
De nombreuses entreprises doivent aujourd'hui traiter des cas similaires dans le cadre de leur activité. Peu d'entre elles tirent parti des travaux passés et déjà effectués, tandis que la grande majorité recommence tout depuis le début.
Dans cet article, nous découvrirons comment exploiter des algorithmes d'AI pour construire un moteur de matching capable d'utiliser à la fois des variables textuelles, catégorielles et numériques.
Pour des raisons de simplicité, nous considérerons qu'un cas est décrit par les données suivantes :
- Num : variable numérique
- Categ : variable catégorielle (un mot)
- Sent : variable textuelle (1 phrase - nécessite un embedding)
- Parag : variable textuelle (paragraphe - nécessite un embedding)
Si votre base de données ne suit pas la même structure, vous pouvez appliquer un pipeline de préprocessing pour vous ramener au même scénario.
Le sommaire est le suivant :
- Embeddings
- Similarités
- Moteur de matching
Embeddings
Word embedding
Le word embedding est l'art de représenter un mot dans un espace vectoriel de taille N, où les mots sémantiquement similaires sont, mathématiquement parlant, proches les uns des autres.
C'est une étape importante lorsqu'on traite des données textuelles, puisque les algorithmes de ML travaillent principalement avec des valeurs numériques.
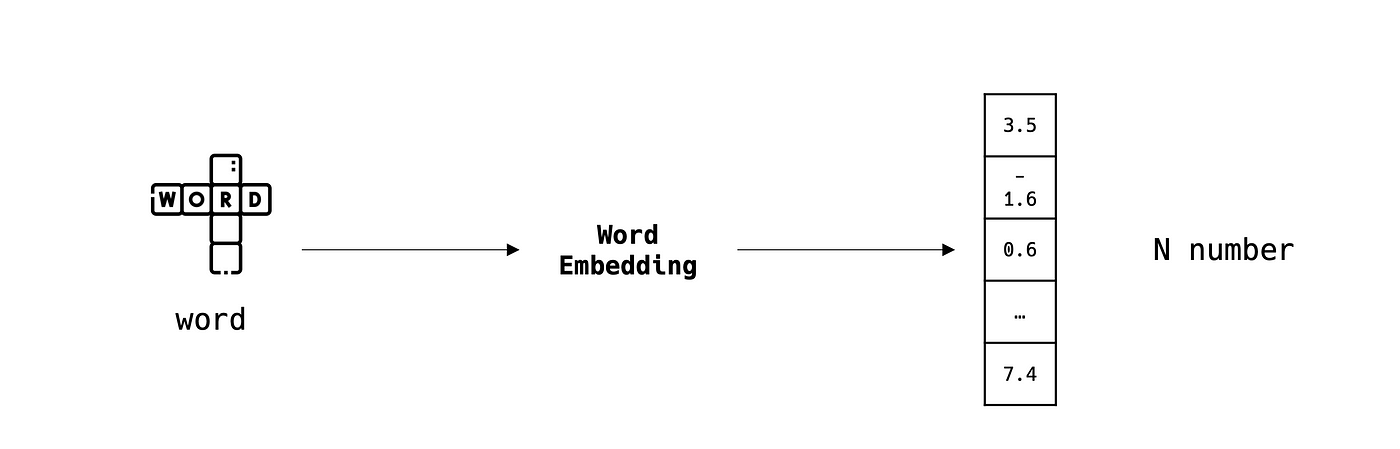
Il existe de nombreux algorithmes de word embedding comme Word2Vec, FastText, BERT, …, qui disposent de plusieurs adaptations dans différentes langues.
Sentence Embedding
Une phrase est une séquence de mots. Ceci étant dit, on peut agréger les embeddings de mots pour générer l'embedding de la phrase en suivant les étapes ci-dessous :
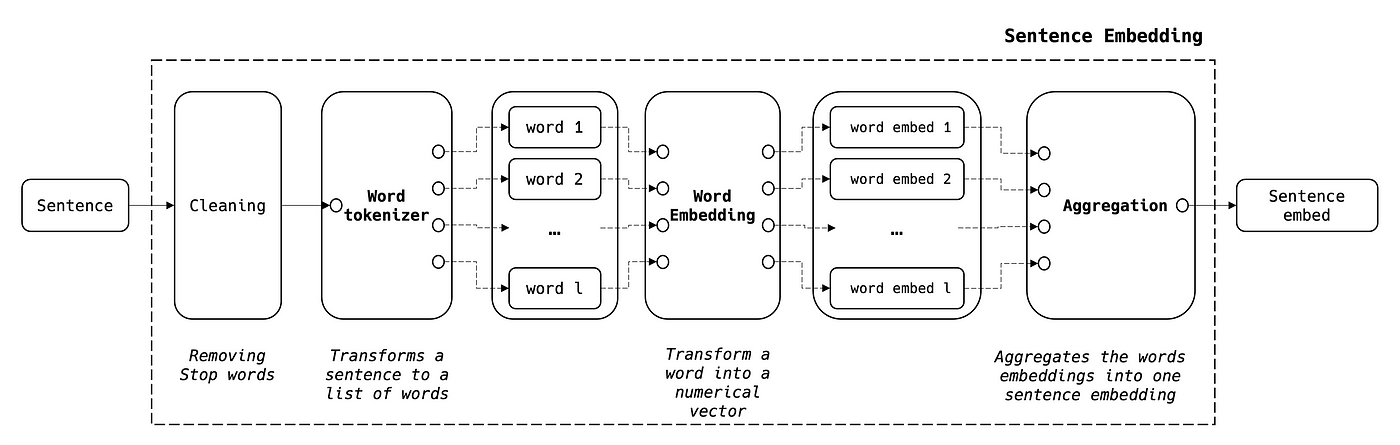
où :
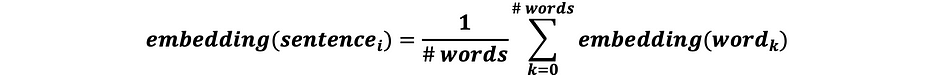
- NB1 : lors de l'étape de nettoyage, on peut ne garder que les mots-clés à embedder
- NB2 : la formule agrégée permet d'équilibrer entre phrases longues et courtes
- NB3 : la taille de l'embedding de la phrase est la même que celle de l'embedding du mot, N
Paragraph Embedding
On peut utiliser la même approche que ci-dessus étant donné qu'un paragraphe est une séquence de phrases :
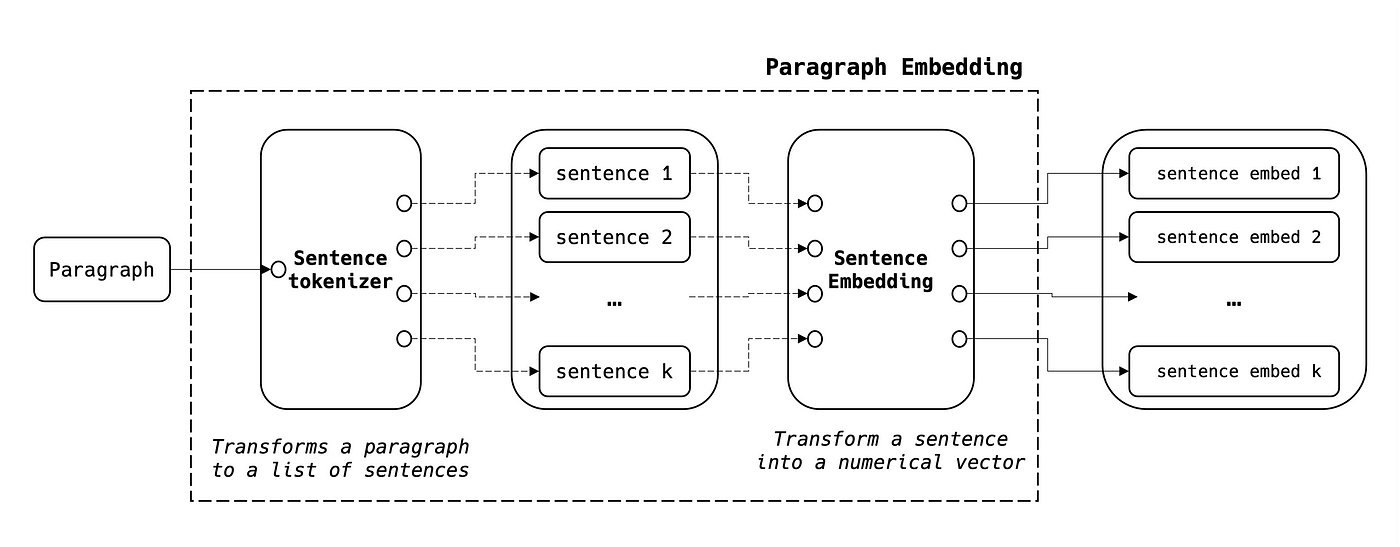
- NB1 : dans le langage courant, les phrases sont souvent séparées à l'aide de la chaîne « . », mais une personnalisation peut être nécessaire dans certains cas.
- NB2 : la taille de l'embedding du paragraphe est (N, k) où N est la taille de l'embedding de la phrase et k le nombre de phrases dans le paragraphe.
Similarité
Similarités numériques
Considérons deux valeurs numériques x et y, et NumSim la distance entre les deux définie comme suit :
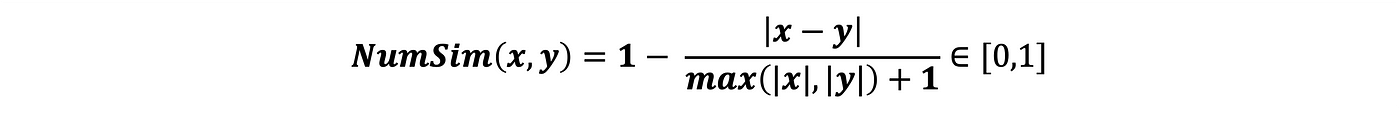
si :
- x=y => NumSim(x,y)=1
- x>>y => NumSim(x,y)≈1/(|x|+1)≈0
Similarités entre mots
Il existe de nombreuses méthodes pour calculer la similarité entre deux mots, nous citons ci-dessous deux des approches les plus connues :
- Approximate string matching (basé sur les caractères) : distance de Levenshtein, …
- Semantic string matching (basé sur les embeddings) : similarité cosinus, distance euclidienne, …
Dans cet article, nous nous concentrerons principalement sur la similarité cosinus, qui n'est autre que le cosinus de l'angle entre les deux vecteurs d'embedding des deux mots comparés :
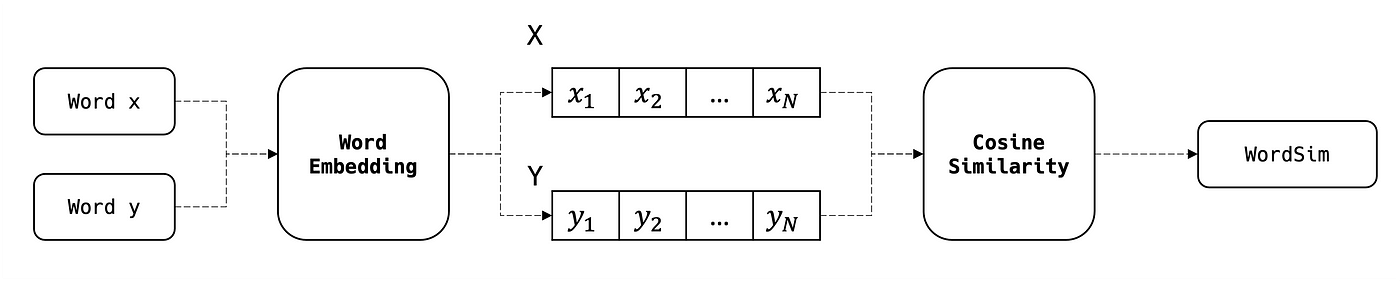
Où :
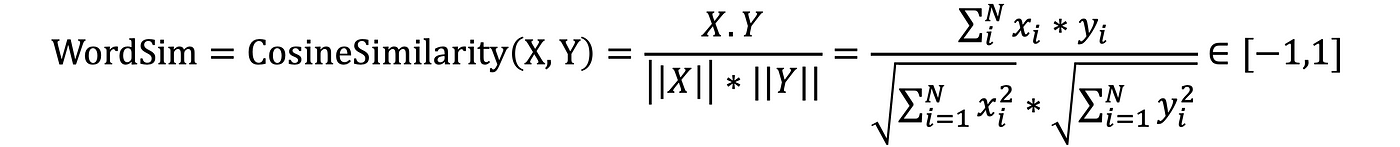
Similarités entre phrases
Nous suivons la même approche en utilisant cette fois l'algorithme de sentence embedding défini ci-dessus :

Où :

Similarités entre paragraphes
Les similarités entre paragraphes sont légèrement plus complexes, car leurs embeddings sont considérés comme des matrices 2D plutôt que comme des vecteurs. Pour comparer les deux paragraphes, on calcule la SentSim de chaque paire de phrases et on génère une matrice de similarité 2D, qui est ensuite agrégée en un seul score :
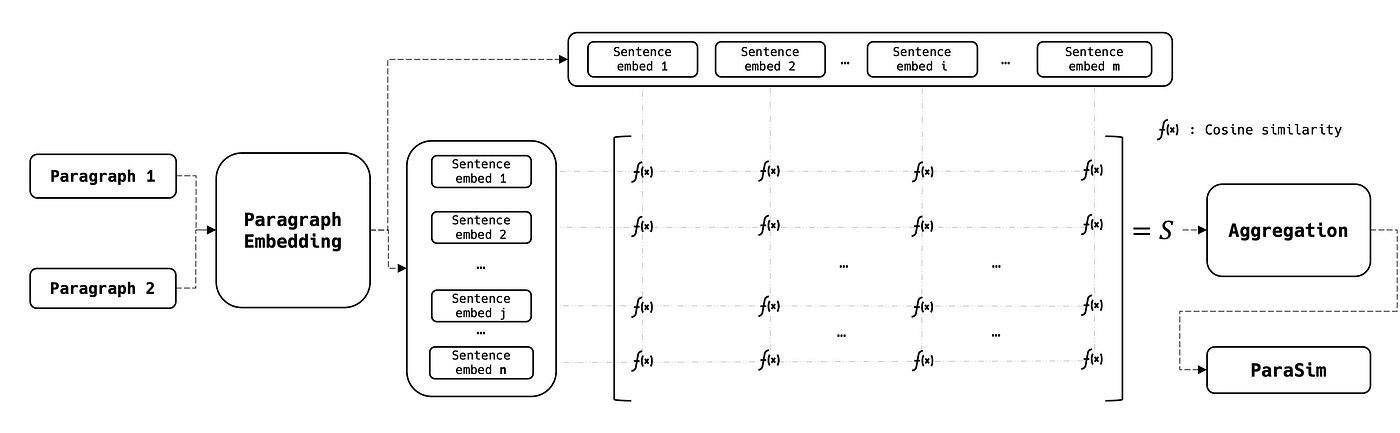
Où :

Moteur de Matching
Comme mentionné précédemment, considérons un cas d'usage métier où nous devons traiter de nombreux cas. Chaque cas est décrit par les quatre variables : Num, Categ, Sent et Parag (voir introduction).
Nous pouvons exploiter les données historiques pour comparer chaque nouveau cas à l'ensemble de la base de données et sélectionner ceux qui sont les plus similaires, en utilisant le diagramme suivant :
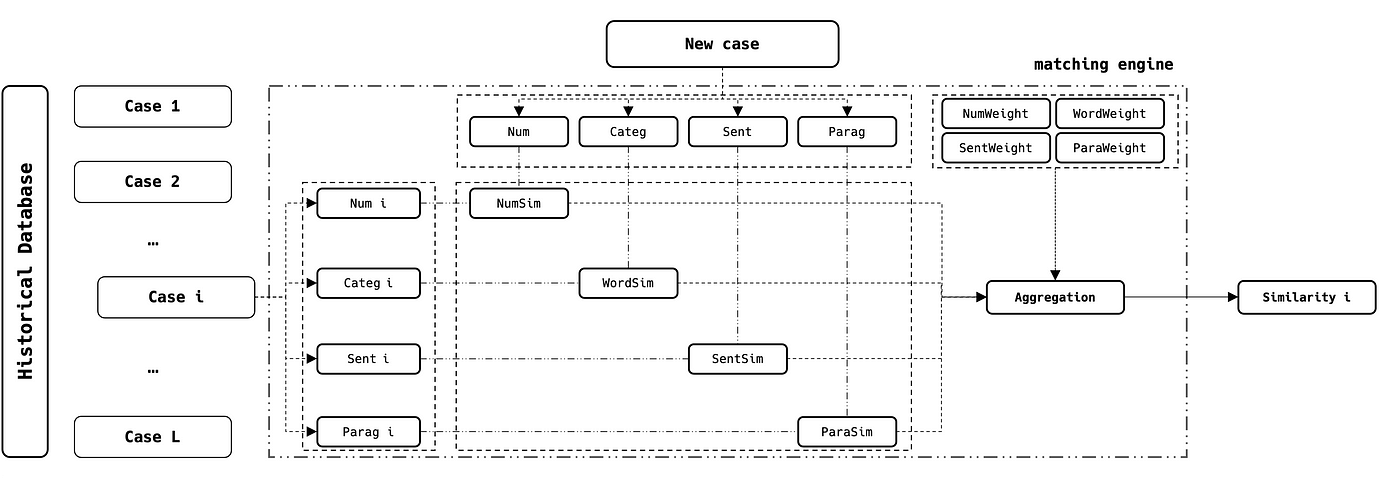
Où :
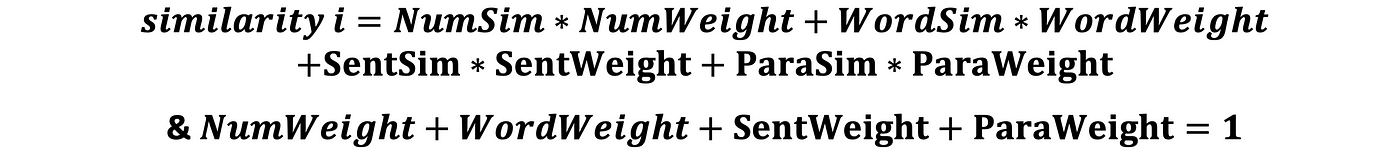
Nous effectuons ces opérations sur tous les cas de 1 à L (taille de la base de données) et renvoyons les scores de matching les plus élevés.
- NB1 : si la variable Categ possède des modalités uniques et stables, on peut remplacer le matching par un simple filtrage
- NB2 : si vous avez plus d'une variable par type, vous pouvez les empiler dans le même moteur en utilisant l'approche de similarité adaptée
- NB3 : le poids de chaque variable est choisi en fonction de sa priorité et de son importance métier
Conclusion
Les moteurs de matching sont largement populaires et utilisés dans le monde de la tech. Ils permettent aux entreprises de disposer d'outils de traitement plus rapides, sources de gains de temps et d'argent.
Dans cet article, nous nous sommes concentrés sur un type spécifique d'entrée (numérique et textuelle), mais on peut aussi imaginer avoir une image comme description supplémentaire de notre cas. Cela appelle à utiliser des techniques de CNN telles que les Siamese networks, qui génèrent un embedding d'image utilisé avec la similarité cosinus pour produire un score de matching supplémentaire.