
Les réseaux de neurones convolutifs sont largement utilisés pour résoudre des problèmes liés aux images, tels que la détection d'objets/caractères et la reconnaissance faciale. Dans cet article, nous nous concentrerons sur les architectures les plus connues, de LeNet aux Siamese networks, qui partagent pour la plupart l'architecture suivante :
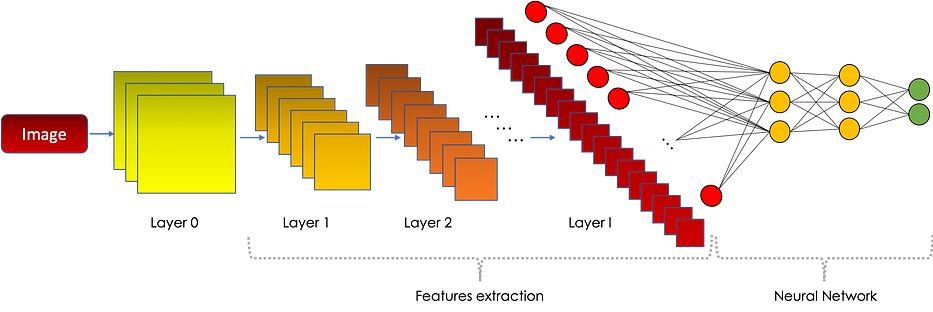
Si vous n'avez aucune connaissance sur les réseaux de neurones convolutifs, je vous conseille de lire la première partie de cet article, qui aborde les fondamentaux des CNNs.
NB : Medium ne supportant pas LaTeX, les expressions mathématiques sont insérées sous forme d'images. Je vous conseille donc de désactiver le mode sombre pour une meilleure expérience de lecture.
Table des matières
- Cross-Entropy
- Classification d'images
- Détection d'objets, YOLOv3
- Reconnaissance faciale, Siamese Networks
Cross-Entropy
Lors de la classification d'une image, nous utilisons souvent une fonction softmax à la dernière couche, de taille (C,1) où C est le nombre de classes considérées.
La i ème ligne du vecteur représente la probabilité que l'image d'entrée appartienne à la classe i. La predicted class est définie comme étant celle correspondant à la highest probability.
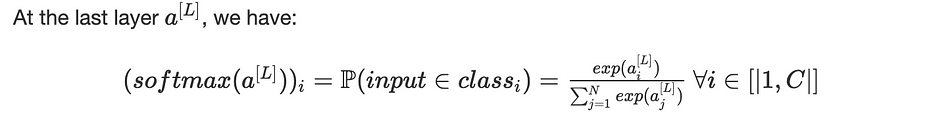
Le réseau apprend en utilisant la backpropagation et optimise la cross entropy définie comme suit :
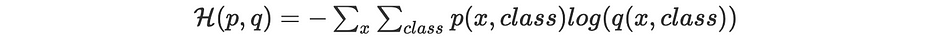
Où
- p(x,class) est la probabilité de référence et vaut 1 si l'objet appartient réellement à la classe indiquée et 0 sinon
- q(x,class) est la probabilité, apprise par le réseau via le softmax, que l'objet x appartienne à cette classe
Pour une entrée x∈class_j :
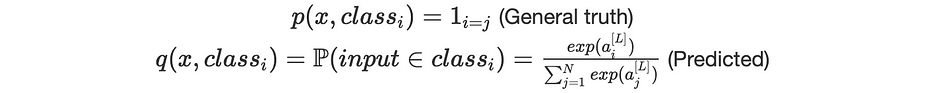
Ainsi, nous définissons la loss function comme :

Nous moyennons la loss, où m est la taille du training set.
Classification d'images
LeNet, Reconnaissance de chiffres
LeNet est une architecture développée par Yann Lecun qui vise à détecter le chiffre présent dans l'entrée.
Étant donné des images gray-scale de chiffres hand-written de 0 à 9, le réseau de neurones convolutif prédit le chiffre représenté.
Le training set utilisé s'appelle MNIST, un dataset contenant plus de 70k images de 28x28x1 pixels. Le réseau de neurones a l'architecture suivante et compte plus de 60k paramètres :
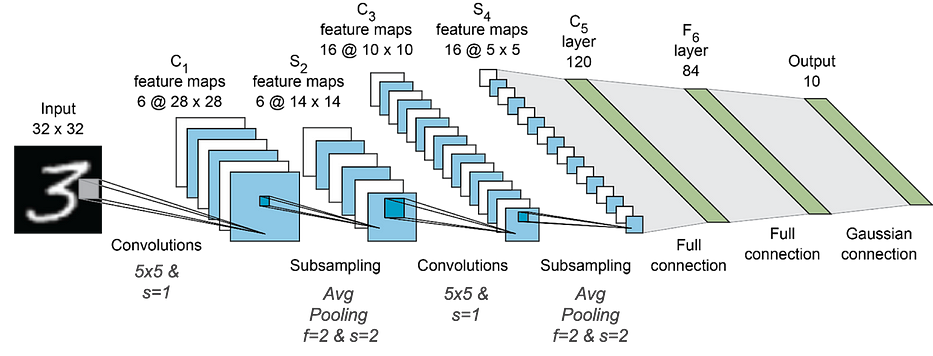
Pour plus de détails, je vous conseille de lire le paper officiel.
AlexNet
AlexNet est une architecture célèbre qui a remporté la compétition ImageNet en 2012. Elle est similaire à LeNet mais possède plus de couches, des dropouts et utilise principalement la fonction d'activation ReLU.
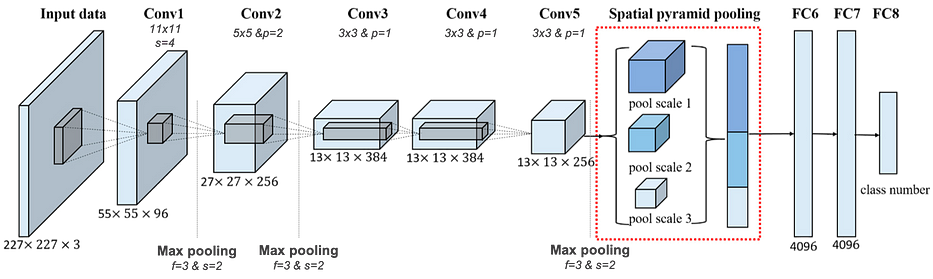
Le training set est un sous-ensemble de la ImageNet database, soit 15 millions d'images labellisées à haute résolution représentant plus de 22k catégories.
AlexNet a utilisé plus de 1,2 million d'images dans le training set, 50k dans le validation set et 150k dans le test set, toutes redimensionnées à 227x227x3. L'architecture compte plus de 60 millions de paramètres et a donc été entraînée sur 2 GPUs, elle renvoie un softmax vector de taille (1000,1) .
Pour plus d'informations, je vous conseille de lire le paper officiel.
VGG-16
VGG-16 est un réseau de neurones convolutif pour la classification d'images, entraîné sur le même dataset ImageNet et qui possède plus de 138 millions de paramètres entraînés sur GPUs.
L'architecture est la suivante :
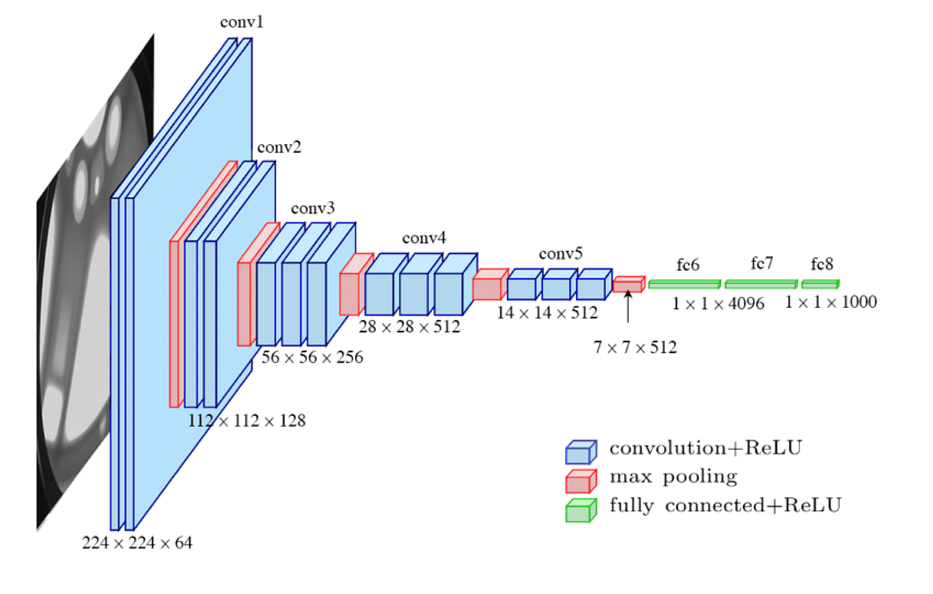
Il est plus précis et plus profond qu'AlexNet car il a remplacé les grands kernels 11x11x5 et 5x5 par des kernels 3x3 successifs.
Pour plus de détails, consultez le paper officiel du projet VGG.
Détection d'objets - YOLOv3
La détection d'objets consiste à détecter plusieurs objets dans une image, ce qui englobe à la fois la localisation et la classification des objets. Une première approche grossière consisterait à faire glisser une fenêtre aux dimensions personnalisables et à prédire à chaque fois la classe du contenu à l'aide d'un réseau entraîné sur des images recadrées. Ce processus a un coût de calcul élevé et peut heureusement être automatisé grâce aux convolutions.
YOLO signifie You Only Look Once et l'idée de base consiste à placer une grille sur l'image (généralement 19x19) où :
Seule une cellule, celle contenant le centre/le point médian d'un objet, est responsable de la détection de cet objet
Chaque cellule de la grille (i,j) est labellisée comme suit :

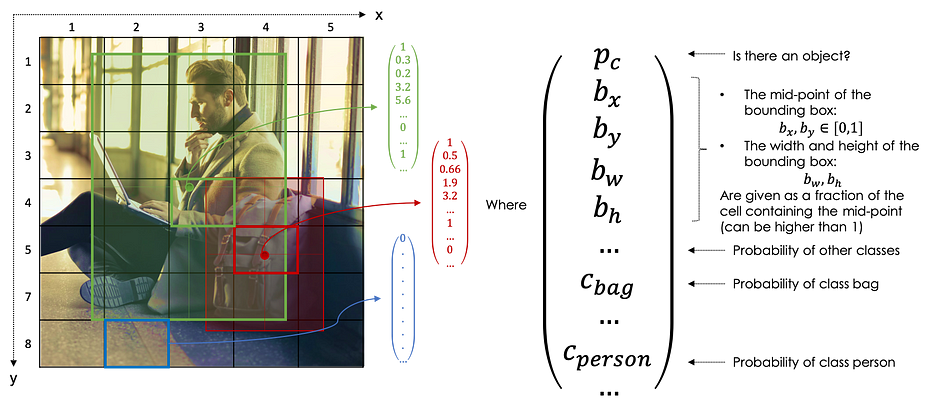
Ainsi, pour chaque image, la sortie cible est de taille :
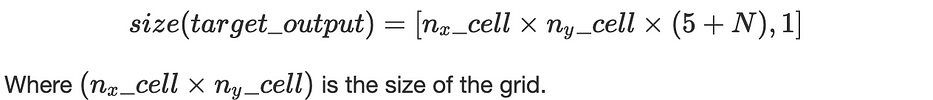
IOU & NMS
Afin d'évaluer la localisation d'objets, nous utilisons l'Intersection Over Union qui mesure le overlap entre deux bounding boxes :

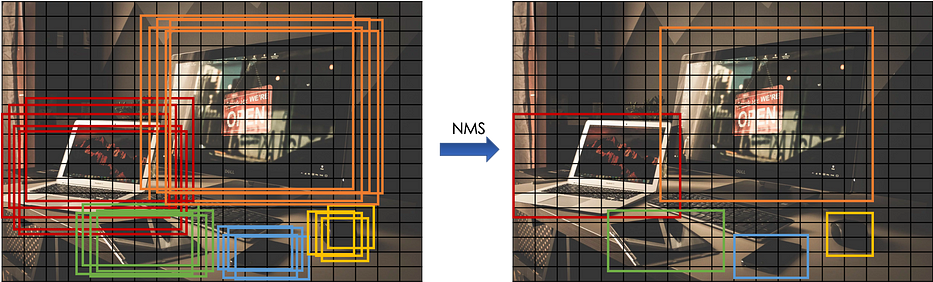
Lors de la prédiction de la bounding box d'un objet donné dans une cellule donnée de la grille, plusieurs sorties peuvent être obtenues, la Non-Max Suppression permet de détecter l'objet only once. Elle prend la probabilité la plus élevée et supprime les autres boxes ayant un fort overlap (IOU).
Pour chaque cellule de la grille, l'algorithme est le suivant :

Anchor Boxes
Dans la plupart des cas, une cellule de la grille peut contenir multiple objects, les anchor boxes permettent de tous les détecter. Dans le cas de 2 anchor boxes, chaque cellule de la grille est labellisée comme suit :
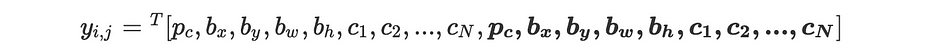

Plus généralement, la sortie cible est de taille :
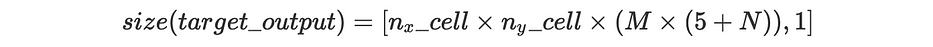
Où N est le nombre de classes et M le nombre d'anchor boxes.
Algorithme YOLOv3
YOLO a été entraîné sur le dataset coco, une grande base de données de détection d'objets, de segmentation et de captioning comportant 80 catégories d'objets. YOLOv3 utilise une architecture Darknet-53 comme feature extractor, aussi appelé backbone.
L'entraînement s'effectue en minimisant une loss function à l'aide de méthodes de gradient également.
Elle est combined de :
- Logistic regression loss sur p_c
- Squared error loss pour b_i
- Softmax loss (cross-entropy) pour les probabilités c_i
À chaque epoch, dans chaque cellule, nous générons la sortie y_(i,j) et evaluate la loss function.
Lors des prédictions, nous vérifions que p_c est suffisamment élevé et, pour chaque grid-cell, nous éliminons les prédictions à faible probabilité et appliquons la non-max suppression pour chaque classe afin de générer la sortie finale.
Pour plus d'informations, je vous conseille de lire le paper officiel.
Reconnaissance faciale - Siamese Networks
Les Siamese networks sont des réseaux de neurones, souvent convolutifs, qui permettent de calculer le degré de similarité entre deux entrées, des images dans notre cas, comme suit :
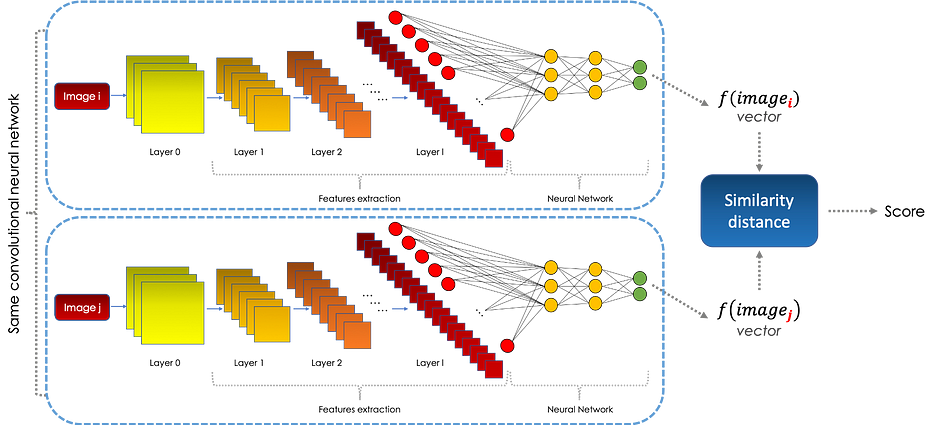
L'objectif du module CNN est de représenter l'information contenue dans l'image dans un autre espace, appelé embedding space grâce à une fonction. Nous comparons ensuite les deux embeddings en utilisant une certaine distance. L'apprentissage dans les Siamese networks se fait en minimisant une fonction objectif composée d'une loss function appelée triplet.
La fonction triplet prend en entrée 3 variables vectorielles : un Anchor A, un positif P (similaire à A) et un négatif N (différent de A). Ainsi, nous cherchons à avoir :
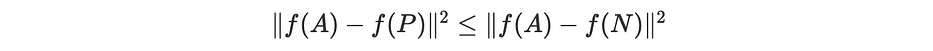
Où ∥x∥²=<x,x> pour un produit scalaire donné.
Pour empêcher la fonction apprise f d'être nulle, nous définissons la marge 0<α≤1 telle que :
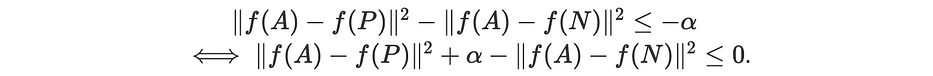
Ainsi, nous définissons la fonction loss comme suit :
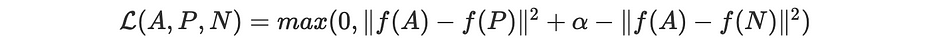
À partir d'une base d'apprentissage de taille n, la fonction objectif à minimiser est :
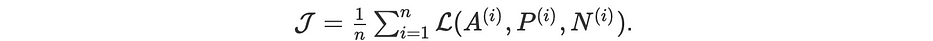
Lors de l'entraînement de l'architecture et pour chaque epoch, nous fixons le nombre de triplets et pour chacun :
- Nous choisissons aléatoirement deux images de la même classe (Anchor & Positive)
- Nous choisissons aléatoirement une image d'une autre classe (Negative)
Un triplet (A, N, P) peut être :
- Easy negative, lorsque ∥f(A)−f(P)∥²+α−∥f(A)−f(N)∥²≤0
- Semi-hard negative, lorsque ∥f(A)−f(P)∥²+α>∥f(A)−f(N)∥²>∥f(A)−f(P)∥²
- Hard negative, lorsque ∥f(A)−f(N)∥²<∥f(A)−f(P)∥²
Nous choisissons généralement de nous concentrer sur les semi-hard negatives pour entraîner le réseau de neurones.
Application : Reconnaissance faciale
Les Siamese networks peuvent être utilisés pour développer un système capable d'identifier des visages. Étant donné une image prise par caméra, l'architecture la compare à toutes les images de la base.
Comme nous ne pouvons pas disposer de plusieurs images de la même personne dans notre base, nous entraînons généralement le siamese network sur un imageset open-source suffisamment riche pour créer les triplets.
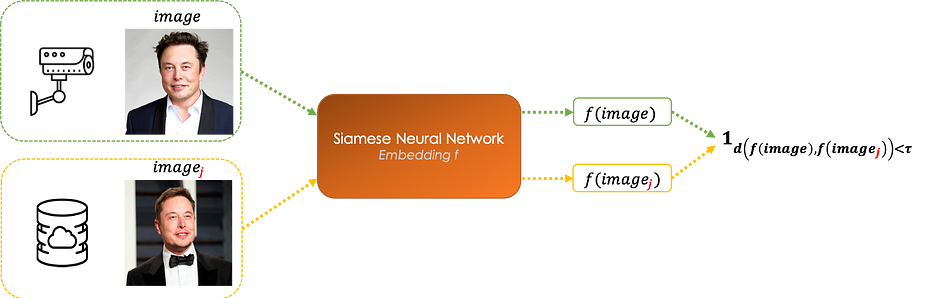
Le réseau de neurones convolutif apprend une fonction de similarité f qui est l'embedding de l'image.
Étant donné une image issue de la caméra, nous la comparons à chaque image_j de la base telle que :
- Si d(f(image, image_j))≤τ, les deux images représentent la même personne
- Si d(f(image, image_j))>τ, les images représentent deux personnes différentes
Nous choisissons le visage image_j qui est le plus proche de image au sens de la distance d. Le seuil τ est choisi de manière à maximiser le F1-score par exemple.
Conclusion
Les CNNs sont des architectures largement utilisées dans le traitement d'images, elles permettent d'obtenir des résultats meilleurs et plus rapides. Récemment, elles ont également été utilisées dans le traitement de texte, où l'entrée du réseau est l'embedding des tokens au lieu des pixels des images.
N'hésitez pas à consulter mes articles précédents traitant de :
- Les mathématiques du Deep Learning
- Les mathématiques des Convolutional Neural Networks
- Recurrent Neural Networks
Références
- Deep Learning Specialization, Coursera, Andrew Ng
- Machine Learning, Loria, Christophe Cerisara