
Les fichiers PDF, pour Portable Document Format, sont un type de fichiers développés par Adobe afin de permettre la création de différentes formes de contenu. En particulier, ils offrent une sécurité constante quant aux modifications de leur contenu. Un fichier PDF peut héberger différents types de données : texte, images, médias, …etc. C'est un fichier structuré par balises, ce qui le rend facile à parser, à l'image d'une page HTML.
Ceci étant dit, pour des questions de structure, on peut séparer les fichiers PDF en deux classes :
- Fichiers basés sur du texte : contenant du texte pouvant être copié et collé
- Fichiers basés sur des images : contenant des images, comme des documents scannés
Dans cet article, nous passerons en revue les principales librairies Python qui permettent de parser des fichiers PDF, qu'ils soient basés sur du texte ou sur des images, ces dernières seront OCRisées puis traitées comme des fichiers à base de texte. Nous verrons aussi dans le dernier chapitre comment utiliser l'algorithme de détection d'objets YOLOV3 pour parser des tableaux.
Le sommaire est le suivant :
- Fichiers PDF basés sur des images
1.1. OCRMYPDF - Fichiers PDF basés sur du texte
2.1. PyPDF2
2.2. PDF2IMG
2.4. Camelot
2.5. Camelot couplé à YOLOV3
À titre d'illustration tout au long de cet article, nous utiliserons ce fichier PDF.
Fichiers PDF basés sur des images
1. OCRMYPDF
Ocrmypdf est un package Python qui permet de transformer un PDF basé sur des images en un PDF basé sur du texte, dans lequel le texte peut être sélectionné, copié et collé.
Pour installer ocrmypdf, vous pouvez utiliser brew sur macOS et Linux avec la ligne de commande :
brew install ocrmypdfUne fois le package installé, vous pouvez ocriser votre fichier PDF en exécutant la ligne de commande suivante :
ocrmypdf input_file.pdf output_file.pdfoù :
- ocrmypdf : la variable de chemin
- input_file.pdf : le fichier PDF basé sur des images
- output_file.pdf : le fichier de sortie basé sur du texte
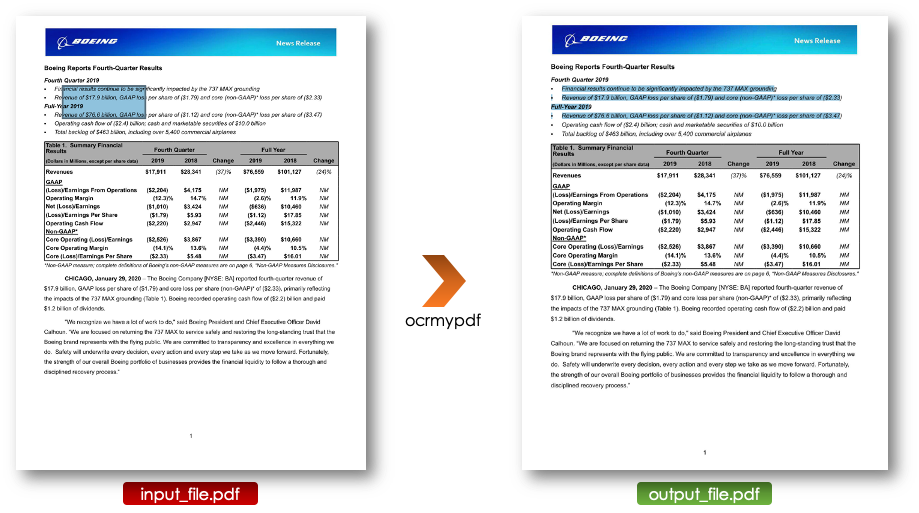
Une fois le PDF transformé en un fichier basé sur du texte, il peut être traité avec toutes les librairies détaillées ci-dessous.
Pour plus de détails sur ocrmypdf, veuillez consulter le site officiel.
Fichiers PDF basés sur du texte
Dans cette section, nous nous concentrerons principalement sur trois librairies Python qui permettent d'extraire le contenu d'un fichier PDF basé sur du texte.
1. PyPDF2
PyPDF2 est un outil Python qui nous permet de parser des informations basiques sur le fichier PDF, comme l'auteur, le titre, …etc. Il permet aussi d'obtenir le texte d'une page donnée, de splitter des pages et d'ouvrir des fichiers chiffrés sous réserve de disposer du mot de passe.
PyPDF2 peut être installé avec pip en exécutant la ligne de commande suivante :
pip install PyPDF2Nous résumons toutes les fonctionnalités listées ci-dessus dans les scripts Python suivants :
- Lire un fichier PDF :
from PyPDF2 import PdfFileWriter, PdfFileReader
PDF_PATH = "boeing.pdf"
pdf_doc = PdfFileReader(open(PDF_PATH, "rb"))- Extraire les informations du document :
print("---------------PDF's info---------------")
print(pdf_doc.documentInfo)
print("PDF is encrypted: " + str(pdf_doc.isEncrypted))
print("---------------Number of pages---------------")
print(pdf_doc.numPages)
>> ---------------PDF's info---------------
>> {'/Producer': 'WebFilings', '/Title': '2019 12 Dec 31 8K Press Release Exhibit 99.1', '/CreationDate': 'D:202001281616'}
>> PDF is encrypted: False
>> ---------------Number of pages---------------
>> 14- Splitter le document page par page :
#indexation starts at 0
pdf_page_1 = pdf_doc.getPage(0)
pdf_page_4 = pdf_doc.getPage(3)
print(pdf_page_1)
print(pdf_page_4)
>> {'/Type': '/Page', '/Parent': IndirectObject(1, 0), '/MediaBox': [0, 0, 612, 792], '/Resources': IndirectObject(2, 0), '/Rotate': 0, '/Contents': IndirectObject(4, 0)}
>> {'/Type': '/Page', '/Parent': IndirectObject(1, 0), '/MediaBox': [0, 0, 612, 792], '/Resources': IndirectObject(2, 0), '/Rotate': 0, '/Contents': IndirectObject(10, 0)}
- Extraire le texte d'une page :
text = pdf_page_1.extractText()
print(text[:500])
>> '1Boeing Reports Fourth-Quarter ResultsFourth Quarter 2019 Financial results continue to be significantly impacted by the 737 MAX grounding Revenue of $17.9 billion, GAAP loss per share of ($1.79) and core (non-GAAP)* loss per share of ($2.33) Full-Year 2019 Revenue of $76.6€billion, GAAP loss per share of ($1.12) and core (non-GAAP)* loss per share of ($3.47) Operating cash flow of ($2.4)€billion; cash and marketable securities of $10.0 billion Total backlog of $463 billion, including over 5,400'- Fusionner des documents page par page :
new_pdf = PdfFileWriter()
new_pdf.addPage(pdf_page_1)
new_pdf.addPage(pdf_page_4)
new_pdf.write(open("new_pdf.pdf", "wb"))
print(new_pdf)
>> <PyPDF2.pdf.PdfFileWriter object at 0x11e23cb10>- Cropper des pages :
print("Upper Left: ", pdf_page_1.cropBox.getUpperLeft())
print("Lower Right: ", pdf_page_1.cropBox.getLowerRight())
x1, y1 = 0, 550
x2, y2 = 612, 320
cropped_page = pdf_page_1
cropped_page.cropBox.upperLeft = (x1, y1)
cropped_page.cropBox.lowerRight = (x2, y2)
cropped_pdf = PdfFileWriter()
cropped_pdf.addPage(cropped_page)
cropped_pdf.write(open("cropped.pdf", "wb"))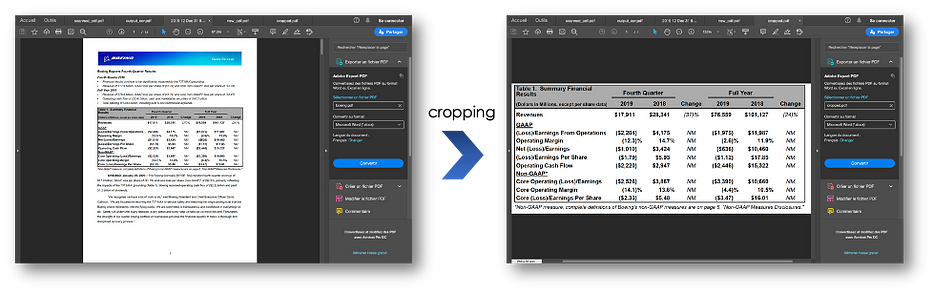
- Chiffrer et déchiffrer des fichiers PDF :
PASSWORD = "password_123"encrypted_pdf = PdfFileWriter()encrypted_pdf.addPage(pdf_page_1)encrypted_pdf.encrypt(PASSWORD)encrypted_pdf.write(open("encrypted_pdf.pdf", "wb"))read_encrypted_pdf = PdfFileReader(open("encrypted_pdf.pdf", "rb"))print(read_encrypted_pdf.isEncrypted)if read_encrypted_pdf.isEncrypted: read_encrypted_pdf.decrypt(PASSWORD)print(read_encrypted_pdf.documentInfo)>> True>> {'/Producer': 'PyPDF2'}
Pour plus d'informations sur PyPDF2, veuillez consulter le site officiel.
2. PDF2IMG
PDF2IMG est une librairie Python qui permet de transformer des pages PDF en images pouvant ensuite être traitées, par exemple par des algorithmes de computer vision.
PDF2IMG peut être installé avec pip en exécutant la ligne de commande suivante :
pip install pdf2imageOn peut définir la première page et la dernière page à transformer en images depuis le fichier PDF.
from pdf2image import convert_from_path
import matplotlib.pyplot as plt
page=0
img_page = convert_from_path(PDF_PATH, first_page=page, last_page=page+1, output_folder="./", fmt="jpg")
print(img_page)
>> <PIL.PpmImagePlugin.PpmImageFile image mode=RGB size=1700x2200 at 0x11DF397D0>
3. Camelot
Camelot est une librairie Python spécialisée dans le parsing de tableaux dans les pages PDF. Elle peut être installée avec pip en exécutant la ligne de commande suivante :
pip install camelot-py[cv]La sortie du parsing est un pandas dataframe, ce qui est très utile pour le traitement des données.
import camelot
output_camelot = camelot.read_pdf(
filepath="output_ocr.pdf", pages=str(0), flavor="stream"
)
print(output_camelot)
table = output_camelot[0]
print(table)
print(table.parsing_report)
>> TableList n=1>
>> <Table shape=(18, 8)>
>> {'accuracy': 93.06, 'whitespace': 40.28, 'order': 1, 'page': 0}Lorsque la page PDF contient du texte, la sortie de Camelot sera un dataframe contenant du texte dans les premières colonnes, puis plus loin le tableau souhaité. Avec un traitement basique, on peut l'extraire comme suit :
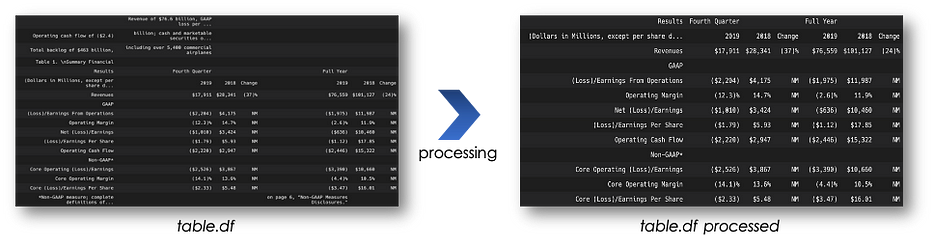
Camelot propose deux flavors, lattice et stream. Je conseille d'utiliser stream car il est plus flexible vis-à-vis de la structure des tableaux.
4. Camelot couplé à YOLOV3
Camelot offre la possibilité de spécifier les régions à traiter via la variable table_areas="x1,y1,x2,y2" où (x1, y1) est le coin supérieur gauche et (x2, y2) le coin inférieur droit dans l'espace de coordonnées du PDF. Lorsque renseignée, le résultat du parsing est significativement amélioré.
Explication de l'idée de base
Une façon d'automatiser le parsing des tableaux est d'entraîner un algorithme capable de renvoyer les coordonnées des bounding boxes encadrant les tableaux, comme détaillé dans le pipeline suivant :

Si la page PDF d'origine est basée sur des images, on peut utiliser ocrmypdf pour la transformer en page basée sur du texte afin de pouvoir récupérer le texte à l'intérieur du tableau. On effectue ensuite les opérations suivantes :
- Transformer une page PDF en image avec
pdf2img - Utiliser un algorithme entraîné pour détecter les régions des tableaux.
- Normaliser les bounding boxes en utilisant la dimension de l'image, ce qui permet d'obtenir les régions dans l'espace PDF à partir des dimensions du pdf obtenues via
PyPDF2. - Fournir les régions à
camelotet récupérer les pandas dataframes correspondants.
Lorsqu'on détecte un tableau dans une image PDF, on agrandit la bounding box pour garantir son inclusion complète, comme suit :
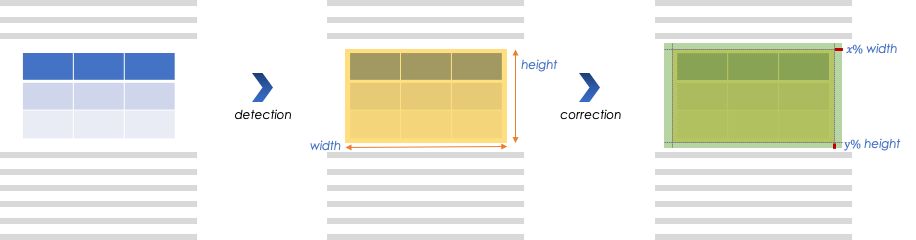
Détection des tableaux
L'algorithme qui permet la détection des tableaux n'est autre que yolov3 ; je vous conseille de lire mon précédent article sur la détection d'objets.
Nous fine-tunons l'algorithme pour détecter les tableaux et réentraînons toute l'architecture. Pour cela, nous suivons les étapes suivantes :
- Créer un dataset d'entraînement avec
Makesense, un outil qui permet de labelliser et d'exporter au format YOLO :
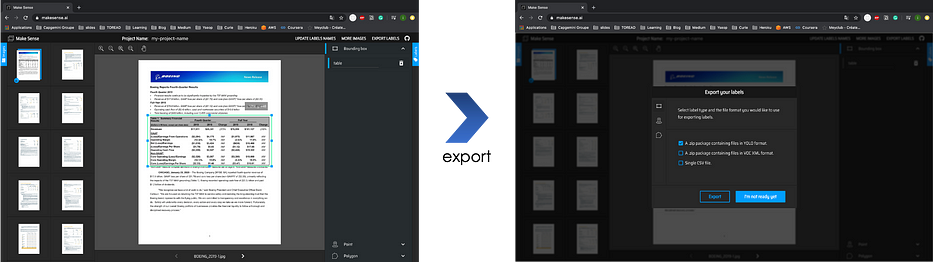
- Entraîner un
yolov3repositorymodifié pour répondre à notre besoin sur AWS EC2 ; on obtient les résultats suivants :
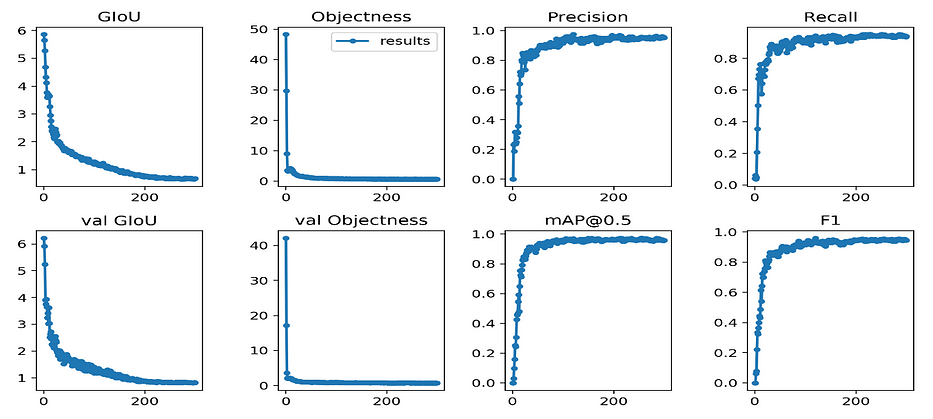
Illustration
Les détections se présentent comme suit :

Conclusion
En combinant les librairies Python standards avec un algorithme de deep learning, il est possible d'améliorer significativement le parsing des documents PDF. Concrètement, en suivant les mêmes étapes, on peut entraîner l'algorithme YOLOV3 à détecter n'importe quel autre objet dans une page PDF, comme des graphiques et des images, qui peuvent être extraits de la page-image.
Vous pouvez consulter mon projet sur mon GitHub.
N'hésitez pas à consulter mes précédents articles qui traitent de :
- Les mathématiques du Deep Learning
- Les mathématiques des Convolutional Neural Networks
- Algorithmes de détection d'objets & de reconnaissance faciale
- Les Recurrent Neural Networks