
Les pipelines RAG, pour Retrieval Augmented Generation, sont aujourd'hui l'une des applications les plus connues et tendance des LLMs. L'idée principale est de répondre à une question à partir d'une ou plusieurs sources d'information (PDF, Excel, Drive, SharePoint, …) en s'appuyant sur les capacités de raisonnement du large language model, dont la base de connaissances a une date de coupure.
La question peut être :
- Objective : vrai-faux, choix multiple, mots/nombre exacts …, principalement utilisée dans les pipelines d'extraction de points clés.
- Subjective : paragraphe court ou détaillé, utilisée dans les use cases de Q&A en général
Dans cet article, nous allons parcourir les différentes étapes de la construction d'un pipeline RAG vanilla, puis l'améliorer en y branchant des modules additionnels liés à la fois au retriever et au generator (voir section suivante).
Dans le prochain, nous couvrirons l'évaluation du pipeline RAG selon une approche TDD (Test Driven Development) et MDD (Metric Driven Development).
Le sommaire est le suivant :
- RAG Pipeline
- Amélioration
RAG Pipeline
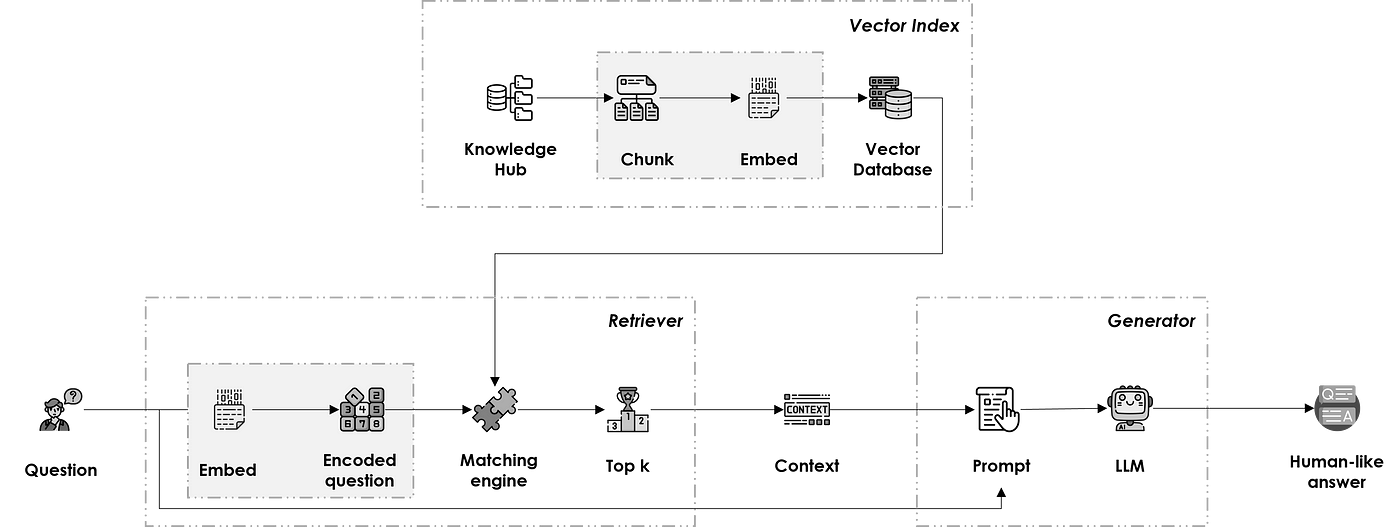
Le pipeline RAG est composé de trois composants principaux : Vector Index, Retriever et Generator.
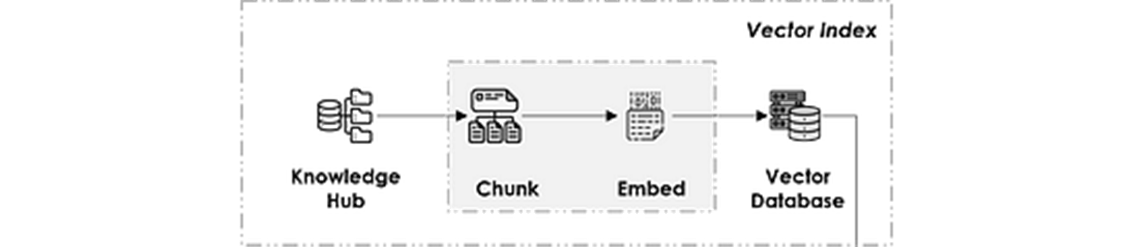
Vector Index
Il représente le hub de connaissances depuis lequel l'information est extraite. Il est construit en suivant les étapes ci-dessous :
- Collecte des données
- Nettoyage des données : selon le simple principe « garbage in, garbage out »
- Chunking des données : découpage des données en petites sections (par page ou paragraphe par exemple) car le LLM ne peut ingérer qu'un nombre déterminé de tokens, connu sous le nom de context size.
- Embedding des données : qui transforme le texte en une représentation vectorielle sémantique pour un matching ultérieur, à l'aide d'un modèle d'embedding (Openai ada-002 étant le plus connu).
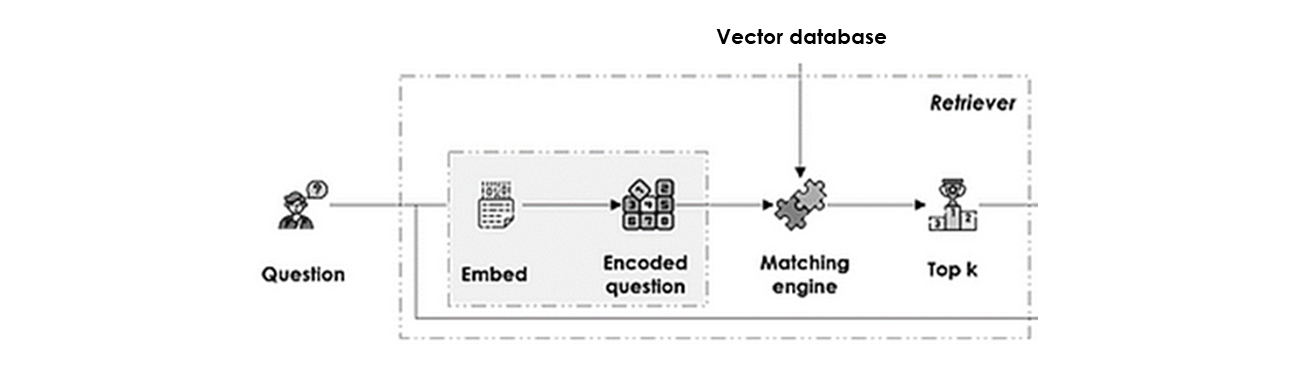
Retriever
Il associe la question au bon chunk du hub de connaissances en :
- Encodage de la question : pour représenter la question dans le même espace vectoriel que les données sources, en utilisant le même modèle d'embedding.
- Matching sémantique : entre l'embedding de la question et le vector index, à l'aide de la métrique de similarité cosinus par exemple, et renvoie les top k contextes les plus similaires.
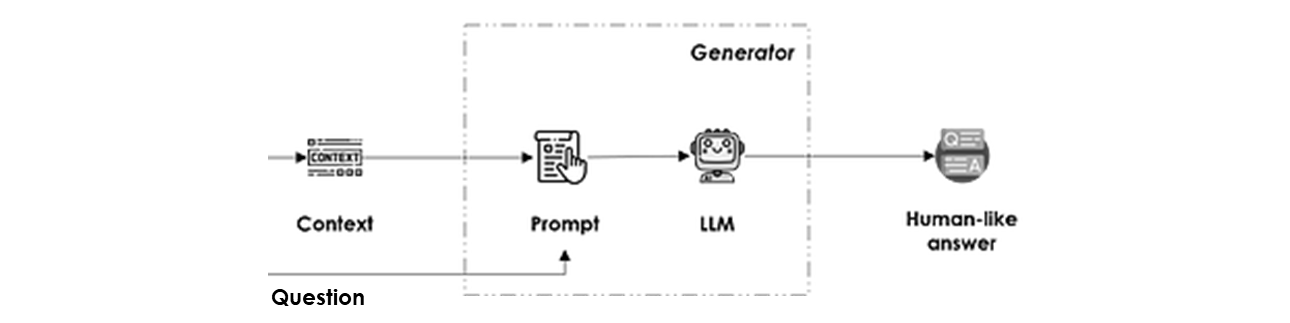
Generator
Il renvoie une réponse de type humain à la question, à partir du contexte sélectionné, en deux étapes successives :
- Génération du prompt : cette étape consiste à créer un ensemble d'instructions afin de tirer pleinement parti des capacités de raisonnement du LLM, en spécifiant explicitement la question et le contexte depuis lequel l'information doit être extraite. Elle sert aussi à déterminer le ton/style du langage généré ainsi que le format attendu de la sortie (texte, json, yaml, …).
On peut également ajouter les n dernières interactions historiques entre l'utilisateur et le système pour les dialogues de chat, à condition que ces interactions tiennent dans la fenêtre de contexte. - Complétion LLM : autrement dit la sortie de l'inférence du LLM sur le prompt généré
Amélioration
Le pipeline RAG vanilla décrit ci-dessus peut souffrir de plusieurs problèmes : précision/rappel faibles au niveau du retrieval, hallucinations au niveau du generator, …etc.
Pour atténuer les risques ci-dessus, plusieurs étapes peuvent être ajoutées au pipeline afin d'assurer une meilleure récupération de l'information et une meilleure génération de réponses.
Vector Indexing
- Parsing modulaire : du texte, des tableaux et des images
- Optimiser la stratégie de chunking : chunking personnalisé par section, sous-section, …
- Optimiser la structure de l'index : en ajoutant une hiérarchie
- Métadonnées additionnelles : décrivant le contenu des sections. Effectuer le matching sur ces métadonnées en premier peut être un bon filtre de bruit.
Retriever
- Réécriture de la question : pour corriger la structure grammaticale de la question, étant donné que la plupart des modèles d'embedding ont été entraînés sur des données propres. Cela aide aussi à aligner la question avec la structure de langage du LLM.
- Fine-tuning de l'embedding : qui peut être très utile lorsqu'on traite des contextes très spécialisés à un domaine
- Utilisation d'embeddings dynamiques : où le vecteur généré dépend de l'instruction additionnelle fournie au modèle d'embedding
- Reranking : Diversity Ranker, Lost in the Middle Ranker par exemple. Cette technique s'est avérée très efficace pour améliorer la précision du retrieval
- Retrieval hybride : BM25 & embedding pour les use cases où les mots-clés comptent
- Compression du prompt : supprimer le bruit du texte récupéré et conserver l'essence de l'information nécessaire du chunk. Ce faisant, on réduit également la taille du contexte et on permet de traiter plus d'information dans la même fenêtre de contexte.
Generation
- Prompt engineering : c'est l'art de concevoir un prompt qui répond au niveau attendu de sortie
- LLMs open-source fine-tunés : une tâche lourde qui nécessite de construire un dataset (généralement avec question, contexte et réponse) pour fine-tuner le modèle de langage entraîné. Cette méthodologie lui permet de capter à la fois le style et la connaissance issus du training set.
Conclusion
Le RAG est aujourd'hui une architecture très populaire et puissante au vu de ses bénéfices significatifs. Il peut facilement être étendu à davantage de connaissances et donc s'adapter aux éventuels changements de version dans l'existant. Il peut aussi s'adapter à plusieurs types de données et de requêtes en s'appuyant sur le concept d'agents.
Les agents peuvent être considérés comme plusieurs opérateurs spécialisés dans une tâche ou un domaine, ce qui les rend plus précis, et qui interviennent lorsque nécessaire à travers une routing chain of thoughts.
Dans le prochain article, nous discuterons de l'évaluation du pipeline RAG et des différents frameworks qui peuvent être mobilisés à cette fin.