qui tournent en arrière-plan des neural networks. Cela permet une meilleure compréhension et un débogage plus rapide.
N'hésitez pas à consulter mes articles précédents traitant de :
- Les mathématiques des Convolutional Neural Networks
- Algorithmes de détection d'objets & reconnaissance faciale
- Recurrent Neural Networks
Happy Machine Learning !
Références
- Deep Learning Specialization, Coursera, Andrew Ng
- Optimization course, Mines Nancy, Antoine Henrot
- Machine Learning, Loria, Christophe Cerisara