
Le panorama AI de 2023 a été massivement dominé par les Large Language Models, à commencer par l'apparition de ChatGPT fin 2022, qui a battu le record d'adoption technologique avec la base d'utilisateurs ayant la croissance la plus rapide.
Les Large Language Models sont un sous-ensemble de la GenAI, qui désigne les systèmes capables de générer du contenu, comme leur nom l'indique clairement, sous différents formats : tabulaire, texte, images, …etc. Les LLMs sont entraînés sur de grandes quantités de données textuelles, ce qui les rend très efficaces pour générer des réponses de type humain.
Dans cet article, je vais aborder la définition des LLMs, leur évolution et leurs applications, en mettant particulièrement l'accent sur les principaux concepts, du Pre-training et du fine-tuning jusqu'au prompt engineering.
Le sommaire est le suivant :
- LLMs
- Pre-training
- Fine-tuning
- Prompt engineering
- Applications
LLMs
Les LLMs sont des modèles de deep learning entraînés sur d'énormes quantités de données textuelles (300 milliards de mots ~ 570 Go pour ChatGPT) scrappées sur internet, leur permettant de capturer d'énormes patterns au sein des langues et de surpasser toutes les techniques et modèles existants de prédiction du mot suivant.
Les modèles de langage ont massivement évolué ces 5 dernières années à travers différentes architectures, comme le montre l'illustration ci-dessous :
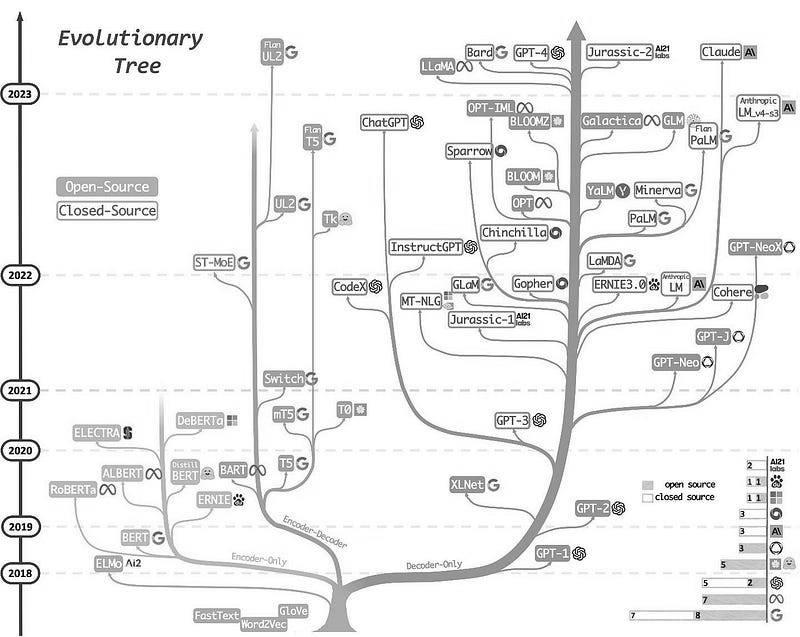
Où :
- Encoders : transforment une séquence de mots en une séquence de nombres (embeddings)
- Encoder-decoders : prennent du texte en entrée et génèrent une nouvelle séquence de mots en sortie (la traduction par exemple)
- Decoders : génèrent du texte en sortie à partir d'un contexte
Ces derniers modèles, les decoders, sont au centre de l'attention depuis 2020 grâce à leur architecture Transformers qui a débloqué des performances sans précédent à travers un apprentissage non supervisé massif, de grandes quantités de données textuelles et des couches profondes (GPT-1, 117 millions de paramètres). Les paramètres font référence aux weights et biases appris par le réseau de neurones.
Ceci étant dit, pendant l'entraînement, les LLMs sont capables d'apprendre deux capacités principales :
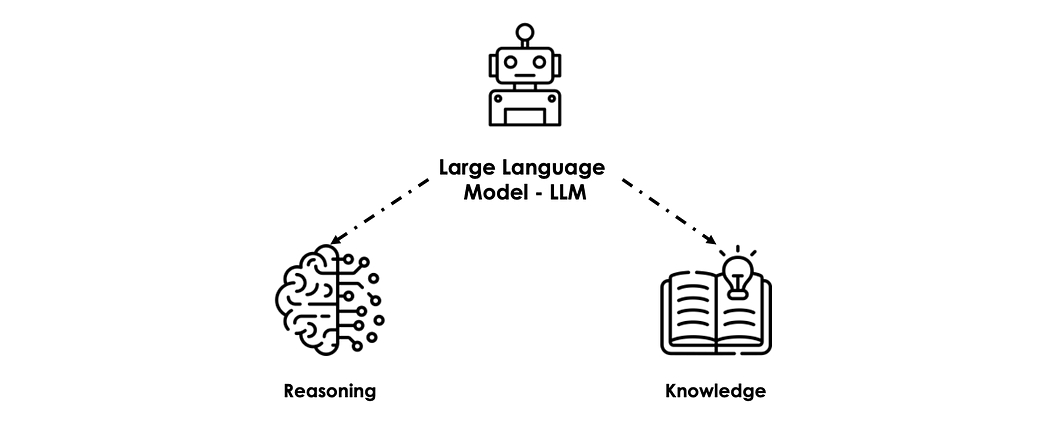
- Knowledge : issue de l'ensemble des informations et données sur lesquelles ils ont été entraînés. Par exemple, ChatGPT 3.5 dispose d'une base de connaissances scrappée à travers tout internet jusqu'en janvier 2022.

- Reasoning : capté à partir des différents patterns présents dans les données. Le LLM sera capable d'effectuer des tâches humaines classiques comme l'extraction d'information/insight, la résolution de problèmes, …etc.
Les LLMs entraînés sur de grands datasets de code (Github) montrent de meilleures capacités de reasoning, qui sont intuitivement des patterns et des logiques apprises à partir des langages de programmation.
Ils peuvent également être catégorisés en deux types de LLMs :
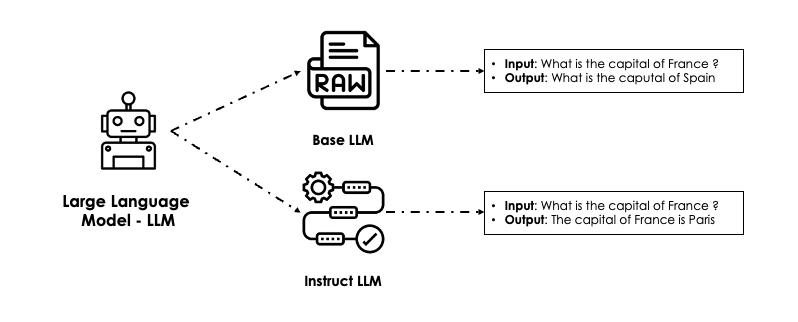
- Base LLM : la version « brute » du modèle, qui sert à la prédiction du mot suivant. Elle est obtenue par pre-training du modèle de deep learning (voir section Pre-training ci-dessous).
Par exemple, si vous posez la question « Quelle est la capitale de la France ? », le LLM produira probablement : « Quelle est la capitale de l'Espagne ? »
GPT3 est un base large language model. - Instruct LLM : une version fine-tunée (voir section Fine-tuning ci-dessous) habituellement entraînée sur un dataset de questions-réponses et qui sert principalement aux tâches de chat. Par exemple, ChatGPT est la version Instruct de GPT3.
Dans ce cas, à la même question que précédemment, le LLM répondra : « La capitale de la France est Paris ».
Comme mentionné ci-dessus, les LLMs sont entraînés à prédire le mot suivant, ce qui peut aussi les rendre par défaut sujets aux hallucinations, où le contenu généré est grammaticalement et sémantiquement correct mais ne reflète pas un fait réel.
C'est un trade-off entre objectivité et créativité, contrôlé par un hyperparamètre appelé temperature. L'hallucination peut être un problème sérieux, puisqu'elle propage de fausses informations et peut avoir des conséquences significatives selon l'usage du LLM.
Pre-training
Le pre-training est la tâche primaire d'entraînement du modèle de deep learning sur de vastes quantités de données textuelles, scrappées dans la plupart des cas sur internet. Le modèle apprend la structure du langage, sa grammaire et le bon sens contenu dans la langue. C'est la première étape d'apprentissage de l'architecture de deep learning. Il est crucial de nettoyer méticuleusement les données d'entraînement afin d'empêcher le modèle d'apprendre des informations biaisées.
Il convient aussi de mentionner que l'entraînement d'un Large Language Model est très coûteux en temps et en ressources/argent. Bien qu'il n'y ait pas de données officielles, on estime que GPT-4 a été entraîné sur 570 Go de données en utilisant 25 000 GPUs Nvidia A100 pendant environ 100 jours.
Compte tenu de la distribution des sujets et domaines au sein de l'ensemble des données d'internet, le LLM sera très probablement performant sur le langage général et aura plus de mal sur des tâches très spécialisées.
Fine-tuning
Le fine-tuning consiste à entraîner davantage le modèle afin d'améliorer sa Knowledge, son Reasoning, ou les deux. Il est utile lorsqu'on traite des tâches qui sont soit :
- Singulières : Q&A, résumé, … par exemple
- Spécifiques à un vocabulaire : médical, finance, …etc
Par exemple, ChatGPT a été obtenu par fine-tuning du base LLM GPT3.
Le dataset de fine-tuning est généralement structuré en deux formats principaux :
- 1ère structure : (Instruction, Input, Output), qui améliore intuitivement les capacités de reasoning du LLM.
- 2ème structure : (Input, Output), qui élargit ses connaissances
C'est un processus itératif qui offre de meilleures performances en augmentant la cohérence et la fiabilité du modèle, et en réduisant l'hallucination. C'est également bien moins coûteux que l'entraînement et cela permet plus de contrôle et de transparence sur la nouvelle connaissance.
Prompt Engineering
Les prompts servent d'entrées fournies à un Language Model (LLM) pour améliorer la qualité de sa sortie générée. Recourir aux prompts est une approche stratégique pour présenter un problème au LLM, en guidant son processus de réflexion et de raisonnement vers des résultats optimaux et précis. La technique de formulation des prompts est appelée prompt engineering.
Le prompt peut avoir la structure suivante :

où :
- Context : donnée textuelle optionnelle depuis laquelle l'information peut être extraite, elle sert aussi à définir le ton et le rôle/agent du LLM.
- Question : la requête à laquelle il faut répondre.
- Instructions : ce sont les étapes que le LLM doit suivre pour répondre à la question ; elles servent aussi à spécifier le format de la sortie, sa longueur, …etc.
Voici quelques principes de prompting :
- Instructions claires
- Vérifier que les conditions sont satisfaites
- Utiliser des délimiteurs
- Formater la sortie dans un format structuré (JSON, Markdown, …)
- Few-shots prompting : donner un échantillon de tuples (inputs, output) et requêter une nouvelle entrée - Processus de réflexion
- Spécifier les étapes à suivre pour la tâche de résolution de problème
- Demander au modèle d'élaborer sa propre solution avant de se précipiter vers une conclusion
Le prompting implique un processus itératif dans lequel on cherche à clarifier et raffiner les instructions pour obtenir de meilleurs résultats. C'est un effort dynamique et continu pour améliorer la guidance donnée au système afin d'obtenir des résultats plus efficaces.

Il est intéressant de noter que le choix entre prompt engineering, fine-tuning ou entraînement dépend principalement du cas d'usage et de ses exigences. Les données et ressources nécessaires augmentent en conséquence à mesure que l'on passe d'une tâche à l'autre.
Applications
Les LLMs ont trouvé des applications dans de nombreux domaines grâce à leur capacité à générer du contenu textuel dans un style très proche de l'humain. Le graphique ci-dessous résume certains des usages les plus connus des LLMs :
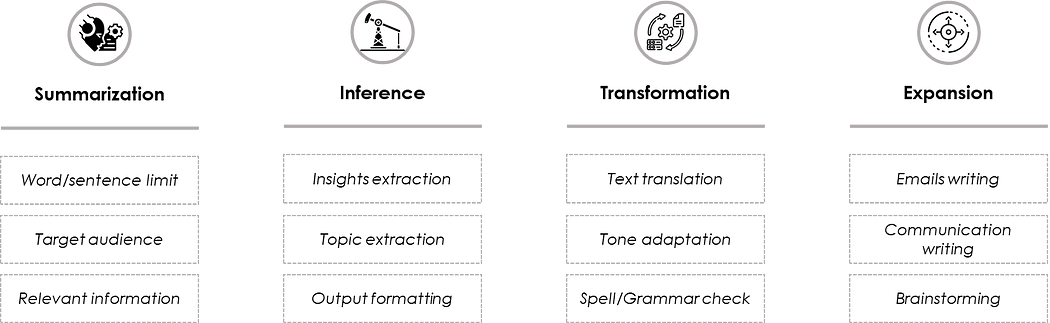
- Summarization : tâche consistant à réduire la taille de l'entrée textuelle, basée soit sur une limite de mots, une information ciblée, soit pour une audience spécifique.
- Inference : désigne la tâche d'extraction d'insights à partir du texte, avec la possibilité de spécifier le format de sortie.
- Transformation : peut mettre à jour/réécrire l'entrée ou même la traduire
- Expansion : l'une des features de gain de productivité les plus intéressantes des LLMs, permettant de générer des emails, des communications, et même des idées pour des sessions de brainstorming
Ces applications mettent en lumière le fort potentiel des LLMs et projettent l'impact qu'ils pourraient avoir au niveau technique sur les tâches de NLP, ce qui peut également se refléter au niveau métier compte tenu des nouvelles features et possibilités significatives qu'ils débloquent.
Conclusion
Les Large Language Models (LLMs) façonnent un nouveau paradigme dans notre approche des tâches de NLP, en affichant une flexibilité et une précision sans précédent. Ce domaine dynamique est marqué par une recherche et un développement continus, avec de nouveaux LLMs qui apparaissent régulièrement et qui sont classés presque chaque semaine.
2024 sera principalement l'année des small/nano LLMs qui tourneront sur de petits appareils et se spécialiseront sur des tâches précises. Phi-2 et The Rabbit R1 sont autant de signes prometteurs de la tendance de cette année, et j'ai personnellement hâte de voir la suite !