
Les recurrent neural networks sont des deep learning networks très connus qui sont appliqués aux données séquentielles : prévision de séries temporelles, reconnaissance vocale, classification de sentiments, traduction automatique, Named Entity Recognition, etc.
L'utilisation des feedforward neural networks sur des données séquentielles soulève deux problèmes majeurs :
- Les inputs & outputs peuvent avoir des longueurs différentes selon les exemples
- Les MLPs ne partagent pas les features apprises entre les différentes positions de l'échantillon
Dans cet article, nous découvrirons les mathématiques derrière le succès des RNNs ainsi que certains types spéciaux de cellules tels que les LSTMs et les GRUs. Nous explorerons enfin les architectures encoder-decoder combinées aux attention mechanisms.
NB : Medium ne supportant pas LaTeX, les expressions mathématiques sont insérées sous forme d'images. Je vous conseille donc de désactiver le mode sombre pour une meilleure expérience de lecture.
Le sommaire est le suivant :
- Notation
- Modèle RNN
- Différents types de RNNs
- Types de cellules avancés
- Architecture Encoder & Decoder
- Attention mechanisms
Notation
À titre d'illustration, nous considérerons la tâche de Named Entity Recognition qui consiste à localiser et identifier l'entité nommée, comme les noms propres :

Nous notons :

Lorsque l'on traite des données non numériques, du texte par exemple, il est très important de l'encoder en vecteurs numériques : cette opération est appelée embedding. L'une des façons les plus connues d'encoder du texte est Bert, développé par Google.
Modèle RNN
Les RNNs représentent un cas particulier de neural networks où les paramètres du modèle, ainsi que les opérations effectuées, sont les mêmes tout au long de l'architecture. Le réseau effectue la même tâche pour chaque élément d'une séquence dont la output depends on the input and the previous state of the memory.
Le graphe ci-dessous montre un neural network de neurones ayant une seule couche de mémoire cachée :
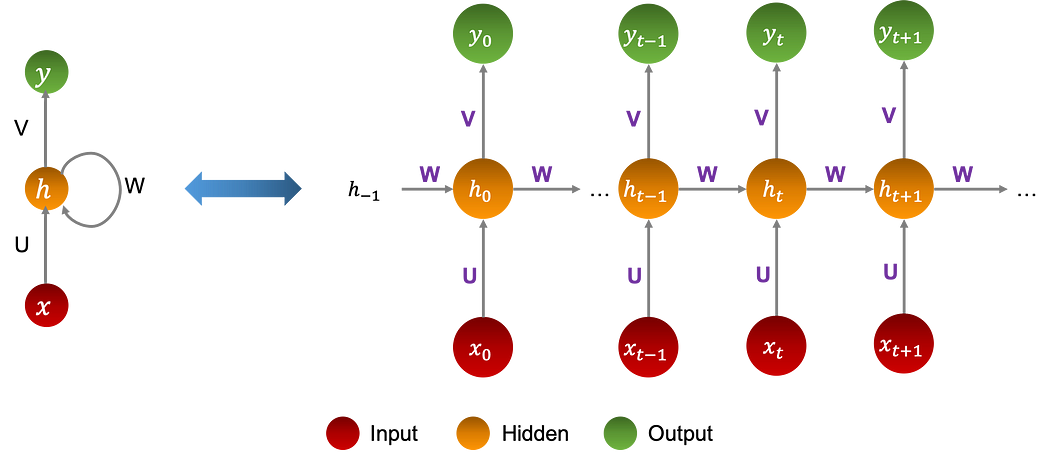
Équations
Les variables de l'architecture sont :

où :
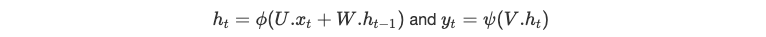
h(−1) est initialisé aléatoirement, ϕ et ψ sont des fonctions non-linéaires, U, V, et W sont les parameters des différentes régressions linéaires, précédant les activations non-linéaires.
Il est important de noter qu'ils sont les mêmes tout au long de l'architecture.
Applications
Les recurrent neural networks ont considérablement amélioré les modèles séquentiels, en particulier :
- Tâches de NLP, modélisation et génération de texte
- Traduction automatique
- Reconnaissance vocale
Nous résumons les applications ci-dessus dans le tableau suivant :
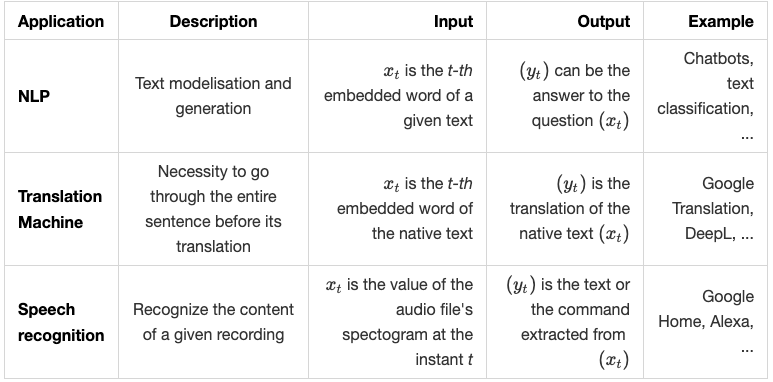
Algorithme d'apprentissage
Comme dans les neural networks classiques, l'apprentissage dans le cas des réseaux récurrents se fait en optimisant une cost function par rapport à U, V et W. En d'autres termes, nous cherchons à trouver les meilleurs paramètres qui donnent la meilleure prédiction y^i, à partir de l'input xi, de la valeur réelle yi.
Pour cela, nous définissons une fonction objectif appelée loss function et notée J qui quantifie la distance entre les valeurs réelles et prédites sur l'ensemble du training set.
Nous minimisons J en suivant deux étapes majeures :
Forward Propagation: nous propageons les données à travers le réseau soit entièrement soit par batches, et nous calculons la loss function sur ce batch qui n'est autre que la somme des erreurs commises à la prédiction de sortie pour les différentes lignes.Backward Propagation Through Time: consiste à calculer les gradients de la cost function par rapport aux différents paramètres, puis à appliquer un algorithme de descente pour les mettre à jour. On l'appelle BPTT, car les gradients à chaque sortie dépendent à la fois des éléments du même instant et de l'état de la mémoire à l'instant précédent.
Nous itérons le même processus un certain nombre de fois appelé epoch number. Après avoir défini l'architecture, l'algorithme d'apprentissage s'écrit comme suit :

(∗) La cost function L évalue les distances entre la valeur réelle et prédite sur un seul point.
Forward propagation
Considérons la prédiction de la sortie d'une seule séquence à travers le neural network.
À chaque instant t, nous calculons :
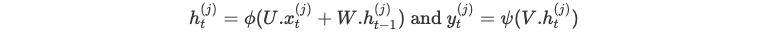
Jusqu'à atteindre la fin de la séquence.
Encore une fois, les paramètres U, W et V restent les mêmes tout au long du neural network.
Lorsque l'on traite un dataset de m lignes, répéter ces opérations séparément pour chaque ligne est très coûteux. Nous tronquons donc le dataset afin d'avoir des séquences décrites dans la même chronologie, c'est-à-dire :
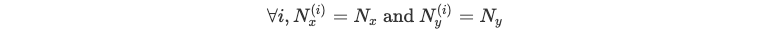
Nous pouvons utiliser l'algèbre linéaire pour paralléliser comme suit :
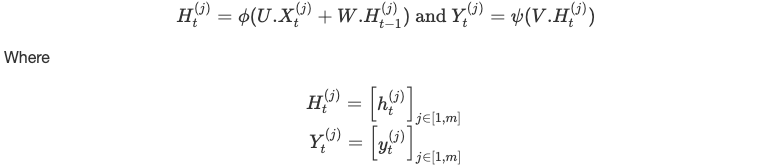
Backpropagation Through Time
La backpropagation est la deuxième étape de l'apprentissage, qui consiste à injecting the error commise dans la phase de prédiction (forward) dans le réseau et à mettre à jour ses paramètres pour perform better on the next iteration. D'où l'optimisation de la fonction J, généralement via une méthode de descente.

Nous pouvons maintenant appliquer une méthode de descente comme détaillée dans mon article précédent.
Problème de mémoire
Il existe plusieurs domaines où l'on s'intéresse à prédire l'évolution d'une série temporelle en fonction de son historique : musique, finance, émotions, etc.
Les réseaux récurrents intrinsèques décrits ci-dessus, appelés 'Vanilla', souffrent d'une mémoire faible incapable de prendre en compte plusieurs éléments du passé dans la prédiction du futur.
Dans cette optique, diverses extensions des RNNs ont été conçues pour affiner la mémoire interne : neural networks bi-directionnels, cellules LSTM, attention mechanisms, etc. L'élargissement de la mémoire peut être crucial dans certains domaines comme la finance où l'on cherche à mémoriser autant d'historique que possible afin de prédire une série financière.
La phase d'apprentissage des RNN peut également souffrir de problèmes de gradient vanishing ou gradient exploding car le gradient de la cost function inclut la puissance de W qui affecte sa capacité de mémorisation.
Différents types de RNNs
Il existe plusieurs extensions pour les recurrent neural networks classiques ou 'Vanilla', ces extensions ont été conçues pour augmenter la capacité de mémoire du réseau ainsi que la capacité d'extraction des features.
L'illustration ci-dessous résume les différentes extensions :
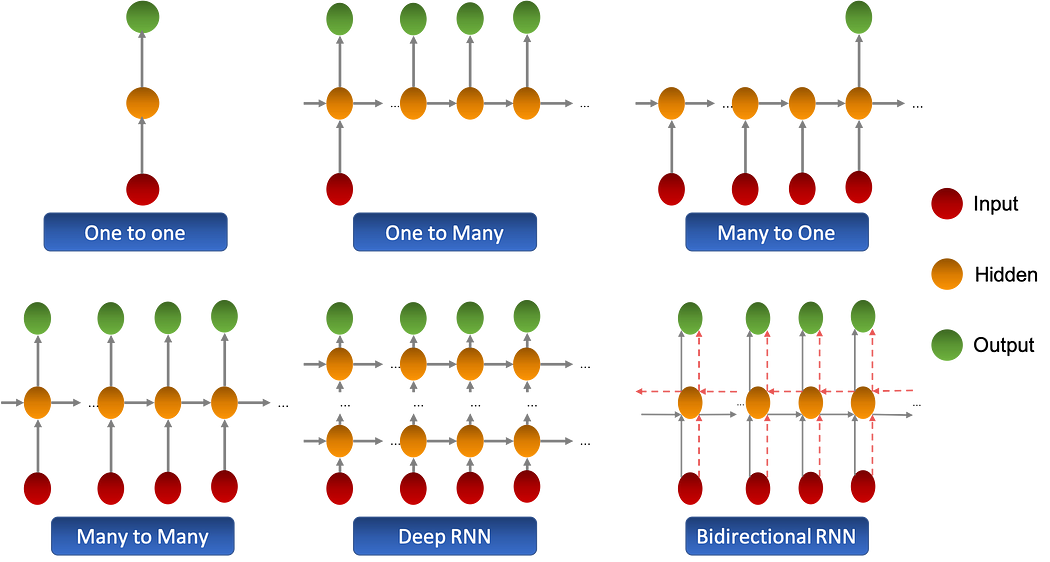
Il existe d'autres types de RNNs ayant une couche cachée spécifiquement conçue, dont nous discuterons dans le chapitre suivant.
Types de cellules avancés
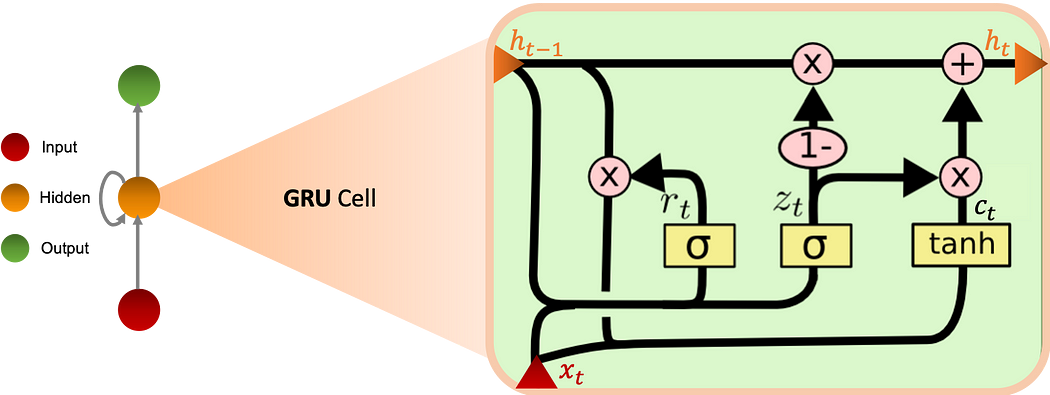
Gated Recurrent Unit
Les cellules GRU (Gated Recurrent Unit) permettent au réseau récurrent de sauvegarder davantage d'informations historiques pour une meilleure prédiction. Elles introduisent une update gate qui détermine la quantité d'informations à conserver du passé ainsi qu'une reset gate qui définit la quantité d'informations à oublier.
Le graphe ci-dessous schématise la cellule GRU :
Équations
Nous définissons les équations de la cellule GRU comme suit :
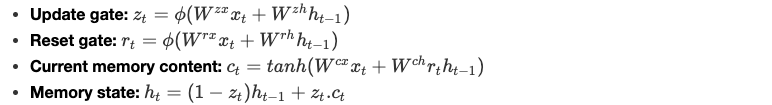
ϕ est une fonction entière non-linéaire et les paramètres W sont appris par le modèle.
Long Short Term Memory
Les LSTMs (Long Short Term Memory) ont également été introduits pour pallier le problème de mémoire courte, ils ont 4 fois plus de mémoire que les RNNs Vanilla. Ce modèle utilise la notion de gates et en compte trois :
- Input gate i : contrôle le flux d'informations entrantes.
- Forget gate f : Contrôle la quantité d'informations provenant de l'état précédent de la mémoire.
- Output gate o : contrôle le flux d'informations sortantes
Le graphe ci-dessous montre le fonctionnement de la cellule LSTM :
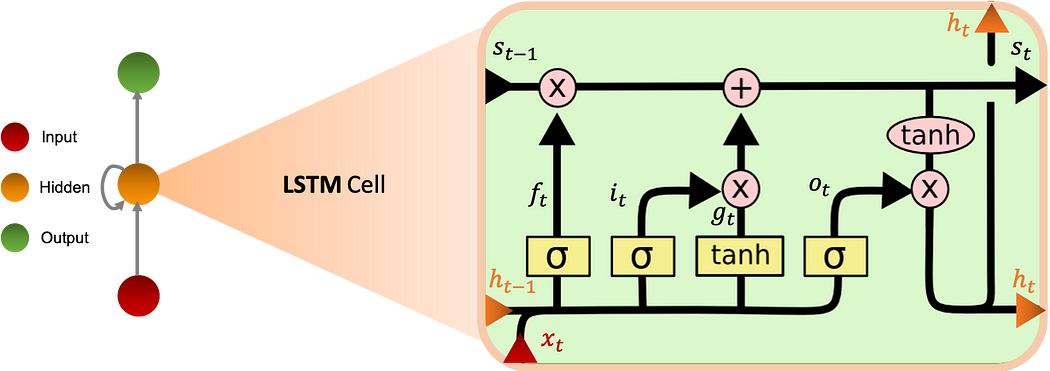
Lorsque les portes d'entrée et de sortie sont fermées, l'activation est bloquée dans la cellule mémoire.
Équations
Nous définissons les équations de la cellule LSTM comme suit :
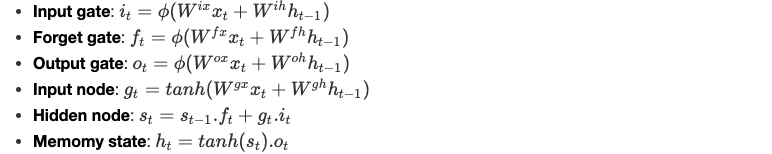
Pros & Cons
Nous pouvons résumer les avantages et inconvénients des cellules LSTM en 4 points principaux :
- Avantages
+ Elles sont capables de modéliser les dépendances de séquences longues.
+ Elles sont plus robustes face au problème de mémoire courte que les RNNs 'Vanilla' puisque la définition de la mémoire interne est modifiée de :
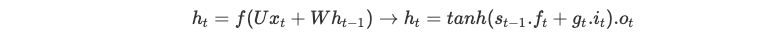
- Inconvénients
+ Elles augmentent la complexité de calcul par rapport au RNN avec l'introduction de plus de paramètres à apprendre.
+ La mémoire requise est plus élevée que celle des RNNs 'Vanilla' en raison de la présence de plusieurs cellules mémoires.
Architecture Encoder & Decoder
Il s'agit d'un modèle séquentiel composé de deux parties principales :
Encoder: la première partie du modèle traite la séquence puis renvoie à la fin un vecteur d'encodage de l'ensemble de la série appelécontext vectorqui résume les informations des différentes entrées.Decoder: le context vector est ensuite pris comme entrée du decoder afin d'effectuer les prédictions.
Le diagramme ci-dessous illustre l'architecture du modèle :
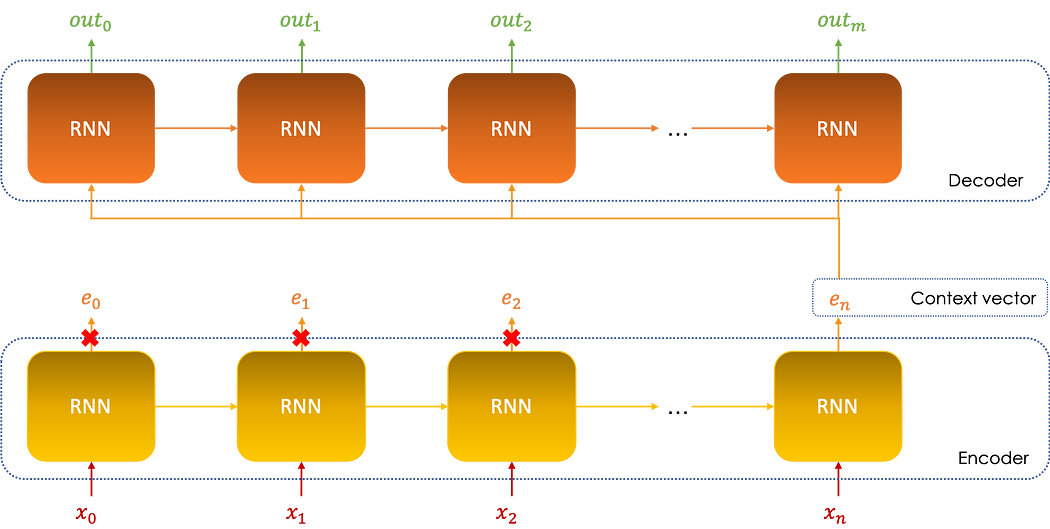
L'encoder peut être considéré comme un outil de réduction de dimension : en effet, le context vector en n'est rien d'autre que l'encodage des vecteurs d'entrée (in0,in1,…inn), la somme des tailles de ces vecteurs étant bien plus grande que celle de en, d'où la notion de réduction de dimension.
Attention mechanisms
Les attention mechanisms ont été introduits pour résoudre le problème de la limitation de mémoire, et répondent principalement aux deux questions suivantes :
- Quel poids (importance) αj est attribué à chaque sortie ej de l'encoder ?
- Comment dépasser la mémoire limitée de l'encoder afin de pouvoir 'se souvenir' davantage du processus d'encodage ?
Le mécanisme s'insère entre l'encoder et le decoder et aide le decoder à sélectionner de manière significative les entrées encodées qui sont importantes pour chaque étape du processus de décodage outi comme suit :
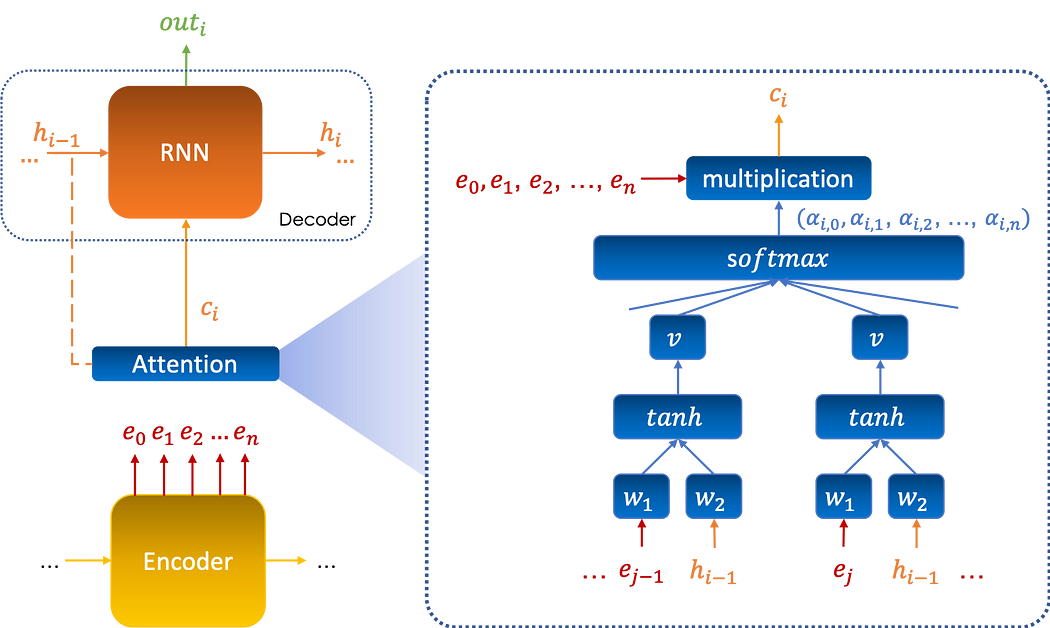
Formalisme mathématique
En gardant la même notation qu'auparavant, nous définissons αi,j comme l'attention accordée par la sortie i, notée outi, au vecteur ej.
L'attention est calculée via un neural network qui prend comme entrées les vecteurs (e0,e1,…,en) et l'état précédent de la mémoire h(i-1), elle est donnée par :

Application : Traduction automatique
L'utilisation d'un attention mechanism permet de visualize and interpret ce que le modèle fait en interne, en particulier au moment de la prédiction.
Par exemple, en traçant une 'heatmap' de la matrice d'attention d'un système de traduction, nous pouvons voir les mots de la première langue sur lesquels le modèle se concentre pour traduire chaque mot dans la seconde langue :
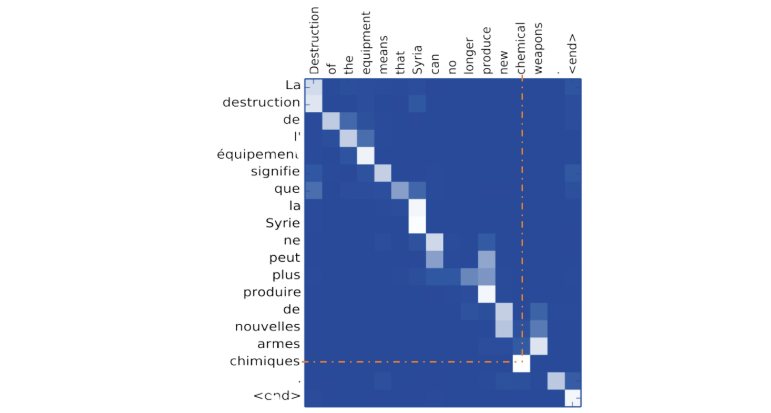
Comme illustré ci-dessus, lors de la traduction d'un mot en anglais, le système se concentre en particulier sur le mot français correspondant.
Superposition de LSTM & Attention Mechanism
Il est pertinent de combiner les deux méthodes pour améliorer la mémoire interne, puisque la première permet de prendre en compte plus d'éléments du passé et la seconde choisit d'y prêter une attention particulière au moment de la prédiction.
La sortie ct de l'attention mechanism est la nouvelle entrée de la cellule LSTM, donc le système d'équations devient comme suit :
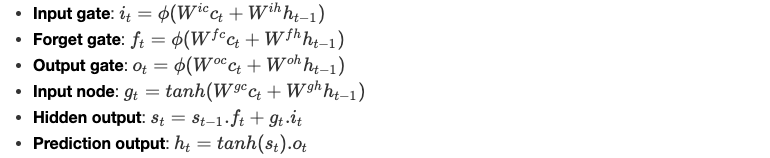
ϕ est une fonction entière non-linéaire et les paramètres W sont appris par le modèle.
Conclusion
Les RNNs sont un outil très puissant pour traiter les données séquentielles, ils offrent des capacités de mémorisation incroyables et sont largement utilisés au quotidien.
Ils disposent également de nombreuses extensions qui permettent de traiter divers types de problèmes data-driven, plus particulièrement ceux concernant les séries temporelles.
N'hésitez pas à consulter mes articles précédents traitant de :
- Les mathématiques du Deep Learning
- Les mathématiques des Convolutional Neural Networks
- Algorithmes de détection d'objets & reconnaissance faciale
Références
- Z.Lipton, J.Berkowitz, C.Elkan, A Critical Review of Recurrent Neural Networks for Sequence Learning, arXiv: 1506.00019v4, 2015.
- H.Salehinejad, S.Sankar, J.Barfett, E.Colak, S.Valaee, Recent Advances in Recurrent Neural Networks, arXiv: 1801.01078v3, 2018.
- Y.Baveye, C.Chamaret, E.Dellandréa, L.Chen, Affective Video Content Analysis: A Multidisciplinary Insight, HAL Id: hal-01489729, 2017.
- A.Azzouni, G.Pujolle, A Long Short-Term Memory Recurrent Neural Network Framework for Network Traffic Matrix Prediction, arXiv: 1705.05690v3, 2017.
- Y.G.Cinar, H.Mirisaee, P.Goswami, E.Gaussier, A.Ait-Bachir, V.Strijov, Time Series Forecasting using RNNs: an Extended Attention Mechanism to Model Periods and Handle Missing Values, arXiv: 1703.10089v1, 2017.
- K.Xu, L.Wu, Z.Wang, Y.Feng, M.Witbrock, V.Sheinin, Graph2Seq: Graph to Sequence Learning with Attention-Based Neural Networks, arXiv: 1804.00823v3, 2018.
- Rose Yu, Yaguang Li, Cyrus Shahabi, Ugur Demiryurek, Yan Liu, Deep Learning: A Generic Approach for Extreme Condition Traffic Forecasting, Southern California university, 2017.